深度学习小白——卷积神经网络可视化(一)
0.前言
对于卷积网络的可视化,我们使用的主要手段就是反卷积,通过反卷积,我们可以
- Understanding:对于网络中任意神经元的最优化激活的可视化
- Inverting:将分类层之前的code重建出图像
- Fun: deep dream & neutral Style
- Confusion and Chaos: adversarial examples
1、可视化最大激活神经元的一些pathces
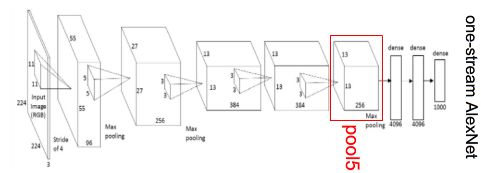
例如在这个AlexNet的pool5层任选一个神经元,然后喂给它大量的图片,看哪种图片最能激活该神经元

比如上面两行代表使神经元激活值最大的一些图片,白框是感受野,数值即为激活值,第一个神经元似乎对人很敏感,下面那个对dots或狗狗比较敏感
2. 对weights的观察
我们还可以对卷积第一层的raw filters 进行可视化,可以看到一些gabor like filters(Gabor函数是一个用于边缘提取的线性滤波器)

但是只有在第一层卷积层才能看到这样,因为它是直接对原始图像激活产生的,而其他层都是在上一层上做处理,所以可解释性会变差。但是这样的gabor-like filter并没有什么实际用途。
3. 对representation的可视化
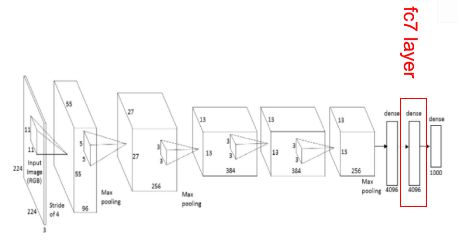
在分类之前,我们对这个4096维的code进行可视化,每一张图片喂进去都可以得到这个4096维的特征向量,这个特征向量是对该图片的一个概括。
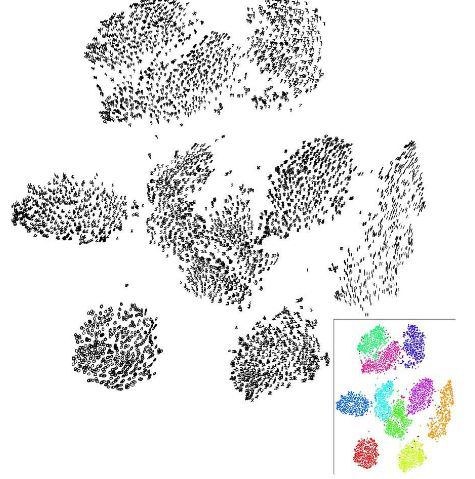
【t-SNE】可视化技术
给它一个高维数据,它可以根据数据内在关系自动聚集在一个二维平面,把相似的图片聚在一起,如将整个MNIST数据集每张图28*28=784维向量喂进去,它会聚集成10类,0-9个数字
4.遮挡实验
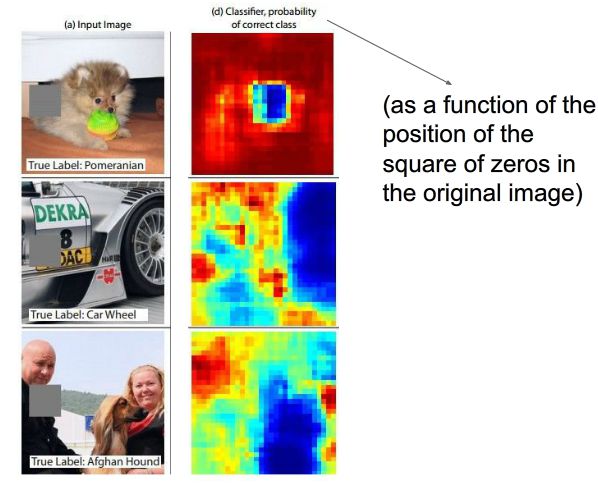
通过将遮挡块在原图像上滑动,得到正确分类概率关于遮挡块位置的函数,用热量图的形式来可视化这个过程,热量高表示正确分类的概率高,反之热量低就表明此处正确分类概率低。从热量图中可以看到对于第一幅图狗的脸对于识别狗很重要,第二幅图识别车的话轮子很重要。而第三幅图是识别阿富汗猎犬,当挡住左侧人的时候,识别正确率提高,说明卷积网络更加明确要识别的类别。
5. Visulizing Acitivations
通过Deep Visulization Toolbox,可以看到每一层每一个神经元对某一图片的激活反映
http://yosinski.com/deepvis 官方网站
https://www.youtube.com/watch?v=AgkfIQ4IGaM介绍视频
这个工具运用了一种是反卷积实现(Deconv)还有一种是优化实现
5.1 Deconv approaches——cs231n &
反卷积可以突出用于激活某一个卷积层的神经元的图像的一个特定部分。
它是可视化特定卷积层的操作
论文出处:
[Visualizing and Understanding Convolutional Networks, Zeiler and Fergus 2013]
[Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps, Simonyan et al., 2014]
[Striving for Simplicity: The all convolutional net, Springenberg, Dosovitskiy, et al., 2015]
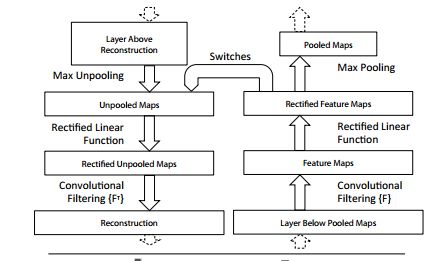
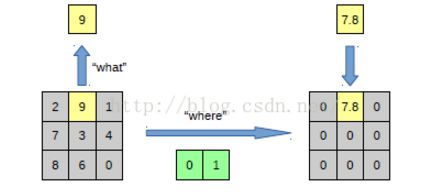
- 反池化过程
首先考虑如何计算任意一个神经元的梯度:先进行前向传播到该神经元那一层,得到激活值后,将那一层除我们关注的那一个神经元外其余神经元的梯度都设为0,把我们感兴趣的神经元梯度设为1.00,然后从这点开始运行反向传播,最终计算出输入对该神经元的影响情况。
但如果单纯用反向传播,我们将得到一个可解释性不是很好的图片
 ,但Deconv approaches改变了反向传播的方式,用guided backpropagation,就可以得到一个更清晰的图片。
,但Deconv approaches改变了反向传播的方式,用guided backpropagation,就可以得到一个更清晰的图片。
说明该神经元受猫的头像的影响。
【工作原理】
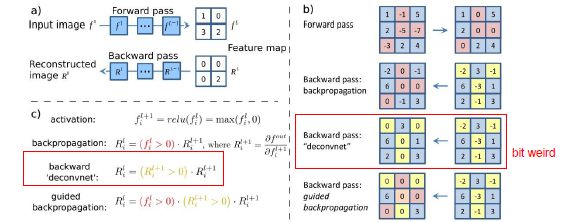
通过干预ReLU层后向传播过程来使得重建图片更加清晰。ReLU层是一个阈值为0的一个筛选层max(f(x),0),在普通的后向传播时,ReLU层阻断了所有含有负的激活值的梯度,只传递正激活值的梯度。在【guided backpropagation 】中,让ReLU层只通过那些有正激活值且激活值中拥有正梯度的部分。
【deconvnet】是不考虑ReLU激活值,只通过正的梯度值
因为负梯度的含义是:该输入图像对该神经元的激活值有负影响。修正ReLU层的意义就在于我们只让对该神经元激活值有正影响的梯度通过,而阻断负影响。这也就是为什么普通反向传播得到的重建图像是不清晰的。有的像素对该神经元起正影响,有的则是负影响。
 第一层是一些边缘信息,第二层有了一些纹理信息
第一层是一些边缘信息,第二层有了一些纹理信息 第三层有些神经元变成了蜂巢状,或是汽车
第三层有些神经元变成了蜂巢状,或是汽车 4,5层得到了更高层的抽象形状
4,5层得到了更高层的抽象形状
对于每一个feature map显示9个激活值最高的图片,可以看出每一个feature map都对不同的图片“感兴趣”。有一些图片我们看上去有很大不同,但feature map却关注的是其中不变的部分,比如layer 5第一行第二列,它关乎的是背景的草地,而不是前景的物体。

上图展示了各层特征在训练迭代次数增加时激活值对应特征变化情况。可以看出底层的卷积最先收敛,高层的特征需要充分的迭代训练后才能收敛
5.2 优化方法Optimization to Image——《Deep Inside Convolutional Networks: VisualisingImage Classification Models and Saliency Maps》
【与Deconv的不同】
可被应用到任何层,不仅仅是卷积层,如论文中最后的全连接层。
可视化的是有关类别的概念,而不是针对某一张图
保持所有网络结构不变,只是优化图像。
目标就是找到一个图片I,使得一个分类的Score达到最大
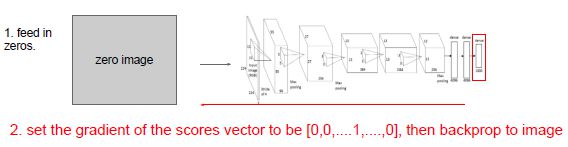

把一个全0的图片输入进网络,得到分数,由于我们对某些类感兴趣,想要提升该类的分数,于是我们把该类的分数的梯度设为1,其余设为0,然后进行普通反向传播,来决定对图像做什么样的更改。

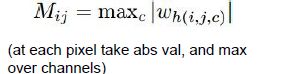
 该方法可以区分每个像素对分类得分的影响,黑色就是影响很小区域。
该方法可以区分每个像素对分类得分的影响,黑色就是影响很小区域。