CUDA, 用于大量数据的超级运算:第13节
http://www.ddj.com/architect/218100902
Rob Farber
Using texture memory in CUDA
Rob Farber 是西北太平洋国家实验室(Pacific Northwest National Laboratory)的高级科研人员。他在多个国家级的实验室进行大型并行运算的研究,并且是几个新创企业的合伙人。大家可以发邮件到[email protected]与他沟通和交流。
在关于CUDA的系列文章第12节CUDA,用于大量数据的超级运算: 里,我讨论了最新的CUDA Toolkit 2.2的一些范式改变特点。本文将继续讨论我早在该系列文章的第11节就涉及到的“纹理内存”。此外,本小节会涉及有关CUDA Toolkit 2.2新版本纹理能力的一些知识,程序员们可以通过提供向GPU上的全局内存(有2D纹理与之绑定)写入的能力,消除额外的拷贝。
从一个C语言程序员的角度来看,纹理内存不同寻常地将缓冲存储器(与寄存器,全局和共享内存分离),本地处理能力(与标量处理器),和与GPU显示能力互动的方式结合起来。本文的重点是纹理内存的缓冲和本地处理器能力,下一栏将讨论怎样使用GPU执行可视图形操作。
不要在使用纹理内存时分心,因为它具有不同的特点,有很多个选择。使用纹理内存可以针对频带受限延迟和迟慢受限延迟,提高性能。例如,有些程序可能通过对纹理内存缓冲区的恰当使用,超过潜在全局内存的最大理论内存带宽。基本上,纹理缓冲引用的延迟与DRAM相同,但是在一些特殊情况下,数据的传输会略低于100延迟周期。如在CUDA里一样,诸多线程的使用能隐藏内存读取延迟,不管纹理缓冲或全局内存是否被读取。
对CUDA程序员来说,关于将纹理内存做为缓冲使用的最突出的几点就是:它根据2D空间定位进行了优化,非常小(约8KB/多处理器),可通过持有在一个纹理内的warp访问附近区域内的所有线程,提供性能优势(参见Cache-Efficient Numerical Algorithms using Graphics Hardware)。来自论坛的另外一个建议就是:如果可能,就打包数据,因为单个的float4纹理读取比四个单独的float纹理读取要快。
要将一个随机访问数据结构巧妙地映射到纹理内存上,可以使用CUDA-EC软件执行。在CUDA代码里, NVIDIA 执行一个 Bloom filter(布隆过滤器)以测试集合成员。CUDA-EC软件可在http://cuda-ec.sourceforge.net/上免费下载。
CUDA Toolkit 2.2 引入了向GPU(有纹理与之绑定)上与线性内存绑定的2D纹理写入的能力。换言之,在纹理范围内的数据可以在GPU上运行的内核范围内更新。这个一个非常棒的特点,因为诸多的代码可以更好地利用纹理内存的缓冲行为,同时也消除拷贝。有个常见的样例就是,要求两个数据通道的计算:一个是用来计算值(如平均或最大),还有一个是用来更新数据。当更改数据范围或计算概率时,这些计算是常见的。使用可更新的纹理可以提高这些类型计算的速度。
针对诸多单通道计算(sasum, sdot,等等),cuBLAS库使用纹理内存。然而,对源代码的评论显示,纹理内存不应该用于短的向量或被直列的,有单元步幅和聚合行为的向量。(注册为NVIDIA开发人员的程序员可获得cuBLAS library 和 cuFFT)。
纹理缓存是每个TPC(线程处理集)的一部分。我这里讨论的是计算模式的运算。(在图形模式里,TPC是纹理运算集的意思)。每个TPC包含多个流多处理器和一个单纹理缓存。重要的是,在GTX200系列里,纹理缓存支持每个TPC三个SM(流多处理器),而G80/G92构架仅支持两个。
表1显示的是,在平行计算模式里,GeForce GTX 280 GPU的高阶视图。顶端基于硬件的线程调度表管理整个TPC的线程调度,包括纹理缓存和内存界面单元。标为“atomic”的指的是执行对内存进行独立性读/改/写操作的能力。如需了解更多信息,请参见GeForce GTX 200 GPU Technical Brief。
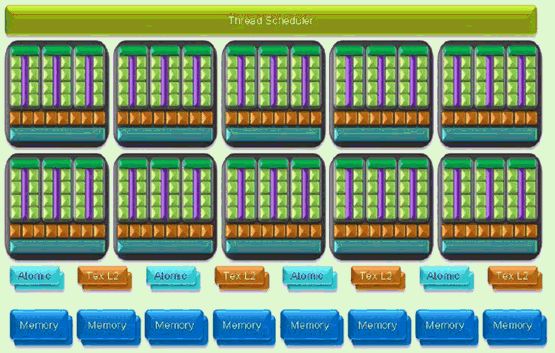
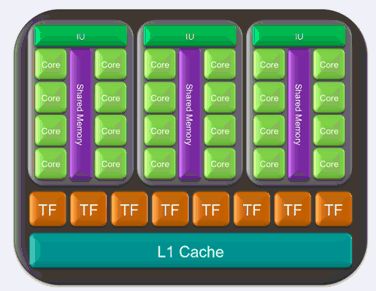
表 2 是单TPC较低阶的视图。注意,TF是指”纹理过滤”,IU是指令单元的缩写。
纹理与全局内存绑定,可提供缓存和一些处理能力。全局内存创建的方式决定了纹理可提供的一些能力。因此,区分三个内存类型(可与纹理绑定)非常重要:
线性内存
要区分用cudaMalloc() 创建的“线性内存”和用cudaMallocPitch()创建的“语音变化线性”内存,这非常重要。总而言之,两个方法都创建线性内存,但是cudaMallocPitch()可用来获得硬件内存子系统的最佳性能。程序员可使用cudaMalloc()创建内存,手动设置音高,但是可能不能获得最佳性能。除去更新的能力外,与2D CUDA数组绑定的纹理和音高线性内存之间无明显区别。NVIDIA 已说明与这两类内存绑定的纹理之间没有明显区别。
当将纹理与全局内存绑定时(因而必须区分音高线性内存和线性内存),要考虑两种情况:
当仅把纹理当作缓存时。在这个情况下,程序员可能考虑将纹理与使用cudaMalloc()绑定的线性内存绑定,因为纹理单元缓存很小,并且用cudaMallocPitch() 缓存填充就是一种浪费;
当使用纹理执行处理时。在这个情况下,将纹理与使用cudaMallocPitch()创建的音高线性内存绑定起来,这样纹理单元边界处理就会正确运作。换言之,不要把使用cudaMalloc() 创建的线性内存(且手动设置音高)与纹理绑定,因为可能会有期待不到的事情发生。
总体来说,推荐使用cudaMallocPitch() ,因为它“知道”对某个硬件来说哪个音高可以获得最佳性能,并且是验证你代码的最好方式。
还需要注意的是,CUDA数组是一个不透明数据存储 机制,由元素组成,每个元素由1,2或4个组件(可能是签字或未签字的8-, 16- 或32-字节整型,16字节浮点(仅指CUDA驱动器),或32字节浮点)。你还可以使用int2 和 hiloint2double 以利用双精度值。注意,CUDA数组可能重新安排在GPU上的定位。
将内存与纹理绑定起来非常快,不太可能对程序性能产生可察觉的影响。有一些限制条件和额外的告诫:
更新支持纹理缓存的内存直到下一个内核调用时才可见。
换言之,线程可以安全地通过纹理读取一些内存位置,但是仅仅是在该内存位置被之前的内核调用或内存拷贝更新的。如果它之前被同一线程或其它来自同一内核调用的线程更新,就不能读取内存位置。
将纹理与线性内存有效绑定阻止利用纹理进行纹理运算。相关文件的一个重要提示(编程指导的3.2.4.3节)是:纹理参照系域normalized, addressMode, 和 filterMode 可能在主代码里被修改,但是仅适用于与CUDA数组和音高线性内存绑定的纹理参照系。这就意味着与线性纹理绑定的纹理不能用来使用纹理单元执行纹理运算。
纹理内存不能与被映射的内存绑定。
注意,当与音高线性内存或CUDA数组绑定时,纹理缓存通过流行为为2D空间定位优化。然而,它没有告诉我们,当把纹理单元当作缓存时,怎样确定数据的次序以获得纹理单元的最佳性能。在讨论怎样确定3D数据的次序以获得最佳性能的CUDA ZONE论坛上,有个很“棒”的线索。其中一个建议就是,使用Z-order curve曲线以将多维数据映射到1D,同时保持位置。怎样为缓存位置最好地确定你的数据次序是一个具有挑战性的问题,并且会进一步复杂化,因为图形硬件使用的方法可能在未来有所改变,以更好地满足客户需求。
根据与纹理绑定的全局内存创建的方式,有几个方式可以从可能也会调用某个纹理运算格式的纹理上拾取。
从纹理拾取数据的最简单的方法就是:使用tex1Dfetch() ,因为:
仅支持整数地址;
没有提供额外的过滤或地址模式。
方法tex1D(), tex2D(), 和tex3D()的使用更为复杂,因为对纹理坐标的解释,在纹理拾取时会有怎样的运算,以及纹理拾取所传递的返回值都通过设定纹理参照系的易变(运行时间)和不变(编译时间)属性得以控制。
不变参数(编译时间)
类型:当拾取时,返回类型
基础整数和浮子式
CUDA 1-, 2-, 4-元素向量
维度::
现在是Currently 1D, 2D, 或3D
读取模式::
cudaReadModeElementType
cudaReadModeNormalizedFloat (对8- 或16-字节整数有效)
返回[-1,1] (以签字), [0,1] 未签字
易变参数 (运行时间,仅适用于数组纹理和音高线性内存)
规格化::
非零 = 地址范围[0, 1]
过滤模式
cudaFilterModePoint
cudaFilterModeLinear
地址模式
cudaAddressModeClamp
cudaAddressModeWrap
如需了解更多信息,请参阅CUDA Programming Guide.(CUDA编程指南)
在缺省状态下,在[0, N) 范围内(N是纹理大小,采用与坐标一致的维度),使用浮点坐标引用纹理。确定规格化纹理坐标会被使用,这意味着所有引用都在[0,1)范围内。
Wrap模式确定界外地址会发生什么情况:
Wrap: 界外座标被wrap(通过同余算法)
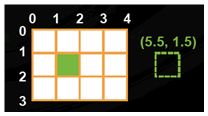
表3: Wrap 模式 (Courtesy NVIDIA)
钳制:界外座标被最近的界限代替
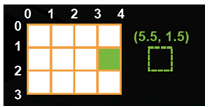
表 4: 钳制模式 (Courtesy NVIDIA)
仅在纹理被配置以返回浮点数据时,线性纹理过滤可能被执行。Texel(纹理元素)是纹理数组的一个元素。因此,线性纹理过滤执行低精度(9 字节固定-固定点与8字节分数值)插值(在相邻Texel之间)。当被启动时,纹理拾取位置周围的Texel被读取,纹理拾取的返回值被纹理硬件(基于Texel之间纹理座标下降的位置)以内插值替换。为单维纹理,简单的线性插值被执行,参见NVIDIA CUDA Programming Guide 2.2的附D2内的等式:
<textarea cols="50" rows="15" name="code" class="c-sharp">tex(x) = (1- α)T[i] + αT[i +1]</textarea>
等式 1:用于单维纹理的过滤模式
类似的,专用纹理硬件将为更高维度的数据执行双线性和三线性过滤。(如需了解更多信息,请查阅在线免费GPU Gems books, 及关于纹理过滤的维基百科文章)。
样例
让我们来看看下面这个非常简单的样例,readTexels.cu。它显示了怎样将纹理与CUDA数组绑定,将filterMode属性设置到cudaFilterModeLinear.
<textarea cols="50" rows="15" name="code" class="c-sharp">//readTexels.cu #include <stdio.h> void checkCUDAError(const char *msg) { cudaError_t err = cudaGetLastError(); if( cudaSuccess != err) { fprintf(stderr, "Cuda error: %s: %s./n", msg, cudaGetErrorString( err) ); exit(EXIT_FAILURE); } } texture<float, 1, cudaReadModeElementType> texRef; __global__ void readTexels(int n, float *d_out) { int idx = blockIdx.x*blockDim.x + threadIdx.x; if(idx < n) { //Note: Appendix D.2 gives formula for interpolation float x = tex1D(texRef, float(idx)); d_out[idx] = x; } } #define NUM_THREADS 256 int main() { int N = 10; // 10 is illustrative and should be larger in practice int nBlocks = N/NUM_THREADS + ((N % NUM_THREADS)?1:0); float *d_out; // allocate space on the device for the results cudaMalloc((void**)&d_out, sizeof(float) * N); // allocate space on the host for the results float *h_out = (float*)malloc(sizeof(float)*N); // data fill array with increasing values float *data = (float*)malloc(N*sizeof(float)); for (int i = 0; i < N; i++) data[i] = float(i); // create a CUDA array on the device cudaArray* cuArray; cudaMallocArray (&cuArray, &texRef.channelDesc, N, 1); cudaMemcpyToArray(cuArray, 0, 0, data, sizeof(float)*N, cudaMemcpyHostToDevice); // bind a texture to the CUDA array cudaBindTextureToArray (texRef, cuArray); // host side settable texture attributes texRef.normalized = false; texRef.filterMode = cudaFilterModeLinear; // read texels from texture readTexels<<<nBlocks, NUM_THREADS>>>(N, d_out); // copy texels to host cudaMemcpy(h_out, d_out, sizeof(float)*N, cudaMemcpyDeviceToHost); // look at them for (int i = 0; i << N; i++) { printf("%f/n",h_out[i]); } free(h_out); cudaFree(d_out); cudaFreeArray(cuArray); cudaUnbindTexture(texRef); checkCUDAError("cuda free operations"); } </textarea>
在Linux下,下面的nvcc指令列可被用来创建该程序:
<textarea cols="50" rows="15" name="code" class="c-sharp">nvcc readTexel.cu "o readTexel</textarea>
在主机上,使用所示,创建纹理参照系,texRef:
<textarea cols="50" rows="15" name="code" class="c-sharp">texture<float, 1, cudaReadModeElementType> texRef;</textarea>
CUDA数组 cuArray被分配和初始化:
<textarea cols="50" rows="15" name="code" class="c-sharp"> // create a CUDA array on the device cudaArray* cuArray; cudaMallocArray (&cuArray, &texRef.channelDesc, N, 1);</textarea>
texRef 纹理然后与cuArray绑定,纹理属性被确定。在本例中,我们确定了线性插值,我们不会使用规格化的纹理座标。
<textarea cols="50" rows="15" name="code" class="c-sharp">// bind a texture to the CUDA array cudaBindTextureToArray (texRef, cuArray); // host side settable texture attributes texRef.normalized = false; texRef.filterMode = cudaFilterModeLinear;</textarea>
内核, readTexels(), 仅仅从纹理单元拾取值,放置入d_out 数组。
<textarea cols="50" rows="15" name="code" class="c-sharp"> //Note: Appendix D.2 gives formula for interpolation float x = tex1D(texRef, float(idx)); d_out[idx] = x;</textarea>
d_out数组然后被拷贝回主机,在屏幕上显示出来。最后,纹理被释放,调用:
<textarea cols="50" rows="15" name="code" class="c-sharp"> cudaUnbindTexture(texRef);</textarea>
操作本简单样例中的属性和数据可能有助于你们认识纹理内存的运算能力。为了更好地理解这个样例,你应该参阅下面的输入,它显示了纹理是在数据点之间内插值。
<textarea cols="50" rows="15" name="code" class="c-sharp">0.000000 0.500000 1.500000 2.500000 3.500000 4.500000 5.500000 6.500000 7.500000 8.500000</textarea>
样例 1: 将纹理绑定到被更新的线性内存上。
下面这个简单的样例,negateArray.cu, 将1D纹理绑定到线性内存。纹理被用来从线性内存上拾取浮点值,纹理然后被更新。结果被带回到主机,检查其正确性。
<textarea cols="50" rows="15" name="code" class="c-sharp">#include <stdio.h> #include <assert.h> void checkCUDAError(const char *msg) { cudaError_t err = cudaGetLastError(); if( cudaSuccess != err) { fprintf(stderr, "Cuda error: %s: %s./n", msg, cudaGetErrorString( err) ); exit(EXIT_FAILURE); } } texture<float, 1, cudaReadModeElementType> texRef; __global__ void kernel(int n, float *d_out) { int idx = blockIdx.x*blockDim.x + threadIdx.x; if(idx < n) { d_out[idx] = -tex1Dfetch(texRef, idx); } } #define NUM_THREADS 256 int main() { int N = 2560; int nBlocks = N/NUM_THREADS + ((N % NUM_THREADS)?1:0); int memSize = N*sizeof(float); // data fill array with increasing values float *data; data = (float*) malloc(memSize); for (int i = 0; i < N; i++) data[i] = float(i); float *d_a; cudaMalloc( (void **) &d_a, memSize ); cudaMemcpy( d_a, data, memSize, cudaMemcpyHostToDevice ); cudaBindTexture(0,texRef,d_a,memSize); checkCUDAError("bind"); kernel<<<nBlocks, NUM_THREADS>>>(N, d_a); float *h_out = (float*)malloc(memSize); cudaMemcpy(h_out, d_a, memSize, cudaMemcpyDeviceToHost); checkCUDAError("cudaMemcpy"); for (int i = 0; i <<N; i++) { assert(data[i] == -h_out[i]); } printf("Correct/n"); cudaUnbindTexture(texRef); checkCUDAError("cudaUnbindTexture"); free(h_out); free(data); } </textarea>
在negateArray.cu和之前的readTexels.cu样例之间还是有些细小,但是很重要的区别。
第一个区别就是:我们使用cudaMalloc()分配内存线性区,d_a,
<textarea cols="50" rows="15" name="code" class="c-sharp"> float *d_a; cudaMalloc( (void **) &d_a, memSize );</textarea>
线性内存被绑定到纹理上,如下所示:
<textarea cols="50" rows="15" name="code" class="c-sharp"> cudaBindTexture(0,texRef,d_a,memSize); checkCUDAError("bind")</textarea>
在设备上,tex1Dfetch() 被用来拾取数据,然后被否定,并写入d_out:
<textarea cols="50" rows="15" name="code" class="c-sharp"> d_out[idx] = -tex1Dfetch(texRef, idx);</textarea>
请注意,内核调用通过d_a, 这意味着数据被更新:
<textarea cols="50" rows="15" name="code" class="c-sharp"> kernel<<<nBlocks, NUM_THREADS>>>(N, d_a);</textarea>
样例 2: 重新访问reverseArray_multiblock.cu 样例
最后,让我们重新看下reverseArray_multiblock.cu 样例, 在本系列文章的第三节已经详细讨论过了。我们可进行调整以使用纹理内存。在下面的reverseArray_multiblockTexture.cu源里,仅需要进行几个细小的改变,不再使用线性数组,而是使用与内存线性区绑定的纹理对象,d_a, (使用cudaMalloc进行分配)。为了方便起见,用红色和"*仅限于纹理 *" 串强调reverseArray_multiblock.cu的改变。
<textarea cols="50" rows="15" name="code" class="c-sharp">// reverseArray_multiblockTexture.cu // includes, system #include <stdio.h> #include <assert.h> // Simple utility function to check for CUDA runtime errors void checkCUDAError(const char* msg);</textarea>
// ******************仅限于纹理 *******************
// 注:缺省模式是cudaReadModeElementType
<textarea cols="50" rows="15" name="code" class="c-sharp">// section 4.3.4.1 of the NVIDIA CUDA Programming Guide texture<int, 1> tex_d_a; // Part3: implement the kernel __global__ void reverseArrayTexture(int *d_out, int *d_in) { int inOffset = blockDim.x * blockIdx.x; int outOffset = blockDim.x * (gridDim.x - 1 - blockIdx.x); int in = inOffset + threadIdx.x; int out = outOffset + (blockDim.x - 1 - threadIdx.x); // ****************** Texture Specific ******************* d_out[out] = tex1Dfetch(tex_d_a,in); } // Program main int main( int argc, char** argv) { // pointer for host memory and size int *h_a; int dimA = 256 * 1024; // 256K elements (1MB total) // pointer for device memory int *d_b, *d_a; // define grid and block size int numThreadsPerBlock = 256; // Part 1: compute number of blocks needed based on // array size and desired block size int numBlocks = dimA / numThreadsPerBlock; // allocate host and device memory size_t memSize = numBlocks * numThreadsPerBlock * sizeof(int); h_a = (int *) malloc(memSize); cudaMalloc( (void **) &d_a, memSize ); cudaMalloc( (void **) &d_b, memSize );</textarea>
// ****************** 仅限于纹理 *******************
<textarea cols="50" rows="15" name="code" class="c-sharp"> // Bind the device array d_a to a texture object tex_d_a cudaBindTexture(NULL,tex_d_a,d_a); checkCUDAError("Bind Texture"); // Initialize input array on host for (int i = 0; i < dimA; ++i) { h_a[i] = i; } // Copy host array to device array cudaMemcpy( d_a, h_a, memSize, cudaMemcpyHostToDevice ); // launch kernel dim3 dimGrid(numBlocks); dim3 dimBlock(numThreadsPerBlock); reverseArrayTexture<<< dimGrid, dimBlock >>>( d_b, d_a ); // block until the device has completed cudaThreadSynchronize(); // check if kernel execution generated an error // Check for any CUDA errors checkCUDAError("kernel invocation"); // device to host copy cudaMemcpy( h_a, d_b, memSize, cudaMemcpyDeviceToHost ); // Check for any CUDA errors checkCUDAError("memcpy"); // verify the data returned to the host is correct for (int i = 0; i < dimA; i++) { assert(h_a[i] == dimA - 1 - i ); } // ******************仅限于纹理******************* cudaUnbindTexture(tex_d_a); checkCUDAError("Unbind Texture"); // free device memory cudaFree(d_a); cudaFree(d_b); // free host memory free(h_a); // If the program makes it this far, then the results are // correct and there are no run-time errors. Good work! printf("Correct!/n"); return 0; } void checkCUDAError(const char *msg) { cudaError_t err = cudaGetLastError(); if( cudaSuccess != err) { fprintf(stderr, "Cuda error: %s: %s./n", msg, cudaGetErrorString( err) ); exit(EXIT_FAILURE); } } </textarea>
总而言之,CUDA纹理要求采取以下步骤:
主机(CPU)代码:
分配/获取内存(线性内存,音高线性内存,或CUDA数组)
创建纹理参考物体
现在,必须是在文件生存空间;
将纹理参照与内存/数组绑定起来
当完成后
断开纹理参照系,释放资源
设备 (内核) 代码
拾取使用纹理参照
线性内存纹理
tex1Dfetch
数组纹理和音高线性内存
tex1D, tex2D, 或 tex3D
该结构在reverseArray_multiblockTexture.cu可见:
主机 (CPU) 代码
<textarea cols="50" rows="15" name="code" class="c-sharp">// reverseArray_multiblockTexture.cu</textarea>
// ******************仅限于纹理*******************
// Note: default mode is cudaReadModeElementType
<textarea cols="50" rows="15" name="code" class="c-sharp">// section 4.3.4.1 of the NVIDIA CUDA Programming Guide texture<int, 1> tex_d_a; // Program main int main( int argc, char** argv) { ... // pointer for device memory int *d_b, *d_a; ... cudaMalloc( (void **) &d_a, memSize );</textarea>
// ******************仅限于纹理*******************
<textarea cols="50" rows="15" name="code" class="c-sharp">// Bind the device array d_a to a texture object tex_d_a cudaBindTexture(NULL,tex_d_a,d_a); checkCUDAError("Bind Texture"); ... // ******************仅限于纹理******************* cudaUnbindTexture(tex_d_a); checkCUDAError("Unbind Texture"); ... } </textarea>
设备(内核)代码::
<textarea cols="50" rows="15" name="code" class="c-sharp">// Part3: implement the kernel __global__ void reverseArrayTexture(int *d_out, int *d_in) { // ******************仅限于纹理******************* d_out[out] = tex1Dfetch(tex_d_a,in); } </textarea>
结论
本小节给出了一些直接的例子,显示了如何应用CUDA使用纹理对象。正如所讨论的,除了那些在reverseArray_multiblockTexture.cu样例里显示的之外,纹理内存还提供了许多其它的能力。请参见NVIDIA_CUDA_SDK项目文件夹中的样例代码,以查看更为复杂的样例。互联网也包括诸多更为有用的样例,你可下载和进行尝试。以下是两种可能:
在Google cudaiap2009 "cuda@mit"网址,在样例里,CUDA 3D 纹理样例 可能会对你有所帮助;
CIRL 模糊逻辑教程
如需了解更多有关纹理缓存和在GPU上重新使用数据的其它方法的更多信息,一个最好的资源就是Mark Silberstein的论文 Efficient Computation of Sum-products on GPUs Through Software Managed Cache(通过软件管理缓冲有效计算GPU上的合积)。如本文开头所示,Govindaraju 和Manocha的Cache-Efficient Numerical Algorithms using Graphics Hardware (使用图形硬件的缓存高效数值算法)也是个很棒的资源。如需了解针对纹理和缓存的数学观点,参见http://www.cs.lth.se/EDA075/notes/mgh_ch5.pdf。