CUDA, 用于大量数据的超级运算:第9节
http://www.ddj.com/hpc-high-performance-computing/211800683
正文:Rob Farber
使用CUDA拓展高等级语言
Rob Farber 是西北太平洋国家实验室(Pacific Northwest National Laboratory)的高级科研人员。他在多个国家级的实验室进行大型并行运算的研究,并且是几个新创企业的合伙人。大家可以发邮件到[email protected]与他沟通和交流。
在关于CUDA(Compute Unified Device Architecture,即计算统一设备架构的简称)的系列文章的第八节,我探讨了使用CUDA利用库。在本小节,我要讨论如何使用CUDA拓展高等级语言(如Python)。
CUDA可以让开发非C 或C++语言的程序员同时利用图形处理器内成百上千的线程处理器内的成千上万软件线程的“力量“。库(Part 8内讨论)提供了这样的能力,因为大部分语言与C语言库相连。在诸多语言里,如Python, Perl, 和 Java,有更为灵活和强大的能力,当为GPU环境编程时,可通过C或CUDA内编写的模块进行拓展。这些扩展的一个重要结果就是:它们让程序开发人员有了很大自由定义可以在GPU内定位和操作数据的类和方法,而不受到静态库界面的限制。
使用CUDA进行语言拓展的可能性很大,会对商业,开源和学术性开发人员产生影响。不用为了性能方面小小的提高而努力挣扎,当在CUDA启动环境里运行时,对CUDA代码调用模式(库)的简单检查可以产生大幅提供性能的命令,而同时保持兼容性。几乎是突然间,这些Apache 服务器的能力提高很多,Java客户端applet也会变得很“丰富“,开源社区会为开源项目的强大能力而欢呼。即便是处理之前那么棘手的或者超功能应用程序,科学工作人员和工程师也能够使用掌上电脑和工作站了。让我们来看看以后会是什么情况吧。(就我个人而言,我想要看到CUDA启动的GPU运行在可从JME, Java Micro版本访问的mobilephone上)。
在网路上有很多辅导教程讨论了如何在C语言和你最喜欢的语言之间进行互动。因为所有这些辅导教程都适用于CUDA,CUDA设计的魅力也就变得非常明显。实际上,CUDA也是一种C语言(有所拓展,以管理图形处理器的巨量平行运算)。这一安排的优势就是:由程序开发人员来决定最好的方法和设计。你怎么做,才能最有益于你最喜欢的项目或让你最喜欢的语言更强大?
不要忘记了CUDA启动的设备能同时在计算机和可视化任务上运行-因此不要将你的思路局限在计算拓展上。自己尝试下,运行一个计算任务,同时运行一个重要的可视化任务(对Linux X-window用户来说,glxgears 是一个很好的图形深度可视化测试,因为它很容易被获得,并且可动态汇报帧/秒率。然而,这个应用程序仅测试3D图形性能的一个小部分)。
高通量和实时流拓展也是可能的。现在,CUDA启动的设备使用PCI-E 2.0 x16 buses,以快速在系统内存之间和多个图形处理器之间移动数据(速率为GB/每秒)。数据密集视频游戏使用此带宽,可顺利运行-即使是非常高的帧率。高通量让许多非常富有创新意义的CUDA应用程序成为可能。例如,Alabama大学和Sandia 国家实验室的研究人员开发的RAID软件(参见Matthew Curry, Lee Ward, Tony Skjellum, Ron Brightwell 编写的Accelerating Reed-Solomon Coding in RAID Systems with GPUs ,IPDPS 2008)。在Massively Parallel Linux Laptops, Workstations and Clusters with CUDA(利用CUDA的巨量平行Linux笔记本,工作站和集群)里更为详细地讨论这个问题。
记住高通量是一个相对的概念。下面的图表以第七节内的表为基础。它显示PCI-E bus甚至不能连全局内存提供给线程处理器的带宽的极小一部分都不能提供,这对受PCI-E带宽限制的应用程序来说意味着性能灾害。
回忆下几个之前的专栏文章,我们可知甚至GPU上的全局内存都不能提供充足的带宽,让所有的线程处理器处于“忙碌的工作状态”。PCI-E数考虑了10-series/GTX280里PCI-E 2.0显卡容量的升级,从而有效双倍提高PCI-E 1.0。
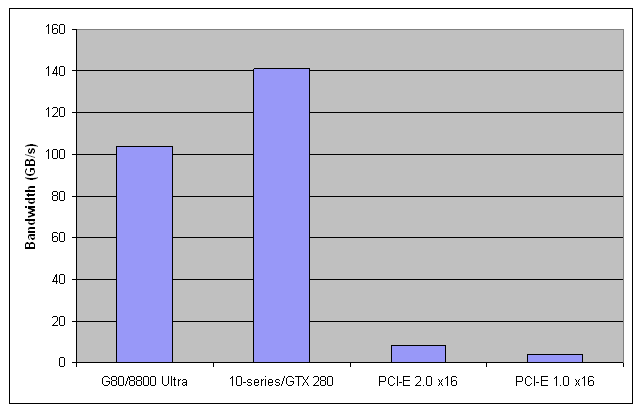
表1:线程处理器可为不同构架从不同源获取带宽(如全局内存,和PCI-E bus)。
因此,对主机或GPU全局内存内数据位置的控制对于应用程序获得高性能来说非常重要。正如第八节所讨论的,执行诸如等级1BLAS操作以将向量转移到GPU根本没有任何意义,这样只会增加一个常量,然后把修改的向量移回主机内存。为数据项目操作的低故障率,数据位置是影响性能的主导因素。仅当数据已经存在于GPU时,可执行此类操作。
注意:使用C拓展高等级语言的一个常见的问题就是当在两种语言之间转换变量和数据结构时,所需要耗费时间。CUDA程序员不得不最小化在主机和图形处理器各自的内存空间之间转换数据所需要的时间。
一个弱点也可能转换为优势。就数据位置和操作者而言,如果能恰当利用卡上的全局内存,GPU相对于现在的商业CPU处理器来说有明显的优势。为高等级语言(或C++类)创建一个设计良好的模块可最小化(甚至消除)数据转移时间,因为程序员能够控制数据的位置,并且通过他们确定的方法将数据的持续位置安置在GPU上。这样,细微的操作如在GPU上添加常量到一个向量就变得非常有意义了-只要它们与其它操作结合起来,以获得转移到GPU的数据条目的高FLOPS(每秒所执行的浮点运算次数)率。当然,语言拓展是如何执行的,在不同的应用程序里它是如何广泛应用的,取决于开发人员设计的拓展(或类)表现如何。
SWIG
一个出色的将以C 和C++语言编写的模块与广泛高等级编程语言连接起来的软件开发工具就是SWIG。它支持Perl, PHP, Python, Tcl, Java, C#, Common Lisp, Octave, R 和许多其它语言(参见www.swig.org/compat.html#SupportedLanguages)。
下面的链接,可让你准备好使用三种语言。如果下列链接不能满足你的需要,请查找其它相关网站:
Java: 使用SWIG 或 JNI (Java本地接口)。让你也行动起来的一个样例项目就是JCublas, JAVA应用程序可获得第八节探讨的CUBLAS库;
Perl: SWIG和 Wikipedia page一样,虽然CPAN 是公认的PERL库;
Python: 对extending Python with C (and hence CUDA) 的阅览是个很好的开始。Python 就是一个很好的样例(NumPy数组上的操作)就是pystream 和相关的Project GPUlib。
下面是一个简单的Python样例,由NVIDIA的一个同事提供,展示了从Python调用CUDA内核的简单快捷。本样例实际上执行了一个对商业应用程序来说有用的方法-即,矩阵求幂。不幸的是,这个方法为什么这么有效,已经不是本文要讨论的范畴了。参加http://arxiv.org/pdf/0710.1606 上论文的第19页的讨论获得更多信息。提醒下,该论文信息量非常大。
根据本文,该样例模式有效利用了GPU。它之所以高效,是因为使用该模式,Python程序员可调用 SGEMM, NVIDIA CUBLAS库里每数据条目高FLOP等级-3 BLAS例行程序。它也显示了有可能在Python 和CUDA之间映射变量――在本例里为数组。
Python代码exponentiationTest py的全部列表为
<textarea cols="50" rows="15" name="code" class="c-sharp">#! /usr/bin/env python import copy import numpy import FastMatrixExp # Read input matrix using a user defined function a = myInputReader() b = copy.copy(a) steps = 100 # Matrix exponentiation using CPU SGEMM for i in range(steps): a = numpy.dot(a,a) # Matrix exponentiation using CUBLAS SGEMM FastMatrixExp.matrixMulLoop([steps,b]) numpy.testing.assert_array_almost_equal(a, b, decimal = 6) print 'Error = %f' % numpy.linalg.norm(a-b) </textarea>
在exponentiationTest.py内,定制模块被导入:
<textarea cols="50" rows="15" name="code" class="c-sharp">import FastMatrixExp</textarea>
要求读者定义它自己的Python方法以将一个矩阵输入到变量a里,然后在变量b里复制,以比较CPU和GPU的速度和精确度:
<textarea cols="50" rows="15" name="code" class="c-sharp"># Read input matrix using a user defined function a = myInputReader() b = copy.copy(a)</textarea>
使用本代码段,矩阵 a 的力量被提升到主机上变步(特别是100)内所指定的力量:
<textarea cols="50" rows="15" name="code" class="c-sharp">steps = 100 # Matrix exponentiation using CPU SGEMM for i in range(steps): a = numpy.dot(a,a)</textarea>
此后,CUBLAS库的SGEMM例行程序从Python调用,在GPU上被用来执行矩阵求幂:
<textarea cols="50" rows="15" name="code" class="c-sharp"># Matrix exponentiation using CUBLAS SGEMM FastMatrixExp.matrixMulLoop([steps,b])</textarea>
GPU和CPU产生的结果然后被检查,通过如下NumPy比较,确定它们是否在合理差异内相等。(NumPy是出色的数值Python包,进行矩阵运算。)
<textarea cols="50" rows="15" name="code" class="c-sharp">numpy.testing.assert_array_almost_equal(a, b, decimal = 6) print 'Error = %f' % numpy.linalg.norm(a-b)</textarea>
下面是SWIG接口代码:
<textarea cols="50" rows="15" name="code" class="c-sharp">%module FastMatrixExp %header %{ #include <oldnumeric.h> #include <cublas.h> %} %include exception.i /* Matrix multiplication loop for fast matrix exponentiation. */ %typemap(python,in) (int steps, float *u, int n) { $1 = PyInt_AsLong(PyList_GetItem($input,0)); $2 = (float *)(((PyArrayObject *)PyList_GetItem($input,1))->data); $3 = ((PyArrayObject *)PyList_GetItem($input,1))->dimensions[0]; } extern void matrixMulLoop(int steps, float *u, int n); %{ void matrixMulLoop(int steps, float *u, int n) { int i; float *ud; cublasStatus status; /* Allocate memory and copy u to the device. */ status = cublasAlloc(n*n, sizeof(float), (void **)&ud); status = cublasSetMatrix(n, n, sizeof(float), (void *)u,n, (void *)ud, n); /* Do "steps" updates. */ for(i=0; i<steps; i++) cublasSgemm('n','n',n,n,n,1.0f,ud,n,ud,n,0.0f,ud,n); /* Copy u back to the host and free device memory. */ status = cublasGetMatrix(n, n, sizeof(float), (void *)ud,n, (void *)u, n); status = cublasFree((void *)ud); } %} %init %{ import_array(); cublasStatus status; status = cublasInit(); %} </textarea>
模块名称FastMatrixExp在CUBLAS的第一行里定义:
<textarea cols="50" rows="15" name="code" class="c-sharp">#module FastMatrixExp</textarea>
对cublasSgemm 的迭代调用在如下C子例行程序里发生,在%{ 和%}之间确定:
<textarea cols="50" rows="15" name="code" class="c-sharp">%{ void matrixMulLoop(int steps, float *u, int n) { int i; float *ud; cublasStatus status; /* Allocate memory and copy u to the device. */ status = cublasAlloc(n*n, sizeof(float), (void **)&ud); status = cublasSetMatrix(n, n, sizeof(float), (void *)u,n, (void *)ud, n); /* Do "steps" updates. */ for(i=0; i<steps; i++) cublasSgemm('n','n',n,n,n,1.0f,ud,n,ud,n,0.0f,ud,n); /* Copy u back to the host and free device memory. */ status = cublasGetMatrix(n, n, sizeof(float), (void *)ud,n, (void *)u, n); status = cublasFree((void *)ud); } %} </textarea>
为了更好的了解SWIG文件的其它部分,我推荐参阅SWIG documentation。在David Beazley的文章SWIG and Automated C/C++ Scripting Extensions及Blezek的Rapid Prototyping with SWIG里,你也可了解更多有关SWIG的知识。
如需了解更多结合Python 和CUDA的高级数值包,请查阅pystream 或 GPUlib (可在提交EMAIL请求之后下载)