这才是真正的分布式锁
昨晚十点下班,回家花了1个小时写了一篇《一分钟实现分布式锁》,引起读者一些反响,有些朋友反馈“setnx算什么方案”,“没有考虑超时”,“为啥不用zookeeper”,有甚者上升到 “质疑58同城的技术水平”,“拉低了架构师的层次”,“适合小学生阅读”。
给58带来负面的影响实在对不起公司,也抱歉耽误部分同学1分钟时间(还好是1分钟系列),不过大部分读者的反馈是正向的,只生气了5分钟。
技术领域,我觉得了解来龙去脉,了解本质原理,比用什么工具实现更重要:
(1)进程多线程如何互斥?
(2)一个手机上两个APP访问一个文件如何互斥?
(3)分布式环境下多个服务访问一个资源如何互斥?
归根结底,是利用一个互斥方能够访问的公共资源来实现分布式锁,具体这个公共资源是redis来setnx,还是zookeeper,相反没有这么重要。
言归正传,今天把昨天文章的缘起讲一讲,并通过Google Chubby的论文阅读笔记聊一聊分布式锁。
一、需求缘起
58到家APP新上线了导入通讯录好友功能,测试的同学发现,连续点击导入会导入重复数据:
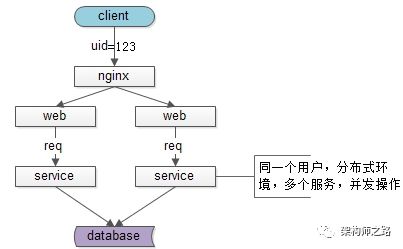
客户端同一个用户同时发出了多个请求,分布式环境下,多台机器上部署的多个service进行了并发操作,故插入了冗余数据。
解决思路:同一个用户同时只能有一个导入请求,需要做互斥,最简易的方案,使用setnx快速解决。
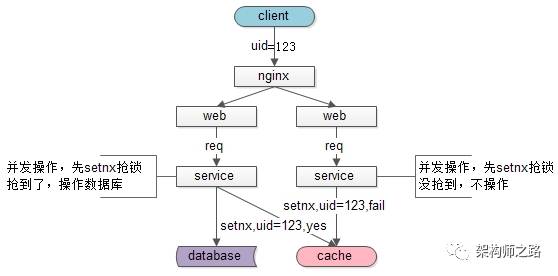
(1)同一个用户,多个service进行并发操作,service需要先去抢锁
(2)抢到锁的service,才去数据库操作
具体这个锁用setnx,还是zookeeper都不太重要,利用一个互斥方能够访问的公共资源来实现分布式锁,这才是《一分钟实现分布式锁》的重点。
二、Google Chubby分布式锁阅读笔记
上一篇文章的评论中,有些朋友提到了zookeeper,会使用不够,借着Google Chubby了解下分布式锁的实现也是有必要的。
早年Google的四大基础设施,分别是GFS、MapReduce、BigTable、Chubby,其中Chubby用于提供分布式的锁服务。
1.简介
Chubby系统提供粗粒度的分布式锁服务,Chubby的使用者不需要关注复杂的同步协议,而是通过已经封装好的客户端直接调用Chubby的锁服务,就可以保证数据操作的一致性。
Chubby具有广泛的应用场景,例如:
(1)GFS选主服务器;
(2)BigTable中的表锁;
2.背景
Chubby本质上是一个分布式文件系统,存储大量小文件。每个文件就代表一个锁,并且可以保存一些应用层面的小规模数据。用户通过打开、关闭、读取文件来获取共享锁或者独占锁;并通过反向通知机制,向用户发送更新信息。
3.系统设计
3.1设计目标
Chubby系统设计的目标基于以下几点:
(1)粗粒度的锁服务;
(2)高可用、高可靠;
(3)可直接存储服务信息,而无需另建服务;
(4)高扩展性;
在实现时,使用了以下特性:
(1)缓存机制:客户端缓存,避免频繁访问master;
(2)通知机制:服务器会及时通知客户端服务变化;
3.2整体架构
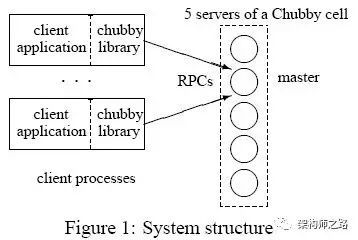
Chubby架构并不复杂,如上图分为两个重要组件:
(1)Chubby库:客户端通过调用Chubby库,申请锁服务,并获取相关信息,同时通过租约保持与服务器的连接;
(2)Chubby服务器组:一个服务器组一般由五台服务器组成(至少3台),其中一台master,服务维护与客户端的所有通信;其他服务器不断和主服务器通信,获取用户操作。
4.系统实现
4.1文件系统
Chubby文件系统类似于简单的unix文件系统,但它不支持文件移动操作与硬连接。文件系统由许多Node组成,每个Node代表一个文件,或者一个目录。文件系统使用Berkeley DB来保存每个Node的数据。文件系统提供的API很少:创建文件系统、文件操作、目录操作等简易操作。
4.2基于ICE的Chubby通信机制
一种基于ICE的RPC异步机制,核心就是异步,部分组件负责发送,部分组件负责接收。
4.3客户端与master的通信
(1)长连接保持连接,连接有效期内,客户端句柄、锁服务、缓存数据均一直有效;
(2)定时双向keep alive;
(3)出错回调是客户端与服务器通信的重点。
下面将说明正常、客户端租约过期、主服务器租约过期、主服务器出错等情况。
(1)正常情况
keep alive是周期性发送的一种消息,它有两方面功能:延长租约有效期,携带事件信息告诉客户端更新。正常情况下,租约会由keep alive一直不断延长。
潜在回调事件包括:文件内容修改、子节点增删改、master出错等。
(2)客户端租约过期
客户端没有收到master的keep alive,租约随之过期,将会进入一个“危险状态”。由于此时不能确定master是否已经终止,客户端必须主动让cache失效,同时,进入一个寻找新的master的阶段。
这个阶段中,客户端会轮询Chubby Cell中非master的其他服务器节点,当客户端收到一个肯定的答复时,他会向新的master发送keep alive信息,告之自己处于“危险状态”,并和新的master建立session,然后把cache中的handler发送给master刷新。
一段时间后,例如45s,新的session仍然不能建立,客户端立马认为session失效,将其终止。当然这段时间内,不能更改cache信息,以求保证数据的一致性。
(3)master租约过期
master一段时间没有收到客户端的keep alive,则其进入一段等待期,此期间内仍没有响应,则master认为客户端失效。失效后,master会把客户端获得的锁,机器打开的临时文件清理掉,并通知各副本,以保持一致性。
(4)主服务器出错
master出错,需要内部进行重新选举,各副本只响应客户端的读取命令,而忽略其他命令。新上任的master会进行以下几步操作:
a,选择新的编号,不再接受旧master的消息;
b,只处理master位置相关消息,不处理session相关消息;
c,等待处理“危险状态”的客户端keep alive;
d,响应客户端的keep alive,建立新的session,同时拒绝其他session相关操作;同事向客户端返回keep alive,警告客户端master fail-over,客户端必须更新handle和lock;
e,等待客户端的session确认keep alive,或者让session过期;
f,再次响应客户端所有操作;
g,一段时间后,检查是否有临时文件,以及是否存在一些lock没有handle;如果临时文件或者lock没有对应的handle,则清除临时文件,释放lock,当然这些操作都需要保持数据的一致性。
4.4服务器间的一致性操作
这块考虑的问题是:当master收到客户端请求时(主要是写),如何将操作同步,以保证数据的一致性。
(1)节点数目
一般来说,服务器节点数为5,如果临时有节点被拿走,可预期不久的将来就会加进来。
(2)关于复制
服务器接受客户端请求时,master会将请求复制到所有成员,并在消息中添加最新被提交的请求序号。member收到这个请求后,获取master处被提交的请求序号,然后执行这个序列之前的所有请求,并把其记录到内存的日志里。如果请求没有被master接受,就不能执行。
各member会向master发送消息,master收到>=3个以上的消息,才能够进行确认,发送commit给各member,执行请求,并返回客户端。
如果某个member出现暂时的故障,没有收到部分消息也无碍,在收到来自master的新请求后,主动从master处获得已执行的,自己却还没有完成的日志,并进行执行。
最终,所有成员都会获得一致性的数据,并且,在系统正常工作状态中,至少有3个服务器保持一致并且是最新的数据状态。
4.5Chubby系统锁机制
客户端和服务器除了要保存lease对象外,服务器和客户端还需要保存另一张表,用于描述已经加锁的文件及相关信息。由于Chubby系统所使用锁是建议性而非强制性的,这代表着如果有多个锁请求,后达的请求会进入锁等待队列,直到锁被释放。
5.Chubby使用例子(重点)
5.1选master
(1)每个server都试图创建/打开同一个文件,并在该文件中记录自己的服务信息,任何时刻都只有一个服务器能够获得该文件的控制权;
(2)首先创建该文件的server成为主,并写入自己的信息;
(3)后续打开该文件的server成为从,并读取主的信息;
5.2进程监控
(1)各个进程都把自己的状态写入指定目录下的临时文件里;
(2)监控进程通过阅读该目录下的文件信息来获得进程状态;
(3)各个进程随时有可能死亡,因此指定目录的数据状态会发生变化;
(4)通过事件机制通知监控进程,读取相关内容,获取最新状态,达到监控目的;
6.总结
Google Chubby提供粗粒度锁服务,它的本质是一个松耦合分布式文件系统;开发者不需要关注复杂的同步协议,直接调用库来取得锁服务,并保证了数据的一致性。
最后要说明的是,最终Chubby系统代码共13700多行,其中ice自动生成6400行,手动编写约8000行,这就是Google牛逼的地方:强大的工程能力,快速稳定的实现,然后用来解决各种业务问题。
==【完】==
如果没有时间读完,看看文末“选master”和“进程监控”两个例子,对理解“利用一个互斥方能够访问的公共资源来实现分布式锁”应该有帮助。本篇只是读书笔记,了解更多细节可查阅Google的论文。
相关阅读:巧用CAS解决数据一致性问题