SQL Server-聚焦IN VS EXISTS VS JOIN性能分析(十九)
前言
本节我们开始讲讲这一系列性能比较的终极篇IN VS EXISTS VS JOIN的性能分析,前面系列有人一直在说场景不够,这里我们结合查询索引列、非索引列、查询小表、查询大表来综合分析,简短的内容,深入的理解,Always to review the basics。
IN VS EXISTS VS JOIN性能分析
我们继续创建测试表,如下
CREATE SCHEMA [compare]
CREATE TABLE t_outer (
id INT NOT NULL PRIMARY KEY,
val1 INT NOT NULL,
val2 INT NOT NULL
)
CREATE TABLE t_inner (
id INT NOT NULL PRIMARY KEY,
val1 INT NOT NULL,
val2 INT NOT NULL
)
CREATE TABLE t_smallinner (
id INT NOT NULL PRIMARY KEY,
val1 INT NOT NULL,
val2 INT NOT NULL
)
GO
CREATE INDEX ix_outer_val1 ON [compare].t_outer (val1)
CREATE INDEX ix_inner_val1 ON [compare].t_inner (val1)
CREATE INDEX ix_smallinner_val1 ON [compare].t_smallinner (val1)
创建三个表即t_outer、t_inner、t_smaler同时将三个表中的列val1创建索引而对t_smaller表中的val2未创建索引,下面我们开始插入测试数据
USE TSQL2012 GO DECLARE @num INT SET @num = 1 WHILE @num <= 100000 BEGIN INSERT INTO [compare].t_inner VALUES (@num, RAND() * 100000000, RAND() * 100000000) INSERT INTO [compare].t_outer VALUES (@num, RAND() * 100000000, RAND() * 100000000) SET @num = @num + 1 END GO
对t_inner和t_outer分别插入10万条随机数据,然后去取t_outer表中最后100条数据插入到表t_smaller中
USE TSQL2012 GO INSERT INTO [compare].t_smallinner SELECT TOP 100 ROW_NUMBER() OVER (ORDER BY id DESC), val1, val2 FROM [compare].t_outer ORDER BY id DESC GO
表以及测试数据创建完毕,下面我们开始一个一个分析。
(1)IN性能分析(在大表上查询索引列val1)
SELECT val1
FROM [compare].t_outer o
WHERE val1 IN
(
SELECT val1
FROM [compare].t_inner
)
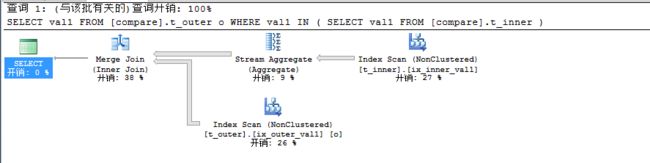
我们将上述查询计划示意图过程简短描述成如下:

整个查询耗费时间如下:

此时整个查询时间耗费70毫秒,对于10万条数据来说算是非常快的了,因为此时我们在t_inner表和t_outer表上的列val1都建立了索引,所以此时选择Stream Aggregate来进行过滤去除对于t_outer表上的val1中对应的t_inner表上的val1的重复值。到底是怎么去除重复的呢?它会记录重复的最后一个值,当再有值被找到,此时将无法通过。上述之所以查询非常快的原因在于输入行已经提前进行了预排序。最后得到的两个表的结果集进行Merge Join,进行Merge Join时,它会初始化一个变量并将指针指向加入的两个列的最小值,然后返回两个表结果集中匹配到的值,然后将指针指向下一个两个索引列中的存在的值,否则跳过不匹配的值,一直到完成,当进行如下查询时和上述查询计划是一致的。
SELECT o.val1
FROM [compare].t_outer o
JOIN (
SELECT DISTINCT val1
FROM [compare].t_inner
) i
ON i.val1 = o.val1
(1)EXISTS性能分析(在大表上查询索引列val1)
我们通过如下查询来分析EXISTS
USE TSQL2012 GO SET STATISTICS IO ON SET STATISTICS TIME ON SELECT val1 FROM [compare].t_outer o WHERE EXISTS ( SELECT 1 FROM [compare].t_inner s WHERE s.val1 = o.val1 )
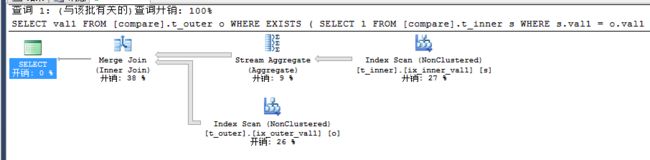
上述我们能够很清楚的知道EXISTS查询计划和IN是一致的,信不信由你,当下次面试再问二者性能的问题时,可千万别说EXISTS性能高于IN,这是错误的,上述我们已经分析得出其实是一样的。如果你仍是觉得EXISTS性能高于IN,请用事实证明。上述我们一直演示的是查询索引列val1,那要是在非索引列val2上查询会怎样呢。
(2)IN性能分析(在大表上查询非索引列val2)
USE TSQL2012
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT val2
FROM [compare].t_outer
WHERE val2 IN
(
SELECT val2
FROM [compare].t_inner
)
我们再来分析下查询计划

我们重点看看Hash Match(Left Semi Join),此时对t_outer表上的值建立哈希表,然后t_inner表中每一行值来探测该哈希表,接着通过Left Semi Join来匹配值,如果匹配到值,此时匹配到的值会立即从哈希表中移除,最终哈希表将逐渐缩小。接着我们再来看EXISTS。
(2)EXISTS性能分析(在大表上查询非索引列val2)
USE TSQL2012 GO SET STATISTICS IO ON SET STATISTICS TIME ON SELECT val2 FROM [compare].t_outer o WHERE EXISTS ( SELECT 1 FROM [compare].t_inner s WHERE s.val2 = o.val2 )

此时我们看到无论是查询索引列还是非索引列EXISTS和IN在查询计划和耗费时间几乎完全是一致的,到这里我们针对讨论的是大表10万条数据,下面我们会讨论在小表t_smaller中有关二者的查询。接下来我们看看利用JOIN在索引列上进行查询。
(2)JOIN性能分析(在大表上查询非索引列val2)
USE TSQL2012
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT o.val2
FROM [compare].t_outer o
JOIN (
SELECT DISTINCT val2
FROM [compare].t_inner
) i
ON i.val2 = o.val2
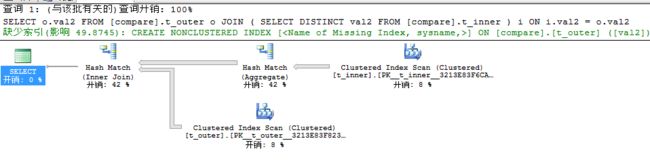

我们看到查询耗费时间和查询计划都和EXISTS、IN有不同,我们再来看看执行的顺序。

与上述不同的是JOIN在两个表联合之前首先进行了Hash Match(Aggregate),也就是说和EXISTS、IN不同之处在于重复值的处理,对于EXISTS、IN来说直接将两个表进行联合然后通过LEFT Semi Join来进行过滤重复值,在此通过哈希匹配中的聚合来过滤去除重复值val2,Hash Match(Aggregare)建立了一个唯一的哈希表,所以很容易来过滤重复值,因为有重复值过来时唯一哈希表能够探测到会产生值冲突,此时重复值都不会进入哈希表中。查询引擎通过哈希表来探测t_outer中的值,最终返回匹配的值。普遍想法是JOIN性能比EXISTS、IN性能要好,上述我们在查询非索引列时其查询开销和耗费时间却比EXISTS、IN要高,所以相对来说JOIN对于查询非索引列时其性能是比较低效的。接下来我们继续来看看查询小表t_smaller的情况。
(3)IN性能分析(在小表上查询索引列val1)
我们查询小表看看关于IN的查询情况是怎样的呢
USE TSQL2012
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT val1
FROM [compare].t_outer o
WHERE val1 IN
(
SELECT val1
FROM [compare].t_smallinner
)
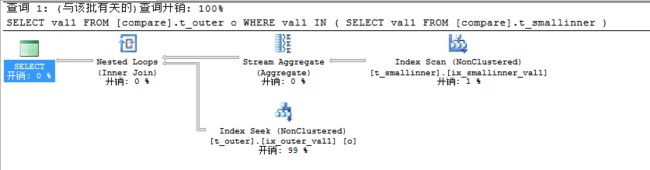
因为数据只有100条的小表其查询耗费时间当然非常少且查询速度非常快,我们重点看看其查询计划。此时合并结果集时不再是Merge Join代替的是遍历整个索引,它会扫描整个t_smaller表来过滤重复值,当然仅仅只是查找在t_outer表上创建的索引列val1且是通过索引查找的方式。数据量小所以即使是遍历整个索引也是非常快的。在EXISTS和JOIN中其执行计划结果和上述一致,下面我们再来看看查询非索引列的情况。
(4)IN性能分析(在小表上查询非索引列val2)
USE TSQL2012
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT val2
FROM [compare].t_outer o
WHERE val2 IN
(
SELECT val2
FROM [compare].t_smallinner
)

此时我们看到查询小表上非索引列val2和大表上的非索引列val2执行计划几乎是一样的,有一点不同的是在大表中建立哈希表是在外部查询表中,在这里却是在子查询表中建立哈希表,这就是查询引擎高明的地方,数据少时在小表上建立哈希表一来在哈希表中存储的数据少即占用内存少,二来当匹配到值时就缩减哈希表的大小。我们再来看看JOIN的情况。
(4)JOIN性能分析(在小表上查询非索引列val2)
USE TSQL2012
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT o.val2
FROM [compare].t_outer o
JOIN (
SELECT DISTINCT val2
FROM [compare].t_smallinner
) i
ON i.val2 = o.val2


因为数据量小所以耗费时间短,这个我们可以忽略不看,我们还是看看查询计划情况,此时利用Distinct Sort来消除重复的数据而不是利用哈希表,它会一次次的重建,可想而知性能的低下。分析到这里为止,我们看到在SQL Server中其实在有些情况下IN、EXISTS的查询性能是高于JOIN的。还不相信吗,我们再来看一个例子。
USE TSQL2012 GO SET STATISTICS IO ON SET STATISTICS TIME ON SELECT val2 FROM [compare].t_outer o WHERE EXISTS ( SELECT 1 FROM [compare].t_smallinner s WHERE s.val2 - o.val2 = 0 )
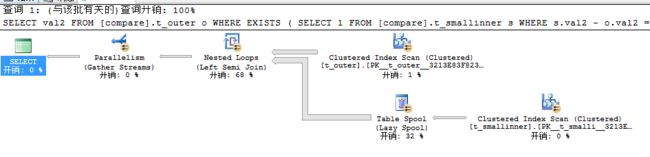

因为查询条件压根就无法匹配导致哈希表都不会有,结果查询引擎会使用Nested Loops(Left Semi Join)来进行全表扫描,此时耗费时间接近需要2秒。好了,到这里为止我们关于IN VS EXISTS VS JOIN的分析就已经完全结束,参考资料:【https://explainextended.com/2009/06/16/in-vs-join-vs-exists/】下面我们和前面一样来对这三者下一个结论:
IN VS EXISTS VS JOIN性能分析结论:在查询非索引列时,利用JOIN查询性能低下,因为利用EXISTS和IN会直接利用半联接来匹配哈希表,而JOIN需要先进行哈希聚合之后再进行完全JOIN,换句话说,EXISTS和IN只需一步操作就完成,而JOIN需要两步操作来完成,当然对于有索引的前提下,数据量巨大的话,利用JOIN其性能同样也是非常高效的。而IN和EXISTS的性能是一样的,至于为何推荐用EXISTS的原因在于基于EXISTS是三值逻辑,而IN是两值逻辑,利用EXISTS来查询比IN更加灵活,安全、保险,而且大多数情况下利用IN来查询都可以利用EXISTS来代替查询。
总结
本节我们讨论了IN VS EXISTS VS JOIN的性能比较,至此关于所有IN/NOT IN VS EXISTS/NOT EXISTS VS JOIN/LEFT JOIN..IS NULL的性能分析到此告一段落,接下来我们将会讲述Stream Aggregate VS Hash Match Aggregate,敬请期待,简短的内容,深入的理解,我们下节再会。