前段代码异常日志收集与监控
在复杂的网络环境和浏览器环境下,自测、QA测试以及 Code Review 都是不够的,如果对页面稳定性和准确性要求较高,就必须有一套完善的代码异常监控体系,本文从前端代码异常监控的方法和问题着手,尽量全面地阐述错误日志收集各个阶段中可能遇到的阻碍和处理方案。
收集日志的方法
平时收集日志的手段,可以归类为两个方面,一个是逻辑中的错误判断,为主动判断;一个是利用语言给我们提供的捷径,暴力式获取错误信息,如 try..catch 和 window.onerror。
1. 主动判断
我们在一些运算之后,得到一个期望的结果,然而结果不是我们想要的
// test.js
function calc(){
// code...
return val;
}
if(calc() !== "someVal"){
Reporter.send({
position: "test.js::<Function>calc"
msg: "calc error"
});
}这种属于逻辑错误/状态错误的反馈,在接口 status 判断中用的比较多。
2. try..catch 捕获
判断一个代码段中存在的错误:
try {
init();
// code...
} catch(e){
Reporter.send(format(e));
}以 init 为程序的入口,代码中所有同步执行出现的错误都会被捕获,这种方式也可以很好的避免程序刚跑起来就挂。
3. window.onerror
捕获全局错误:
window.onerror = function() {
var errInfo = format(arguments);
Reporter.send(errInfo);
return true;
};在上面的函数中返回 return true,错误便不会暴露到控制台中。下面是它的参数信息:
/** * @param {String} errorMessage 错误信息 * @param {String} scriptURI 出错的文件 * @param {Long} lineNumber 出错代码的行号 * @param {Long} columnNumber 出错代码的列号 * @param {Object} errorObj 错误的详细信息,Anything */
window.onerror = function(errorMessage, scriptURI, lineNumber,columnNumber,errorObj) {
// code..
}window.onerror 算是一种特别暴力的容错手段,try..catch 也是如此,他们底层的实现就是利用 C/C++ 中的 goto 语句实现,一旦发现错误,不管目前的堆栈有多深,不管代码运行到了何处,直接跑到顶层或者 try..catch 捕获的那一层,这种一脚踢开错误的处理方式并不是很好。
收集日志存在的问题
收集日志的目的是为了及时发现问题,最好日志能够告诉我们,错误在哪里,更优秀的做法是,不仅告诉错误在哪里,还告诉我们,如何处理这个错误。终极目标是,发现错误,自动容错,这一步是最难的。
1. 无具体报错信息,Script error.
先看下面的例子,test.html
<!-- http://barret/test.html -->
<script> window.onerror = function(){ console.log(arguments); }; </script>
<script src="http://barret/test.js"></script>test.js
// http://barret/test.js
function test(){
ver a = 1;
return a+1;
}
test();我们期望收集到的日志是下面这样具体的信息:
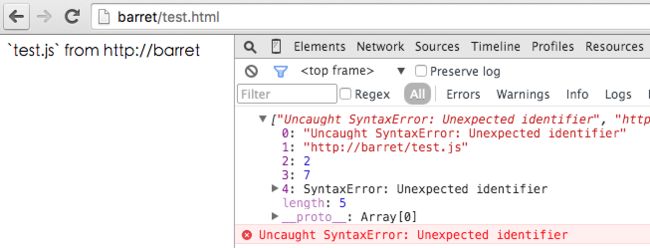
为了对资源进行更好的配置和管理,我们通常将静态资源放到异域上
<!-- http://barret/test.html -->
<script> window.onerror = function(){ console.log(arguments); }; </script>
<script src="http://localhost/test.js"></script>而拿到的结果却是:
翻开 Chromium 的 WebCore 源码,可以看到:

跨域情况下,返回的结果是 Script error.。
// http://trac.webkit.org/browser/branches/chromium/1453/Source/WebCore/dom/ScriptExecutionContext.cpp#L333
String message = errorMessage;
int line = lineNumber;
String sourceName = sourceURL;
// 已经拿到了所有的错误信息,但如果发现是非同源情况,`sanitizeScriptError` 中复写错误信息
sanitizeScriptError(message, line, sourceName, cachedScript);旧版 的 WebCore 中只判断了 securityOrigin()->canRequest(targetURL),新版中还多了一个 cachedScript 的判断,可以看出浏览器对这方面的限制越来越严格。
在本地测试了下:
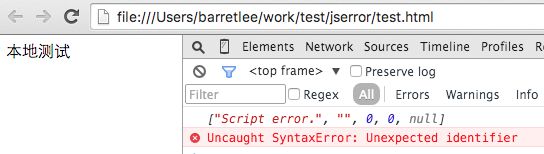
可见在 file:// 协议下,securityOrigin()->canRequest(targetURL) 也是 false。
☞ 为何Script error.?
简单报错: Script error,目的是避免数据泄露到不安全的域中,一个简单的例子:
<script src="bank.com/login.html"></script>上面我们并没有引入一个 js 文件,而是一个 html,这个 html 是银行的登录页面,如果你已经登录了 bank.com,那 login 页面就会自动跳转到 Welcome xxx…,如果未登录则跳转到 Please Login…,那么 JS 报错也会是 Welcome xxx… is not defined,Please Login… is not defined,通过这些信息可以判断一个用户是否登录他的银行帐号,给 hacker 提供了十分便利的判断渠道,这是相当不安全的。
☞ crossOrigin参数跳过跨域限制
image 和 script 标签都有 crossorigin 参数,它的作用就是告诉浏览器,我要加载一个外域的资源,并且我信任这个资源。
<script src="http://localhost/test.js" crossorigin></script>然而,却报错了:
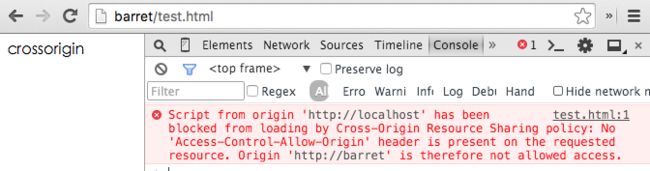
这是意料之中的错误,跨域资源共享策略要求,服务器也设置 Access-Control-Allow-Origin 的响应头:
header('Access-Control-Allow-Origin: *');回头看看我们 CDN 的资源,
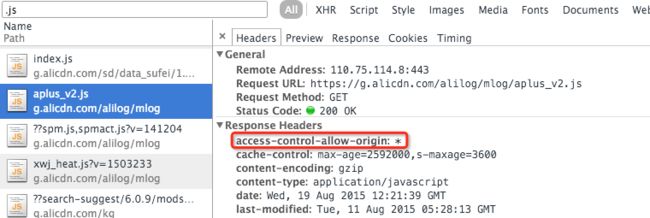
Javascript/CSS/Image/Font/SWF 等这些静态资源其实都已经早早地加上了 CORS 响应头。
2. 压缩代码无法定位到错误的具体位置
线上的代码几乎都是经过打包压缩的,几十上百的文件压缩后打包成一个,而且只有一行。当我们收到 a is not defined 的时候,如果只在特定场景下才报错,我们根本无法定位到这个被压缩的 a 是个什么东西,那么此时的错误日志就是无效的。
第一个想到的办法是利用 sourceMap,利用它可以定位到压缩代码某一点在未压缩代码的具体位置。下面是 sourceMap 引入的格式,在代码的最后一行加入:
//# sourceMappingURL=index.js.map以前使用的是 ‘//@’ 作为开头,现在使用 ‘//#’,然而对于错误上报,这玩意儿没啥用。JS 不能拿到他真实的行数,只能通过 Chrome DevTools 这样的工具辅助定位,而且并不是每个线上资源都会添加 sourceMap 文件。sourceMap 的用途目前还只能体现在开发阶段。
当然,如果理解了 sourceMap 的 VLQ编码和位置对应关系,也可以将拿到的日志进行二次解析,映射到真实路径位置,这个成本比较高,貌似暂时也没人尝试过。
那么,有什么办法,可以定位错误的具体位置,或者说有什么办法可以缩小我们定位问题的难度呢?
可以这样考虑:打包的时候,在每两个合并的文件之间加上 1000 个空行,最后上线的文件就会变成
(function(){var longCode.....})(); // file 1
// 1000 个空行
(function(){var longCode.....})(); // file 2
// 1000 个空行
(function(){var longCode.....})(); // file 3
// 1000 个空行
(function(){var longCode.....})(); // file 4
var _fileConfig = ['file 1', 'file 2', 'file 3', 'file 4']如果报错在第 3001 行,
window.onerror = function(msg, url, line, col, error){
// line = 3001
var lineNum = line;
console.log("错误位置:" + _fileConfig[lineNum % 1000 - 1]);
// -> "错误位置:file 3"
};可以计算出,错误出现在第三个文件中,范围就缩小了很多。
3. error 事件的注册
多次注册 error 事件,不会重复执行多个回调:
var fn = window.onerror = function() {
console.log(arguments);
};
window.addEventListener("error", fn); window.addEventListener("error", fn);触发错误之后,上面代码的结果为:

window.onerror 和 addEventListener 都执行了,并只执行了一次。
4. 收集日志的量
没有必要将所有的错误信息全部送到 Log 中,这个量太大了。如果网页 PV 有 1kw,那么一个必现错误发送的 log 信息将有 1kw 条,大约一个 G 的日志。我们可以给 Reporter 函数添加一个采样率:
function needReport (sampling){
// sampling: 0 - 1
return Math.random() <= sampling;
}
Reporter.send = function(errInfo, sampling) {
if(needReport(sampling || 1)){
Reporter._send(errInfo);
}
};这个采样率可以按需求来处理,可以同上,使用一个随机数,也可以使用 cookie 中的某个字段(如 nickname)的最后一个字母/数字来判定,也可以将用户的 nickname 进行 hash 计算,再通过最后一位的字母/数字来判断,总之,方法是很多的。
收集日志布点位置
为了更加精准的拿到错误信息,有效地统计错误日志,我们应该更多地采用主动式埋点,比如在一个接口的请求中:
// Module A Get Shops Data
$.ajax({
url: URL,
dataType: "jsonp",
success: function(ret) {
if(ret.status === "failed") {
// 埋点 1
return Reporter.send({
category: "WARN",
msg: "Module_A_GET_SHOPS_DATA_FAILED"
});
}
if(!ret.data || !ret.data.length) {
// 埋点 2
return Reporter.send({
category: "WARN",
msg: "Module_A_GET_SHOPS_DATA_EMPTY"
});
}
},
error: function() {
// 埋点 3
Reporter.send({
category: "ERROR",
msg: "Module_A_GET_SHOPS_DATA_ERROR"
});
}
});上面我们精准地布下了三个点,描述十分清晰,这三个点会对我们后续排查线上问题提供十分有利的信息。
关于 try..catch 的使用
对于 try..catch 的使用,我的建议是:能不用,尽量不要用。JS代码都是自己写出来的,哪里会出现问题,会出现什么问题,心中应该都有个谱,平时用到 try..catch 的一般只有两个地方:
// JSON 格式不对
try{
JSON.parse(JSONString);
}catch(e){}
// 存在不可 decode 的字符
try{
decodeComponentURI(string);
}catch(e){}类似这样的错误都是不太可控的。可以在使用到 try..catch 的地方思考是否可以使用其他方式做兼容。
关于 window.onerror 的使用
可以尝试如下代码:
// test.js
throw new Error("SHOW ME");
window.onerror = function(){
console.log(arguments);
// 阻止在控制台中打印错误信息
return true;
};上面的代码直接报错了,没有继续往下执行。页面中可能有好几个 script 标签,但是 window.onerror 这个错误监听一定要放到最前头!
错误的警报与提示
什么时候该警报?不能有错就报。上面也说了,因为网络环境和浏览器环境因素,复杂页面我们允许千分之一的错误率。日志处理后的数据图:
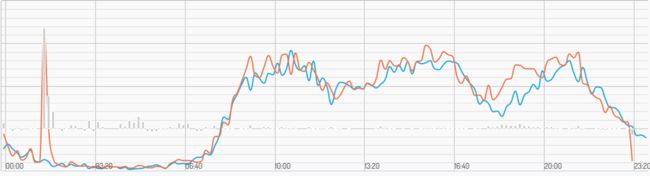
图中有两根线,橙色线是今日的数据,浅蓝色线是往日平均数据,每隔 10 分钟产生一条记录,横坐标是 0-24 点的时间轴,纵坐标是错误量。可以很明显的看出,在凌晨一两点左右,服务出现了异常,错误信息是平均值的十几倍,那么这个时候就改报警了。
报警的条件可以设置得严苛一点,因为误报是件很烦人的事情,短信、邮件、软件等信息轰炸,有的时候还是大半夜。那么,一般满足如下条件可以报警:
- 错误超过阈值,比如 10分钟最多允许 100 个错误,结果超过了 100
- 错误超过平均值的 10 倍,超过平均值就报警,这个逻辑显然不正确,但是超过了平均值的 10 倍,基本可以认定服务出问题了
- 在纳入对比之前,要过滤同 IP 出现的错误,比如一个错误出现在 for 循环或者 while 循环中,再比如一个用户在蹲点抢购,不停的刷新
友好的错误提示
对比下面两条日志,catch 的错误日志:
Uncaught ReferenceError: vd is not defined自定义的错误日志:
“生日模块中获取后端接口信息时,eval 解析出错,错误内容为:vd is not defined.”
该错误在最近 10 分钟内出现 1000 次,这个错误往日的平均出错量是 50 次 / 10 分钟网络错误日志工作草案
W3C Web Performance工作组发布了网络错误日志工作草案。该文档定义了一个机制,允许Web站点声明一个网络错误汇报策略,浏览器等用户代理可以利用这一机制,汇报影响资源正确加载的网络错误。该文档还定义了一个错误报告的标准格式及其在浏览器和Web服务器之间的传输机制。
详细草案:http://www.w3.org/TR/2015/WD-network-error-logging-20150305/
小结
功能、测试和监控是程序开发的三板斧,很多工程师可以将功能做的尽善尽美,也了解一些测试方面的知识,可是在监控这个方向上基本处于大脑空白。错误日志的收集、整理算是监控的一个小部分,但是它对我们了解网站稳定性至关重要。文中有忽略的地方希望读者可以补充,错误的地方还望斧正。
拓展阅读
基于window.onerror事件 建立前端错误日志 by Dx. Yang
构建web前端异常监控系统–FdSafe by 石破
JavaScript Source Map 详解 by 阮一峰
HTML5标准-window.onerror
MSDN-window.onerror
MDN-window.onerror
网络错误日志
转载自:前段代码异常日志收集与监控