Lucene 初探
1.1 Lucene 是什么
Lucene是一款信息检索工具库或者全文检索库。
1.2 Lucene能做些什么
Lucene只是一个软件类库或者工具箱,并不是一个完整的文件搜索程序,或者网页搜索器以及网站搜索引擎。很多完整的搜索程序都是基于lucene这个核心来运行
1.3 结构化数据、半结构化数据,非结构化数据
结构化数据:指具有固定格式或有限长度的数据,比如数据库
非结构化数据:指不具有固定格式或者不定长的数据,比如邮件,word文档等,也可以称之为全文数据
半结构化数据:指根据需要可以按照结构化数据来处理的数据,也可以抽取出纯文本按照非结构化数据来处理,如HTML,XML
1.4 全文数据(非结构化数据)的检索方式
1.4.1 顺序扫描法:SerialScanning,一个文档一个文档的的找要搜索的字符串,每一个文档从头看到尾,如果此文档包含我们要找的字符串,则此文档为我们要找的文件,然后接着看下一个文件,直到扫描完所有的文件。
1.4.2 全文检索法:Full-Text Search, 通过先建立索引,然后再对索引进行搜索的过程就是全文检索
1.5 什么是索引
索引:非结构化数据提取出来然后进行重新组织的信息
正向索引:从文档到字符串的映射
反向索引:从字符串到文档的映射
1.6 全文检索的过程
1.6.1 创建索引:对结构化,非结构化或者半结构化数据提取信息,
1.6.2 搜索索引:得到搜索的请求,然后搜索创建的索引,然后返回结果
1.7 索引里存在些什么
假设我们文档集合里有100篇文档,为了方便表示,我们为文档号从1到100
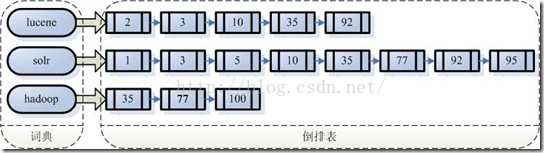
左边保存的字符串,称之为字典
每一个字符串都指向一个包含该字符串的一个文档链表,这个文档链表称之为倒排表(Posting List)
此时比如我要搜索lucene solr,那么步骤是:
取出包含字符串"lucene"的文档链表
取出包含字符串"solr"的文档链表
合并链表,找出既包含lucene又包含solr的文档

1.8如何创建索引
1.8.1准备要创建索引的源数据
1.8.2源数据传给分词组件Tokenizer:
Tokenizer会做以下几件事情,这个过程称为tokenize:
1.8.2.1 将源数据分成一个一个单独的词
1.8.2.2去除标点符号
1.8.2.3 去除停用词(stopword)
比如有这样的一个句子:Nicky, a student, who is reading
Newspaper.
分词之后的结果:
"Nicky" "student" "reading""newspaper"
1.8.3将得到的词元Token传给语言处理组件Linguistic Processer
语言处理组件,主要是针对词元进行一些语言相关处理,比如英语为例:
1.8.3.1将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming(词干提取)
1.8.3.2 将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization(词形还原)
1.8.3.3 大写转小写
缩写词元转化过后应该是:
"nicky" "student" "read" "newspaper"
这时候得到的这些称之为Term(词)
注意:词干提取和词性还原不是独立的,可能会有交集,比如driving 变为 drive,两者都可以做到
1.8.4将得到的词Term传给索引组件Indexer
1.8.4.1 首先利用得到的词创建一个字典
| Term |
DocumentID |
| lucene |
1 |
| solr |
1 |
| dimensions |
2 |
| lucene |
2 |
| action |
2 |
| solr |
3 |
| dimension |
3 |
| solor |
3 |
| solr |
3 |
| Search |
4 |
| number |
4 |
| number |
4 |
| lucene |
4 |
1.8.4.2 对词进行字典顺序排序
| Term |
DocumentID |
| action |
2 |
| dimensions |
2 |
| dimensions |
3 |
| lucene |
1 |
| lucene |
2 |
| lucene |
4 |
| number |
4 |
| number |
4 |
| search |
4 |
| solr |
1 |
| solr |
3 |
| solr |
3 |
| solr |
3 |
1.8.4.3 合并相同的词成为文档倒排表
| Term |
Document Frequency |
| action |
1 |
| dimensions |
2 |
| lucene |
3 |
| number |
1 |
| search |
1 |
| solr |
2 |
| Term |
Frequency |
| action |
1 |
| dimensions |
2 |
| lucene |
3 |
| number |
2 |
| search |
1 |
| solr |
4 |
Document Frequency: 这个词出现在了几个文档中
Term Frequency:一个文档这个词出现了多少次
1.9 如何对索引进行搜索
1.9.1搜索主要分为以下几个步骤:
1.9.2用户输入查询语句
词法分析:词法分析主要是识别关键字和单词
语法分析:根据查询语句语法形成一个语法树,如果发现查询不满足语法规则则会报错,比如Lucene NOT AND Hadoop,比如以下查询语句形成的语法树:
lucene AND solr NOT endeca

1.9.3对查询语句进行词法和语法分析及语言处理
语言处理过程同索引的语言处理过程是一样的,大写转小写,然后进行词干提取或者词性还原
1.9.4搜索索引,得到符合语法树的文档
首先:找到包含lucene solr endeca的文档
其次:对包含lucene andsolr的链表进行合并操作,得到既
包含lucene,又包含solr的链表,然后将此链表与包含endeca
的链表进行查操作,去掉包含endeca文档链表
最后:得到我们需要的文档链表
1.9.5根据得到的文档和查询语句的相关性,对结果进行排序
我们应该需要对返回的文档进行打分,分数高的相关性好,应
该排在前面,如何打分呢?
我们需要先了解一下如何判断文档之间的关系:
首先:一个文档有很多词(Term)组成,如endeca lucene solr 等
其次:对于文档之间的关系,不同的term重要性不同,比如对于本篇文档,endeca lucene solr稍微重要些,其他的词显得不那么重要,如果两篇文档都包含endeca lucene solr,这两篇文档的相关性好一些,就算一文档包含其他的词,两外一个文档不包含那些其他的词,也不会影响两篇文档的相关性。所以判断文档之间的关系,首先找出哪些词对文档之间的关系最重要,如endeca solr lucene,然后判断这些词之间的关系。
找出词对文档重要性的过程称为计算词的权重(Term Weight)的过程。
对于计算此的权重,有两个必不可少的因素: 词 和 文档。
词的权重:表示词在此文档重要程度,越重要的词有越大权重,因而在计算文档之间的相关性中将发挥更大的作用
根据判断词之间的关系从而得到文档相关性的过程会应用一种叫做向量空间模型的算法(vector space model)
在下一个章节我会做一个详细的讨论。此处略过。
2 总结
2.1索引过程
有一系列被索引文件
被索引文件经过语法分析和语言处理形成一系列词(Term)。
经过索引创建形成词典和反向索引表。
通过索引存储将索引写入硬盘。
2.2 搜索过程
用户输入查询语句。
对查询语句经过语法分析和语言分析得到一系列词(Term)。
通过语法分析得到一个查询树。
通过索引存储将索引读入到内存。
利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交集,差集,并得到结果文档。
将搜索到的结果文档对查询的相关性进行排序。
返回查询结果给用户