Storm的wordcount实战示例
有关strom的具体介绍,本文不再过多叙述,不了解的朋友可参考之前的文章
http://qindongliang.iteye.com/category/361820
本文主要以一个简单的wordcount例子,来了解下storm应用程序的开发,虽然只是一个简单的例子
但麻雀虽小,五脏俱全,主要涉及的内容:
(1)wordcount的拓扑定义
(2)spout的使用
(3)bolt的使用
(4)tick定时器的使用
(5) bolt之间数据传输的坑
简单的数据流程图如下:
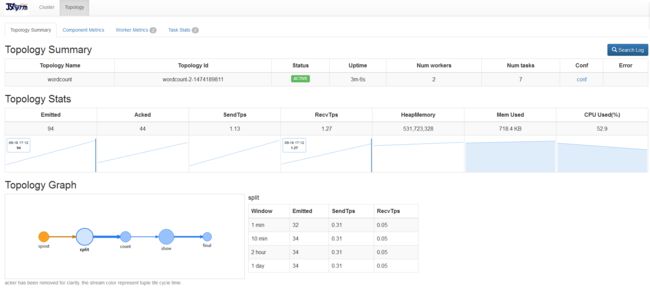
提交到storm集群上的拓扑图:
maven项目的pom依赖:
(1)Topology主拓扑类:
(2)Spout数据源类
(3)Split的bolt类
(4)Sum的bolt类
(5)Show的bolt类
(6)Final的bolt类
有什么问题可以扫码关注微信公众号:我是攻城师(woshigcs),在后台留言咨询。
技术债不能欠,健康债更不能欠, 求道之路,与君同行。

http://qindongliang.iteye.com/category/361820
本文主要以一个简单的wordcount例子,来了解下storm应用程序的开发,虽然只是一个简单的例子
但麻雀虽小,五脏俱全,主要涉及的内容:
(1)wordcount的拓扑定义
(2)spout的使用
(3)bolt的使用
(4)tick定时器的使用
(5) bolt之间数据传输的坑
简单的数据流程图如下:
提交到storm集群上的拓扑图:
maven项目的pom依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jstrom.demo</groupId>
<artifactId>jstrom-test</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<jstorm.version>2.1.1</jstorm.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<slf4j.version>1.7.12</slf4j.version>
<joad-time.version>2.9.4</joad-time.version>
<storm-kafka.version>0.9.4</storm-kafka.version>
<kafka.version>0.9.0.0</kafka.version>
<esper.version>5.4.0</esper.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/com.espertech/esper -->
<!-- https://mvnrepository.com/artifact/joda-time/joda-time -->
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>${joad-time.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka_2.11 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>${kafka.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba.jstorm</groupId>
<artifactId>jstorm-core</artifactId>
<version>${jstorm.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.storm/storm-kafka -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>${storm-kafka.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jdk14</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>${slf4j.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>换成自己的主类</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-my-jar-with-dependencies</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
(1)Topology主拓扑类:
package com.jstorm.wd;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
/**
* Created by QinDongLiang on 2016/9/12.
*/
public class TopologyWordCount {
public static void main(String[] args) throws Exception {
TopologyBuilder builder=new TopologyBuilder();
//设置数据源
builder.setSpout("spout",new CreateSentenceSpout(),1);
//读取spout数据源的数据,进行split业务逻辑
builder.setBolt("split",new SplitWordBolt(),1).shuffleGrouping("spout");
//读取split后的数据,进行count (tick周期10秒)
builder.setBolt("count",new SumWordBolt(),1).fieldsGrouping("split",new Fields("word"));
//读取count后的数据,进行缓冲打印 (tick周期3秒,仅仅为测试tick使用,所以多加了这个bolt)
builder.setBolt("show",new ShowBolt(),1).shuffleGrouping("count");
//读取show后缓冲后的数据,进行最终的打印 (实际应用中,最后一个阶段应该为持久层)
builder.setBolt("final",new FinalBolt(),1).allGrouping("show");
Config config=new Config();
config.setDebug(false);
//集群模式
if(args!=null&&args.length>0){
config.setNumWorkers(2);
StormSubmitter.submitTopology(args[0],config,builder.createTopology());
//单机模式
}else{
config.setMaxTaskParallelism(1);;
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("word-count",config,builder.createTopology());
Thread.sleep(3000000);
cluster.shutdown();
}
}
}
(2)Spout数据源类
package com.jstorm.wd;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import org.joda.time.DateTime;
import java.util.Map;
import java.util.Random;
/**
* Created by QinDongLiang on 2016/8/31.
* 创建数据源
*/
public class CreateSentenceSpout extends BaseRichSpout {
//
SpoutOutputCollector collector;
Random random;
String [] sentences=null;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.collector=spoutOutputCollector;//spout_collector
random=new Random();//
sentences=new String[]{"hadoop hadoop hadoop java java "};
}
@Override
public void nextTuple() {
Utils.sleep(10000);
//获取数据
String sentence=sentences[random.nextInt(sentences.length)];
System.out.println("线程名:"+Thread.currentThread().getName()+" "+new DateTime().toString("yyyy-MM-dd HH:mm:ss ")+"10s发射一次数据:"+sentence);
//向下游发射数据
this.collector.emit(new Values(sentence));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("sentence"));
}
}
(3)Split的bolt类
package com.jstorm.wd;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
/**
* 简单的按照空格进行切分后,发射到下一阶段bolt
* Created by QinDongLiang on 2016/8/31.
*/
public class SplitWordBolt extends BaseRichBolt {
Map<String,Integer> counts=new HashMap<>();
private OutputCollector outputCollector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.outputCollector=outputCollector;
}
@Override
public void execute(Tuple tuple) {
String sentence=tuple.getString(0);
// System.out.println("线程"+Thread.currentThread().getName());
// 简单的按照空格进行切分后,发射到下一阶段bolt
for(String word:sentence.split(" ") ){
outputCollector.emit(new Values(word));//发送split
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//声明输出的filed
outputFieldsDeclarer.declare(new Fields("word"));
}
}
(4)Sum的bolt类
package com.jstorm.wd;
import backtype.storm.Config;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import backtype.storm.utils.TupleHelpers;
import backtype.storm.utils.Utils;
import org.joda.time.DateTime;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.*;
import java.util.HashMap;
import java.util.Map;
/**
* Created by QinDongLiang on 2016/8/31.
*/
public class SumWordBolt extends BaseRichBolt {
Map<String,Integer> counts=new HashMap<>();
private OutputCollector outputCollector;
final static Logger logger= LoggerFactory.getLogger(SumWordBolt.class);
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.outputCollector=outputCollector;
}
@Override
public Map<String, Object> getComponentConfiguration() {
Map<String, Object> conf = new HashMap<String, Object>();
conf.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 10);//加入Tick时间窗口,进行统计
return conf;
}
public static Object deepCopy(Object srcObj) {
Object cloneObj = null;
try {
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream oo = new ObjectOutputStream(out);
oo.writeObject(srcObj);
ByteArrayInputStream in = new ByteArrayInputStream(out.toByteArray());
ObjectInputStream oi = new ObjectInputStream(in);
cloneObj = oi.readObject();
} catch(IOException e) {
e.printStackTrace();
} catch(ClassNotFoundException e) {
e.printStackTrace();
}
return cloneObj;
}
@Override
public void execute(Tuple tuple) {
//时间窗口定义为10s内的统计数据,统计完毕后,发射到下一阶段的bolt进行处理
//发射完成后retun结束,开始新一轮的时间窗口计数操作
if(TupleHelpers.isTickTuple(tuple)){
System.out.println(new DateTime().toString("yyyy-MM-dd HH:mm:ss")+" 每隔10s发射一次map 大小:"+counts.size());
// Map<String,Integer> copyMap= (Map<String, Integer>) deepCopy(counts);
outputCollector.emit(new Values(counts));//10S发射一次
// counts.clear();
counts=new HashMap<>();//这个地方,不能执行clear方法,可以再new一个对象,否则下游接受的数据,有可能为空 或者深度copy也行,推荐new
return;
}
//如果没到发射时间,就继续统计wordcount
System.out.println("线程"+Thread.currentThread().getName()+" map 缓冲统计中...... map size:"+counts.size());
//String word=tuple.getString(0);//如果有多tick,就不用使用这种方式获取tuple里面的数据
String word=tuple.getStringByField("word");
Integer count=counts.get(word);
if(count==null){
count=0;
}
count++;
counts.put(word,count);
// System.out.println(word+" =====> "+count);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word_map"));
}
}
(5)Show的bolt类
/**
* Created by QinDongLiang on 2016/9/12.
*/
public class ShowBolt extends BaseRichBolt {
private OutputCollector outputCollector;
@Override
public Map<String, Object> getComponentConfiguration() {
Map<String, Object> conf = new HashMap<String, Object>();
conf.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 3);//tick时间窗口3秒后,发射到下一阶段的bolt,仅为测试用
return conf;
}
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.outputCollector=outputCollector;
}
Map<String,Integer> counts=new HashMap<>();
@Override
public void execute(Tuple tuple) {
//tick时间窗口3秒后,发射到下一阶段的bolt,仅为测试用,故多加了这个bolt逻辑
if(TupleHelpers.isTickTuple(tuple)){
System.out.println(new DateTime().toString("yyyy-MM-dd HH:mm:ss")+" showbolt间隔 应该是 3 秒后 ");
// System.out.println("what: "+tuple.getValue(0)+" "+tuple.getFields().toList());
outputCollector.emit(new Values(counts));
return;
}
counts= (Map<String, Integer>) tuple.getValueByField("word_map");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("final_result"));
}
}
(6)Final的bolt类
package com.jstorm.wd;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;
import org.joda.time.DateTime;
import java.util.Map;
/**
* Created by QinDongLiang on 2016/9/12.
* 最终的结果打印bolt
*/
public class FinalBolt extends BaseRichBolt {
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
}
@Override
public void execute(Tuple tuple) {
// 最终的结果打印bolt
System.out.println(new DateTime().toString("yyyy-MM-dd HH:mm:ss")+" final bolt ");
Map<String,Integer> counts= (Map<String, Integer>) tuple.getValue(0);
for(Map.Entry<String,Integer> kv:counts.entrySet()){
System.out.println(kv.getKey()+" "+kv.getValue());
}
//实际应用中,最后一个阶段,大部分应该是持久化到mysql,redis,es,solr或mongodb中
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
有什么问题可以扫码关注微信公众号:我是攻城师(woshigcs),在后台留言咨询。
技术债不能欠,健康债更不能欠, 求道之路,与君同行。