IBM SPSS Modeler Server支持对数据库供应商的数据挖掘工具和建模工具进行整合,其中包括IBM Netezza、IBM DB2 InfoSphere Warehouse、Oracle Data Miner和Microsoft Analysis Services。实现了在IBM SPSS Modeler的分析功能和易用性将与数据库的功能和性能相结合,同时还兼备数据库供应商提供的数据库自有算法。模型在数据库创建,然后可以借助IBM SPSS Modeler界面以正常方式浏览模型并为之评分。
那么使用IBM SPSS Modeler访问数据库自有算法有什么优势呢?主要是两方面:
1.数据库内的算法常常与数据库服务器紧密集成,这有助于提高性能。
2.在“数据库内”构建和存储的模型不仅由可访问数据库的应用程序共享,且更易于在这些应用程序中部署。
接下来我们以Microsoft Analytics Services为例,介绍如何配置以及使用数据库内建模功能。
IBM SPSS Modeler支持集成下列Analysis Services算法包括:
- 决策树
- 聚类
- 关联规则
- 朴素贝叶斯
- 线性回归
- 神经网络
- Logistic回归
- 时间序列
- 序列聚类
安装与配置:
在您的机器上,必须安装以下模块:
- IBM SPSS Modeler Client
- IBM SPSS Modeler Server
- Microsoft Analysis Services,与相应数据库建立ODBC连接
1. 配置IBM SPSS Modeler:
在IBM SPSS Modeler中,在菜单栏的工具-->选项-->帮助应用程序,选择Microsoft面板,如下图:
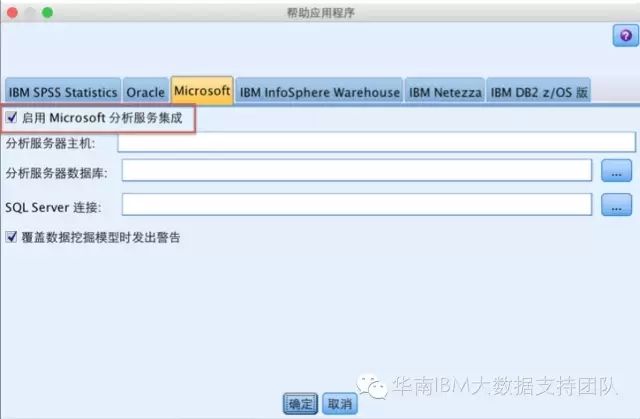
勾上之后,会在下面的面板节点上多了一项数据库建模,列出了Microsoft Analysis Services支持的数据库内建模算法,如下图:
2. 配置 SQL Server
该配置可实现在数据库内进行评分。
在 SQL Server 主机上创建以下注册表键:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSSQLServer\Providers\MSOLAP
为该键添加如下 DWORD 键值:
AllowInProcess 1
完成上述更改后,重新启动SQL Server。
3. 配置Microsoft Analysis Services
建立IBM SPSS Modeler 与Microsoft Analysis Services 进行通信。
通过MS SQL Server Management Studio 登录到分析服务器。
访问“属性”对话框,右键单击服务器名称,然后选择属性。
选中显示高级(所有)属性复选框。
更改以下属性:
将 DataMining\AllowAdHocOpenRowsetQueries 的值更改为 True(缺省值为False)。
将 DataMining\AllowProvidersInOpenRowset 的值更改为 [all] (无缺省值)。
4. 为SQL Server 创建 ODBC DSN
通过使用 Microsoft SQL Native Client ODBC 驱动程序,创建一个指向数据挖掘过程中使用的 SQL Server 数据库的 ODBC DSN。余下的驱动程序设置应使用缺省设置。
对于此DSN,请确保选中了使用集成的 Windows 认证。
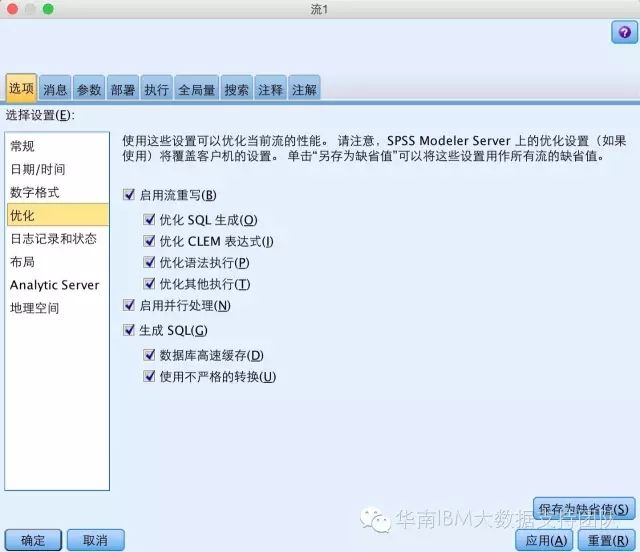
5. 启用 SQL 生成和优化
从IBM SPSS Modeler菜单中选择:工具—>流属性—>选项—>优化面板,勾选上所有选项内容如下图:
使用Microsoft Analysis Services 算法生成模型
以上内容配置完成后,即可使用数据库内的算法生成模型。如下图:
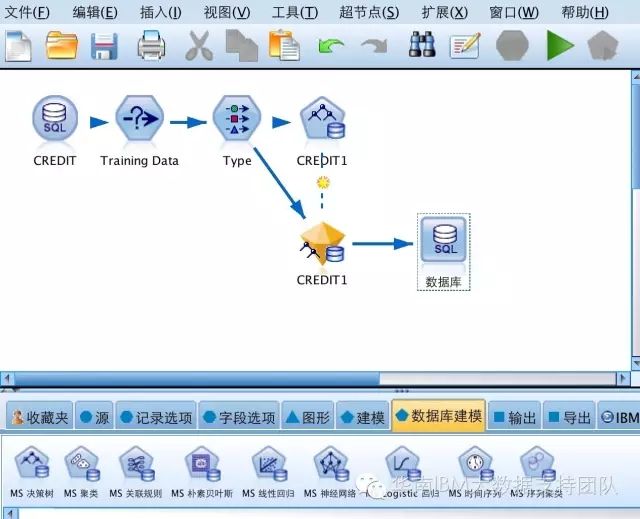
源节点从SQL Server数据库中读取,终端节点又写回到SQL Server数据库中,中间使用的是Microsoft的决策树算法,整个计算过程都在数据库中实现。
介绍到这里,我们就了解了,如何使用数据库内算法进行建模的过程,经常会有朋友问说,使用这里的决策树算法和使用IBM SPSS Modeler封装好的决策树算法,结果会有什么不同?预测结果当然是会有差异的了。本身决策树算法就包含多种,像C&R、CHAID、C5.0、QUEST等,每个算法计算逻辑就不一样,因此计算得到的结果自然也不一样,前面我们已经介绍过C&R、CHAID、C5.0这三种算法,他们核心的差异就是选择最佳分组变量和分割点的标准,而Microsoft Analysis Services决策树是使用线性回归来确定决策树分割位置,它可以用于分类属性和连续属性的预测建模。那么到底选择什么算法为优呢,前面已经介绍了,使用数据库内建模的好处,大家可以综合考虑,结合实际场景和数据预测结果的评估再做选择。
SPSS试用版下载请点击>>>