Redis优化
Redis优化
精简键名和键值
键名:尽量精简,但是也不能单纯为了节约空间而使用不易理解的键名。
键值:对于键值的数量固定的话可以使用0和1这样的数字来表示,(例如:male/female、right/wrong)
是否需要持久化
当业务场景不需要数据持久化时,关闭所有的持久化方式可以获得最佳的性能,不过一般都要持久化比较安全,而且是快照和aof同时使用比较安全
showlog
如果发现redis性能低下,可以通过showlog查看是由于那些语句导致的
slowlog-log-slower-than //它决定要对执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的命令进行记录
slowlog-max-len //它决定 slowlog 最多能保存多少条日志
修改Linux内核内存分配策略
原因:
redis在运行过程中可能会出现下面问题
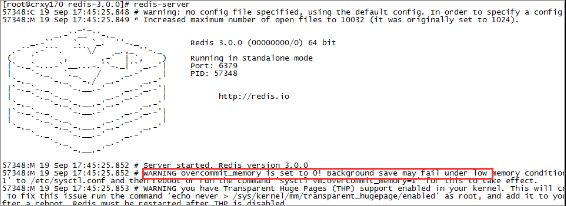
错误日志:
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to
redis备份原理
redis在备份数据的时候,会fork出一个子进程,理论上child进程所占用的内存和parent是一样的,比如parent占用的内存为8G,这个时候也要同样分配8G的内存给child,如果内存无法负担,往往会造成redis服务器的down机或者IO负载过高,效率下降。所以内存分配策略应该设置为 1(表示内核允许分配所有的物理内存,而不管当前的内存状态如何)。
内存分配策略有三种(0、1、2)
0. 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1. 不管需要多少内存,都允许申请。
2. 只允许分配物理内存和交换内存的大小。(交换内存一般是物理内存的一半)
修改方法
1. 向/etc/sysctl.conf添加
vm.overcommit_memory = 1 //然后重启服务器
2. 执行修改命令
sysctl vm.overcommit_memory=1 //立即生效
修改linux中TCP 监听的最大容纳数量
在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核默默地将这个值减小到/proc/sys/net/core/somaxconn的值,所以需要确认增大somaxconn和tcp_max_syn_backlog两个值来达到想要的效果。
echo 511 > /proc/sys/net/core/somaxconn
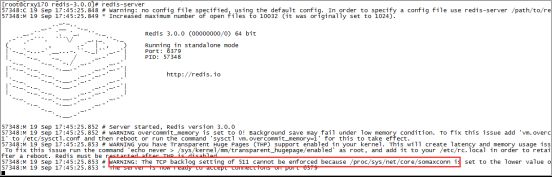
注意:这个参数并不是限制redis的最大链接数。如果想限制redis的最大连接数需要修改maxclients,默认最大连接数为10000。
限制redis的内存大小和数据淘汰策略
通过redis的info命令查看内存使用情况
如果不设置maxmemory或者设置为0,64位系统不限制内存,32位系统最多使用3GB内存。
1. maxmemory:最大内存
2. maxmemory-policy:内存不足时,数据清除策略
3. 设置数据的超时时间,expire,expireat, pexpire, pexpireat
maxmemory应设置多大
1. 如果使用了快照方式,应该设置为服务器内存的45%,由于快照也要用45%,(45 + 45 + 5 = 90),5%是预留的消耗
2. 如果没有设置快照,可以设置为服务器内存的95%
如何选择maxmemory-policy
1. 如果设置了超时时间,“volatile-ttl”比较合适
2. 如果没有这是超时时间,“allkeys-lru”比较合适
淘汰策略如下:
1. volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用 的数据淘汰
2. volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数 据淘汰
3. volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据 淘汰
4. allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
5. allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
6. no-enviction(驱逐):禁止驱逐数据
如何选择
1. 如果可以确定数据总量不大,并且内存足够的情况下不需要限制redis使用的内存大小。
2. 如果数据量不可预估,并且内存也有限的话,尽量限制下redis使用的内存大小,这样可以避免redis使用swap分区或者出现OOM错误。
注意:如果不限制内存,当物理内存使用完之后,会使用swap分区,这样性能较低,如果限制了内存,当到达指定内存之后就不能添加数据了,否则会报OOM错误。可以设置maxmemory-policy,内存不足时删除数据。
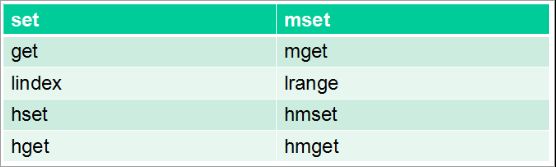
使用管道技术
Redis是个单线程模型,客户端过来的命令是按照顺序执行的,所以想要一次添加多条数据的时候可以使用管道,或者使用一次可以添加多条数据的命令,例如:
关闭Redis的VM选项
这个本来是作为Redis存储超出物理内存数据的一种数据在内存与磁盘换入换出的一个持久化策略,但是其内存管理成本也非常的高,并且我们后续会分析此种持久化策略并不成熟,所以要关闭VM功能,请检查你的redis.conf文件中 vm-enabled 为 no。
redis的紧凑存储格式
Redis Hash是value内部为一个HashMap,如果该Map的成员数比较少,则会采用类似一维线性的紧凑格式来存储该Map, 即省去了大量指针的内存开销。如果数据比较多或比较大的情况下,就会用回HashMap。
hash-max-zipmap-entries 64
含义是当value这个Map内部不超过多少个成员时会采用线性紧凑格式存储,默认是64,即value内部有64个以下的成员就是使用线性紧凑存储,超过该值自动转成真正的HashMap。
hash-max-zipmap-value 512
含义是当 value这个Map内部的每个成员值长度不超过多少字节就会采用线性紧凑存储来节省空间。
hash-max-zipmap-entries
注意:
前面两条任意一条不满足,就会使用HashMap
其他数据结构也有同样的紧凑存储格式
list-max-ziplist-value 64
list-max-ziplist-entries 512
set-max-intset-entries 512
redis shared integer
Redis内部实现没有对内存分配方面做过多的优化,在一定程度上会存在内存碎片,不过大多数情况下这个不会成为Redis的性能瓶颈,不过如果在Redis内部存储的大部分数据是数值型的话,Redis内部采用了一个shared integer的方式来省去分配内存的开销,即在系统启动时先分配一个从1~n 那么多个数值对象放在一个池子中,如果存储的数据恰好是这个数值范围内的数据,则直接从池子里取出该对象,并且通过引用计数的方式来共享,这样在系统存储了大量数值下,也能一定程度上节省内存并且提高性能,这个参数值n的设置需要修改源代码中的一行宏定义REDIS_SHARED_INTEGERS,该值默认是10000,可以根据自己的需要进行修改,修改后重新编译就可以了。
参考
http://blog.csdn.net/u011204847/article/details/51302109#
http://www.infoq.com/cn/articles/tq-redis-memory-usage-optimization-storage/
已有 0 人发表留言,猛击->> 这里<<-参与讨论
ITeye推荐
- —软件人才免语言低担保 赴美带薪读研!—