python简单预测模型
步骤1:导入所需的库,读取测试和训练数据集。
#导入pandas、numpy包,导入LabelEncoder、random、RandomForestClassifier、GradientBoostingClassifier函数
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
import random
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
#读取训练、测试数据集
train=pd.read_csv('C:/Users/AnalyticsVidhya/Desktop/challenge/Train.csv')
test=pd.read_csv('C:/Users/AnalyticsVidhya/Desktop/challenge/Test.csv')
#创建训练、测试数据集标志
train='Train'
test='Test'
fullData =pd.concat(,axis=0) #联合训练、测试数据集
步骤2:该框架的第二步并不需要用到python,继续下一步。
步骤3:查看数据集的列名或概要
fullData.columns # 显示所有的列名称
fullData.head(10) #显示数据框的前10条记录
fullData.describe() #你可以使用describe()函数查看数值域的概要
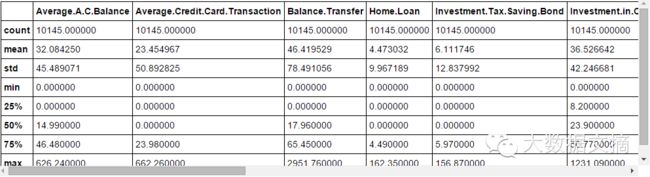
步骤4:确定a)ID变量 b)目标变量 c)分类变量 d)数值变量 e)其他变量。
ID_col =
target_col =
cat_cols =
num_cols= list(set(list(fullData.columns))-set(cat_cols)-set(ID_col)-set(target_col)-set(data_col))
other_col= #为训练、测试数据集设置标识符
步骤5:识别缺失值变量并创建标志
fullData.isnull().any()#返回True或False,True意味着有缺失值而False相反
num_cat_cols = num_cols+cat_cols # 组合数值变量和分类变量
#为有缺失值的变量创建一个新的变量
# 对缺失值标志为1,否则为0
for var in num_cat_cols:
if fullData.isnull().any()=True:
fullData=fullData.isnull()*1
步骤6:填补缺失值
#用均值填补数值缺失值
fullData = fullData.fillna(fullData.mean(),inplace=True)
#用-9999填补分类变量缺失值
fullData = fullData.fillna(value = -9999)
步骤7:创建分类变量的标签编码器,将数据集分割成训练和测试集,进一步,将训练数据集分割成训练集和测试集。
#创建分类特征的标签编码器
for var in cat_cols:
number = LabelEncoder()
fullData = number.fit_transform(fullData.astype('str'))
#目标变量也是分类变量,所以也用标签编码器转换
fullData = number.fit_transform(fullData.astype('str'))
train=fullData='Train']
test=fullData='Test']
train = np.random.uniform(0, 1, len(train)) <= .75
Train, Validate = train=True], train=False]
步骤8:将填补和虚假(缺失值标志)变量传递到模型中,我使用随机森林来预测类。
features=list(set(list(fullData.columns))-set(ID_col)-set(target_col)-set(other_col))
x_train = Train.values
y_train = Train.values
x_validate = Validate.values
y_validate = Validate.values
x_test=test.values
random.seed(100)
rf = RandomForestClassifier(n_estimators=1000)
rf.fit(x_train, y_train)
步骤9:检查性能做出预测
status = rf.predict_proba(x_validate)
fpr, tpr, _ = roc_curve(y_validate, status)
roc_auc = auc(fpr, tpr)
print roc_auc
final_status = rf.predict_proba(x_test)
test=final_status
test.to_csv('C:/Users/Analytics Vidhya/Desktop/model_output.csv',columns=)