机器学习面试题整理
-
https://blog.csdn.net/u010976453/article/details/78488279
-
https://blog.csdn.net/woaidapaopao/article/details/77806273
-
https://blog.csdn.net/woaidapaopao/article/details/77806273
-
请简要介绍下SVM
SVM叫做支持向量机,它的目标是为确定一个分类超平面,从而将不同的数据分隔开
支持向量机分类:
支持向量机分为三种,线性可分支持向量机,线性支持向量机以及非线性支持向量机,当训练数据线性可分时,通过最大化硬间隔,学习一个线性分类器,这种称之为线性可分支持向量机(硬间隔支持向量机);(所谓硬间隔就是线性可分)当训练数据近似线性可分时,通过最大化软间隔,也学习一个线性分类器,即线性支持向量机,当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机
-
请介绍Tensorflow计算图
tensorflow是一个通过计算图的形式来表述计算的编程系统,可以把计算图看做一种有向图,tf中每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系
-
请问GBDT和XGBoosts的区别是什么
首先介绍一下boosting思想,每次训练单个弱分类器时,都将上一次分错的数据权重提高一点再进行当前单个弱分类器
的学习,这样往后执行,训练出来的单个弱分类器就会越在意那些容易分错的点,最终通过加权求和的方式组合成一个最终的学习器
gradent boosting 是boosting的一种,每一次构建单个学习器时,是在之前建立的模型的损失函数的梯度下降方向, GB与Adaboost的区别在于:
AdaBoost是通过提升错分数据点的权重来定位模型的不足
Gradient Boosting是通过算梯度(gradient)来定位模型的不足
主要思想是,每一次建立单个学习器时,是在之前建立的模型的损失函数的梯度下降方向,损失函数越大,说明模型越容易出错,如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不停的改进,而最好的方式就是让损失函数在其梯度方向上下降
GBDT=GB+DT(decision tree),即基分类器为决策树时,这里的决策树是回归树
Xgboost 是GB算法的高效实现,其中基分类器除了可以使CART也可以是线性分类器
几大区别:
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯帝回归或者线性回归
- 传统GBDT在优化时只用到了一阶导数,而xgboost对代价函数进行了二阶泰勒展开,用到了一阶和二阶导数
- xgboost加入了正则项,防止过拟合
- shrinkage,相当于学习率,在每完成一次迭代后,会乘上这个系数,削减每棵树的影响
- 列抽样,借鉴随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算
-
在k-means与kNN,我们用的是欧氏距离来计算最近的邻居之间的距离。为什么不用曼哈顿距离
曼哈顿距离只计算水平或者垂直距离,有维度的限制,而欧氏距离可用于任何空间的距离计算问题,因为,数据点可以存在于任何空间,如国际象棋棋盘,象和车所做的移动是由曼哈顿距离计算的,因为他们是在各自的水平和垂直方向做的运动
-
简单说说特征工程
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程,从数学的角度来讲,特征工程就是人工地去设计输入变量X
-
拼写检查
浏览器中输入区欧盟,输入错误,会被拼写检查为去欧盟,实际上原理是采用了贝叶斯原理,由贝叶斯公式可知P(c|w),w表示拼写错误的情况,而c表示实际想要拼写的单词,等于P(w|c)*P(c)/P(w),也就是在若干备选中选择最大的P(c|w),而P(w)都是相同的,即找到使得P(w|c)*P(c)最大的单词,而P(c)可由文本库中各单词出现频率确定,而P(w|c)表示想要输出c而实际输出w的概率,可以用两个单词的相似度来表示,字形或者读音,越接近出错的概率越高,以此来选择概率最大的单词
-
简要说说一个完整机器学习项目的流程
- 抽象成数学问题(确定是一个分类问题、回归问题还是聚类问题,明确可以获得什么样的数据)
- 获取数据(数据要具有代表性,对数据的量级也要有一个评估,多少样本,多少特征,对内存的消耗,考虑内存是否能放得下,如果放不下考虑降维或者改进算法,如果数据量太大,考虑分布式)
- 特征预处理和特征选择(数据清洗,归一化、缺失值处理、去除共线性等,另外筛选出显著特征、反复理解业务,有时候数据特征选择的好,依靠简单的算法也能得出良好稳定的结果,需要进行特征有效性分析,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法)
- 训练模型与调优(现在很多算法都已经封装成黑箱供人使用,正则考察的是调参的技术,需要对算法额原理深入理解,能发现问题的症结,来提出良好的调优方案)
- 模型诊断(确定调优的方向,如欠拟合 过拟合这种情况,一般过拟合是增加数据量和降低模型复杂度的思路,欠拟合是增加特征,增加模型复杂度)
- 模型融合(一般提升模型主要在前期的数据清洗和预处理部分,以及后面的模型融合下功夫,有时候会通过在已有预训练模型上进行再融合和调参节省时间,并能取得不错的效果)
- 上线运行(模型在线上运行效果直接决定模型的成败,运行的速度、资源消耗成都、稳定性等是否可以接受)
-
哪些机器学习算法不需要做归一化处理
概率模型不需要归一化,因为他们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、GBDT、SVM、LR、KNN、KMeans之类的最优化问题就需要归一化
-
如何解决梯度消失和梯度膨胀
梯度消失:根据链式法则,当每一层神经元对上一层的输出的偏导乘上权重结果都小于1的话,那么即使这个结果是0.99,经过多层传播之后,误差的输入层的偏导会趋于0,可以用relu激活函数来解决,因为relu=max(0,X),偏导数为1,不会造成梯度消失,而弊端是有可能会产生死神经元
梯度膨胀:每一层神经元对上一层的输出偏导乘上权重结果都大于1的话,经过多层传播之后,误差对输入层的偏导会无穷大,也可以通过激活函数来解决
-
为什么朴素贝叶斯如此朴素
因为朴素贝叶斯有个重要的假设前提,也就是假设样本的所有特征之间是相互独立的,而这个在现实世界中是不真实的,因此说其很朴素
-
在机器学习中,为何要经常对数据归一化
归一化可以:
- 归一化后加快了梯度下降求最优解的速度(两个特征量纲不同,差距较大时,等高线较尖,根据梯度下降可能走之字形,而归一化后比较圆走直线)
- 归一化有可能提高精度 (一些分类器需要计算样本之间的距离,如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,这是不合理的)
-
关于LR
-
关于SVM
-
关于GBDT
-
LR与SVM的联系与区别
- LR与SVM都可以处理分类问题,且一般都可以用于线性二分类问题
- 两个方法都可以增加不同的正则化项
区别:
- LR是参数模型,SVM是非参数模型(参数模型是假设总体服从某一个分布,该分布由一些参数确定,在此基础上构建的模型为参数模型,而非参数模型对于总体的分布不做假设,这里LR是提前假设了分布为伯努利分布即0,1分布,继而求解构建的极大似然函数)
- 从目标函数上看,LR采用logistical loss,SVM采用的是hinge loss
- SVM的处理方式是只考虑支持向量,而LR通过非线性映射,大大减少了离分类面较远的点的权重
- SVM分类预测只需要计算与少数几个支持向量的距离
- LR能做的SVM能做,但可能在准确率上有问题,SVM能做的RL有的做不了
-
LR与线性回归的区别
LR就是一种线性回归,经典线性回归模型的优化目标是最小二乘,而逻辑回归是似然函数,另外线性回归在整个实数域范围内进行预测,线性回归模型无法做到sigmoid的非线性形式,simoid可以轻松处理0/1分类问题
-
协方差与相关性的区别
相关性是协方差的标准化格式,协方差本身很难做比较,例如,如果我们计算工资和年龄的协方差,因为这两个变量有不同的度量,所以我们会得到不能做比较的不同的协方差,为了解决这个问题,我们计算相关性来得到一个介于-1和1之间的值,就可以忽略它们各自不同的度量
-
数据不平衡问题
这主要是由于数据分布不平衡造成的。解决方法如下:
- 采样,对小样本进行加噪声采样,对大样本进行下采样
- 进行特殊的加权,如在Adaboost中或者SVM
- 采用对不平衡数据集不敏感的算法
- 改变评价标准:用AUC|ROC来进行评价
- 考虑数据的先验分布
- https://blog.csdn.net/zxj942405301/article/details/78059719?fps=1&locationNum=5
-
什么是卷积
对图像和滤波矩阵做内积的操作就是所谓的卷积操作,也是卷积神经网络的名字来源
-
什么是CNN的池化pool层
池化指的是在区域内取平均或者最大
-
什么是生成对抗网络
GAN网络有两个重要的概念,一个是generator,主要作用是生成图片,尽量使其看上去来自于训练样本,一个是discriminator,主要作用是判断输入图片是否属于训练样本,所以这就是被称为对抗的网络,举例赝品家和鉴赏家
-
梯度下降法找到的一定是下降最快的方向么
并不是,它只是目标函数在当前的点的切平面上下降最快的方向,牛顿方向才一般被认为是下降最快的方向
-
批量梯度下降法
将当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,最优化总体样本数据的损失函数
-
随机梯度下降法
最小化每个样本的损失函数,迭代更新更快,但总体上是朝着整体最优前进的,与批量梯度下降的关系:
-
牛顿法
利用损失函数的二阶导数,收敛更快,不再是限于当前歩最优,有了往后看的整体概念,不过也没有整体的概念,只是在局部上更加细致,不过计算比较复杂,因为需要求解海森矩阵的逆矩阵比较复杂
-
共轭梯度法
共轭梯度法是介于梯度下降与牛顿法之间的一个方法,它仅需要求一阶导数,又避免了收敛慢的缺点,避免了牛顿法需要计算海森逆矩阵的缺点
-
人生苦短我用python,介绍下python与其他语言的区别
- python是动态类型,这意味着不需要在声明变量时指定类型
- python是面向对象的,有类的概念
- python写起来是很快,但跑起来会比较慢,不过可以用c拓展写,numpy就是一个很好的例子
- 使用场景多,web 大数据 人工智能 数据科学
- 能简化工作,使得可以关心重写代码而不用去详细地看底层实现
-
python怎么进行内存管理的
- 对象引用计数机制 一个对象会分配一个名称,使用del语句可以对对象别名进行销毁删除
- 垃圾回收机制 当对象的引用计数归零时会被本机制处理掉
- 内存池机制 然而每个对象都包含对另外一个对象的引用,因此引用计数归零也不会被销毁,因此会执行解释器定期执行周期检测器,搜索不可访问的对象删除它们
-
欧式空间与马氏空间
欧式空间具有平移不变性、旋转不变性,而马氏空间还具有尺度缩放不变性和不受量纲影响的特性
-
深度学习调参经验
- 参数初始化,uniform均匀分布初始化,normal高斯分布初始化
- 数据预处理,进行归一化,有几种常用方法
- 梯度归一,算出来的梯度除以minibatch size 还有梯度裁剪,限制梯度上限,dropout防过拟合,一般sgd,选择0.1的学习了,衰减型的,激活函数选择relu,还有使用batch normalization 对每一层计算出来的特征归一化
-
随机森林处理缺失值方法
对于训练集,同一个class下的数据,如果分类变量缺失,用众数填补,如果是连续变量缺失,用中位数填补
-
随机森林如何评估特征重要性
1. decrease gini 当前节点训练集的方差减去左节点方差和右节点方差
2. decrease accracy 对一棵树随机改变OOB样本的第j列得到误差1,保持其他列不变,对j列进行随机上下置换,得到误差2,误差之间的差距越大说明特征越重要
-
解释对偶概念
一个优化问题可以从两个角度进行考察,一个是primal问题,一个是dual问题,就是对偶问题,一般情况下对偶问题给出主问题最优值的下界,在强对偶性成立的情况下由对偶问题可以得到主问题的最优下界,对偶问题是凸优化问题,可以进行较好的求解,SVM中就是将主问题转换为对偶问题进行求解,从而引入核函数的思想
-
如何进行特征选择
1. 去除方差较小的特征
2. 正则化
3. 随机森林,分类问题,采用基尼不纯度或者信息增益,对于回归问题,通常采用方差或者最小二乘拟合
4. 稳定性选择
-
对比下sigmoid tanh relu三个激活函数
-
怎么理解决策树、xgboost能处理缺失值,而有的模型svm对缺失值比较敏感
-
衡量分类器好坏
-
推导反向传播
-
SVD和PCA
PCA的理念是使得数据投影后的方差最大,找到这样一个投影向量,满足方差最大的条件即可,而经过了去除均值的操作之后,就可以用SVD分解来求解这样一个投影向量,选择特征值最大的方向
-
卷积池化后大小计算公式
首先我们应该知道卷积或者池化后大小的计算公式:
out_height=((input_height - filter_height + padding_top+padding_bottom)/stride_height )+1
out_width=((input_width - filter_width + padding_left+padding_right)/stride_width )+1
-
什么是偏差和方差
泛化误差可以分解为偏差的平方加上方差加上噪声。
偏差度量了学习算法的期望预测和真实结果的偏离程度,刻画了学习算法本身的拟合能力
方差度量了同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动所造成的影响
噪声表达了当前任务上任何学习算法所能达到的期望泛化误差下界,刻画了问题本身的难度
偏差和方差一般称为bias和variance,一般训练程度越强,偏差越小,方差越大,泛化误差一般在中间有一个最小值,如果偏差较大,方差较小,此时一般称为欠拟合,而偏差较小,方差较大称为过拟合
-
SMO算法实现?
选择原凸二次规划的两个变量,其他变量保持不变,根据这两个变量构建一个新的二次规划问题,这样将原问题划分为更小的子问题可以大大加快计算速度,而选择变量的方式是:
其中一个是严重违反KKT条件的一个变量
另一个变量是根据自由约束确定的
-
xgboost并行体现在哪
xgboost并行并不是树粒度的并行,而是特征排序与其树迭代生成的并行,生成一个基分类器还是得依靠上一个分类器的结果对于损失函数的梯度得到的,但是决策树的每一个节点的分裂需要对特征值进行排序,因为需要找到最佳分割点,xgboost就将这个结果保存下来供之后的迭代使用实现特征上的并行
-
解释对偶
一个优化问题可以从两个角度进行考察,一个是主问题,一个是对偶问题,一般对偶问题给出的是问题最优值的下界,在KKT条件下可以进行转换,对偶问题是凸优化问题,可以进行很好的求解,svm就是将主问题转换为对偶问题求解,进一步引入核函数的思想
-
如何进行特征选择
特征选择一般有三种方式,过滤式、包裹式和嵌入式,过滤式常见的是深度学习中利用卷积核进行特征提取,整个训练过程是先进行特征提取,然后才开始学习,包裹式是将最终学习器的性能作为特征子集的评价准则,不断通过更新候选子集,然后利用交叉验证更新特征,计算量比较大,嵌入式是将特征选择和训练过程融为一体,在训练过程中自动进行了特征选择,例如L1正则,产生稀疏特征
-
归一化和标准化的区别
归一化:
1. 把数据变成(0,1)之间的小数
2. 把有量纲表达式变成无量纲表达
标准化:
将数据按比例缩放,去除数据单位的限制,将其转化为无量纲的纯数,便于不同单位或量级的指标能够进行比较和加权
-
为什么说朴素贝叶斯是高偏差低方差?
它简单假设了各个特征之间是无关的,是一个被严重简化了的模型,所以,对于这样一个简单模型,大部分场合都会bias部分大于variance部分,也就是高偏差低方差
-
业务题
-
给定一个1000列100万行的训练数据集,怎么进行降维
1. 对大样本进行抽样使其变为小样本
2.可以将分类变量和数值变量分开,同时删掉相关联的变量,对于数值变量,可以通过相关性分析来找到相关的特征,对于分类变量可以通过卡方检验来找到
3. 还可以通过PCA降维,获取包含最多方差的特征,也就是包含最多信息的特征
-
给定一个癌症检测的数据集,分好类,已经取得了96%的精度,为什么还是不满意模型的性能
因为癌症检测很明显是一个数据不均衡的数据集检验,我们往往对剩下的未被检测出的4%的数据更感兴趣,未被诊断出但是实际是患有癌症的患者数据:
办法:采用欠采样或者过采样,或者采用roc曲线来评判,数据分配权重
-
深度学习应用领域的共性
常用于图像、语音、自然语言处理等,这些领域有一个共性就是局部相关性,像素点组成图像,单词组成句子,这些特征元素一旦被打乱,表示的含义同时会发生变化,对于没有这种局部相关性的数据集,不适合用深度学习算法进行处理
python语言
-
这两个参数是什么意思:*args,**kwargs?我们为什么使用它们?
如果我们不确定要往一个函数中传入多少参数,或者我们希望以元祖或者列表的形式传参数时,我们可以使用*args。如果我们不知道要往函数中传递多少个关健词参数或者想传入字典的值作为关键词参数就可以用**kwargs。
-
谈一谈python的装饰器(decorator)
装饰器本质上是一个python函数,它可以让其他函数在不作任何变动的情况下增加额外功能,函数是对象,传入的是一个函数
-
python多线程(multi-threading).这是个好主意吗
python并不支持真正意义上的多线程,python提供了多线程包。python中有一个GIL的东西,能确保代码中只有一个线程在执行,经过GIL处理,如果是CPU密集型,即计算型,那么多线程没有任何作用,因为每次只执行一个线程,且没有用到多核的优势,而IO型,即交互较多,那么使用多线程比较方便,因为它们大部分时间都在等待
-
说明os sys模块不同,并列举常用的模块方法
os负责程序与操作系统的交互,sys负责程序与解释器的交互,提供了一系列的函数和变量用户操作python运行时的环境
os 常用方法
对文件的操作、目录的操作
os.remove(filename) os.walk() os.chmod 修改目录权限
sys常用方法
sys.exit() 退出程序 sys.stdin 标准输入 sys.version
-
什么是lambda表达式?它有什么好处
简单来说,lambda表达式通常是当你需要使用一个函数,但是又不想费脑命名一个函数的时候使用,也就是通常所说的匿名函数
-
python中怎么拷贝一个对象
python中对象之间的赋值是按照引用传递的,如果要拷贝对象需要使用标准模板中的copy
copy.copy 浅拷贝,只拷贝父对象,不拷贝父对象的子对象
copy.deepcopy 深拷贝,拷贝父对象和子对象
-
__new__和__init__的区别
__init__为初始化方法,__new__方法是真正的构造函数
__new__是实例创建时被调用的,它的任务是创建并返回这个实例,是静态方法
—init__是实例创建之后被调用的,然后设置对象属性的一些初始值
-
python中单下划线和双下划线分别是什么?
__name__:一种约定,python内部的名字,是用来与用户自动以的名字区分开,防止冲突
_name: 一种约定,用来指定变量私有
__name: 解释器用_classname_name来代替这个名字用来区别和其他类相同的命名
-
说一下python自省
python中自省指的是在代码运行过程中自动获取对象的类型
-
不可变变量
不可变对象是指不可以被引用改变的对象,如字符串
-
海量数据处理问题
1.海量日志数据,提取出某日访问百度次数最多的那个IP
2.寻找热门查询,300万个查询字符串中统计最热门的10个查询
3. 有一个1G大小的文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,返回频数最高的100个词
均可以采用:
利用hash映射,将数据映射到小文件中,取1000为例,然后在各个小文件中进行hashmap统计各个串的出现频数,对应进行快排序或者堆排序,找出每个文件中最大频数的,最后将每个文件中最多的取出再进行快排,得到总的出现最多的字符
4. 海量数据分布在100台电脑中,想个办法高效统计出这批数据的top10
这种就分为两种情况:
情况1:
若没有重复的数据分布在不同的100台电脑中,则对每一台电脑中的数据,进行堆排序,找到top10的结果,再将100台的top10的数据进行建堆再进行堆排
情况2:
若有重复的数据分布在不同电脑中,那么对所有的数据进行映射到不同文件中,确保相同数据在同一个文件中,然后进行hashmap,堆排序再堆排序
5. 有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复,要求按照query的频度排序
做法相同
6. 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,找出a,b文件中相同的url
这种找相同数据的步骤:
由于单文件总量为5G*64=320G,无法一次读入内存,同样将a文件hash函数读入1000个文件中,每个大小为300M左右,同样将b文件也是以相同的hash函数读入另外的1000个文件,这样就就形成了1000对文件,每一对文件才有可能存在相同的url,将a的映射文件hashmap,然后遍历对应的本对中b的映射文件,若在a的hashmap中存在,则为相同url,这样统计下来
7. 怎么在海量数据中国找出重复次数最多的一个?
做法相同,先hash到小文件,然后hashmap计数比较
8.上千万或上亿的数据,统计其出现次数最多的前N个数据
相同
9 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析
同样的套路
多层划分(按照bitmap划分)
1. 2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数
整数个数一共有2^32个,可以将划分为2^8个区域,比如用一个文件代表一个区域,然后将数据分离到不同的区域,再在不同的区域利用bitmap就可以找个各自区域内不重复的数据了
2. 5亿个int找到它们的中位数
将2^32个数表示划分为2^16个区域,然后读取数据统计落在各个区域里的数的个数,之后就可以根据统计结果判断中位数落在哪个区域,同时知道这个区域中的第几大数刚好是中位数,然后第二次扫描只用统计这个区域中的那些数就可以
公司算法工程师面试经验:
目前面了有拼多多两面、今日头条三面,期望offer。。。
拼多多:
1. 使用tensorflow,常见调哪些参数列举一下
2. 调参调优化器时为什么选择adam,比较下adam与sgb
3. 推导 gbdt
4. 强化学习列举有哪些算法
5. 强化学习哪些是on-policy 哪些是off-policy ,介绍一下Q-learning与Sarrsa, 比较他们的区别
6. 介绍一下Markov
头条:
1. 介绍一下xgboost,有看过xgboost源码吗
2. 其他专心撕代码
3. 了解C++多线程么(不了解),那说下python的多线程
总结:多看面筋,另外xgboost写个demo过一遍,调参方法等,yolo、ssd目标检测再过一遍
- BN的作用
介绍BN,首先介绍深度学习过程实际上是学习数据的分布,而通过每一层卷积后,由于前一层的参数是每步迭代都会发生更新,因此后面层的数据的分布都会发生变化,那么网络又要花费精力去学习新的数据分布,从而使得学习速度很慢,因此就想将每一层的数据都通过归一化到同一分布上来加快学习,但是如果每一层改变其分布,那么就破坏了学习到的特征的分布,因此就引入了变换重构
于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数γ、β,这就是算法关键之处:
![]()
每一个神经元xk都会有一对这样的参数γ、β。这样其实当:
![]() 、
、![]()
是可以恢复出原始的某一层所学到的特征的。因此我们引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。
可以解决梯度消失和梯度爆炸
- 介绍auc
介绍auc,那么就介绍ROC,auc反映的是从样本集中抽出样本,预测这个样本是正例的概率比预测这个样本是反例的概率大的概率,做法是由于每种样本出现的概率已知,将其由小到大进行排序,依次作为截断概率,小于该概率预测为负例,大于该概率预测为正例,这样每个样本都有一个预测值,可以计算出样本中的真阳率和假阳率,在坐标系上描点,然后依次改变截断概率,计算不同组的真假阳率,绘制出的曲线与横轴所夹的面积就是AUC
-
决策树处理缺失值
缺失值问题可以从三个方面来考虑
1. 在选择分裂属性的时候,训练样本存在缺失值,如何处理?(计算分裂损失减少值时,忽略特征缺失的样本,最终计算的值乘以比例(实际参与计算的样本数除以总的样本数))
假如你使用ID3算法,那么选择分类属性时,就要计算所有属性的熵增(信息增益,Gain)。假设10个样本,属性是a,b,c。在计算a属性熵时发现,第10个样本的a属性缺失,那么就把第10个样本去掉,前9个样本组成新的样本集,在新样本集上按正常方法计算a属性的熵增。然后结果乘0.9(新样本占raw样本的比例),就是a属性最终的熵。
2. 分类属性选择完成,对训练样本分类,发现样本属性缺失怎么办?(将该样本分配到所有子节点中,权重由1变为具有属性a的样本被划分成的子集样本个数的相对比率,计算错误率的时候,需要考虑到样本权重)
比如该节点是根据a属性划分,但是待分类样本a属性缺失,怎么办呢?假设a属性离散,有1,2两种取值,那么就把该样本分配到两个子节点中去,但是权重由1变为相应离散值个数占样本的比例。然后计算错误率的时候,注意,不是每个样本都是权重为1,存在分数。
3. 训练完成,给测试集样本分类,有缺失值怎么办?(分类时,如果待分类样本有缺失变量,而决策树决策过程中没有用到这些变量,则决策过程和没有缺失的数据一样;否则,如果决策要用到缺失变量,决策树也可以在当前节点做多数投票来决定(选择样本数最多的特征值方向)。)
(U)如果有单独的缺失分支,使用此分支。(c)把待分类的样本的属性a值分配一个最常出现的a的属性值,然后进行分支预测。(S)根据其他属性为该待分类样本填充一个属性a值,然后进行分支处理。(F)在决策树中属性a节点的分支上,遍历属性a节点的所有分支,探索可能所有的分类结果,然后把这些分类结果结合起来一起考虑,按照概率决定一个分类。(H)待分类样本在到达属性a节点时就终止分类,然后根据此时a节点所覆盖的叶子节点类别状况为其分配一个发生概率最高的类。
-
为什么LR用极大似然估计参数
如果用平方差损失函数时,损失函数对于参数是一个非凸优化的问题,可能会收敛到局部最优解,而且对数似然的概念是使得样本出现的概率最大,采用对数似然梯度更新速度也比较快
-
极大似然估计和最小二乘估计的关系
极大似然的估计的概念是最大化样本出现概率,即目标函数为似然函数,而最小二乘估计是为了最小化样本预测值与真实值之间的距离,即最小化估计值和预测值差的平方和,当似然函数为高斯函数时两者相同
-
CNN中卷积和池化的作用
卷积有一个重要概念是卷积核,用法是对上一层feature map进行逐块扫描进行卷积计算得到新的feature map,用于获得新的feature map,每个卷积核代表了一种特征,即从前一层提取新的特征,并且减少了参数
池化是为了防止图像特征提取中像素偏移对结果造成影响,因此做法是对扫描的每一块取最大值或平均值,
-
解释一下核函数
-
相似度的计算方法了解哪些,各自的优缺点是什么
1.皮尔逊相关系数
反映的是两个变量之间的线性相关性,它的一个缺点是针对用户之间只有一个共同的评分项不能进行比较,另外没有考虑重叠的评分项数量对相似度的影响
2.欧几里得距离
描述两个变量之间的直线距离,当两个变量至少有一个相同评分项时可以计算
3.余弦相似度
余弦值代表的是空间向量上的夹角余弦值,更体现的是空间上的差异性,与欧几里得距离相比,欧更注重的是绝对数值之间的差异,而余弦更注重的趋势上的不同,
4. 曼哈顿距离
表示绝对轴距总和,只有上下和左右的方向
-
聚类算法有哪些,优缺点是什么
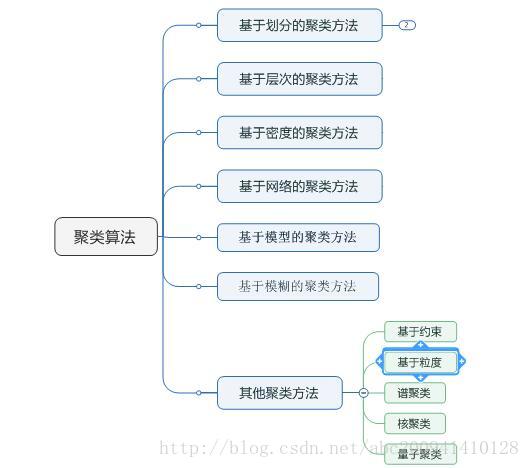
1. 基于层次的聚类
做法是将每个对象都看做一个类,计算两两之间距离最小的对象归为一类,然后重复这样的操作直至成为一个类,这种方式是采用贪心的方法,一步错步步错,时间复杂度过高,可解释性比较好
2. 基于划分的聚类(k-Means)
原则是保证簇内的数据距离尽可能小,簇间的距离尽可能大,做法是确定需要划分的k的类别数,然后选择初始点,计算所有点到这些点的距离,将距离最近的点划为一簇,然后计算每一簇的平均值当做新的中心点,重复这样的过程直至最后收敛,优点在于时间空间复杂度都不高,但是对于k比较敏感,容易陷入局部最优解
3. 基于密度的聚类(DBSCAN)
k-means聚类解决不了不规则形状的聚类,而基于密度的聚类可以解决,并对于噪声点比较有效,能发现任意形状的聚类,但是聚类的结果和参数关系很大
4. 基于网络的聚类
原理是将数据空间划分成网格,计算每个网格中的数据密度,将相邻的高密度网格划为一簇,优点就是划分速度很快,因为是按照网格划分的,和数据点个数没有关系,所以对数据个数不敏感,但是却是以牺牲精度作为代价来实现的
5. 基于模型的聚类 (SOM)
原理是为每一簇拟定一个概率模型,主要是基于概率模型和神经网络模型的方法,假定随机选择的数据服从某种分布,找到获胜单元,然后调整获胜单元周围的向量向其靠拢,最后形成簇,优点是分成簇没有那么硬,分类比较柔和,是以概率的形式表示的,缺点是执行效率不高,当数据较多较复杂时很慢
6. 基于模糊的聚类(FCM)
原理来自于模糊集合论,使用隶属度来确定每个数据属于哪一类的,不断迭代隶属矩阵直至收敛来确定类别,算法对满足正态分布的数据具有很好的效果,缺点是算法的性能依赖于初始簇心,不能保证收敛于一个最优解
-
k-means除了随机选择初始质心,还有什么方法
1. 多次运行,每次使用一组不同的初始质心,计算平方误差,选择最小的作为初始质心
2. 使用层次聚类,找到k个簇的质心,以这个质心作为初始质心
3. 先随机选择一个初始质心,然后找到后继质心,即找到距离这个质心最远的点作为新的质心,这样就保证了选择初始点的随机性以及是散开的
-
k-means算法的时间空间复杂度
时间复杂度为O(tmnK) t表示迭代次数,m表示数据个数,表示数据特征维度,K表示类簇数
空间复杂度为O((m+K)*n) m表示数据个数,K表示类簇个数,n表示维度,理解就是需要存储数据点和类中心点
-
SVM实现多分类做法
有三种方式, 1-1 1-多 多-多
1-1:每次取出两种类进行训练,结果训练出n*(n-1)/2个分类器,然后对预测结果进行投票
1-多 :一类为正类,其余全部为负类,但是当出现数据不平衡时会出现问题
多-多:采用的是层次支持向量机,先将数据分为两个子类,然后将子类再划分为次子类,这样逐步划分下去最终不再出现子类为止
-
Sigmoid 与tanh的区别优劣
sigmoid对于前向传播比较友好,将值映射到0,1之间,但是反向传播容易出现梯度消失的情况,并且进行幂计算比较耗时,产生的信号为非0均值信号,会对反向传播造成影响,而tanh将其映射到-1,1之间,数据分布均值为0
-
梯度消失问题和损失函数有关吗?
没有必然联系,不过不同的损失函数可能产生不同程度地梯度消失问题
-
dropout原理
以在前向传播的过程中,以一定概率地让一些神经元停止工作,来降低模型的复杂度,类似于模型平均
-
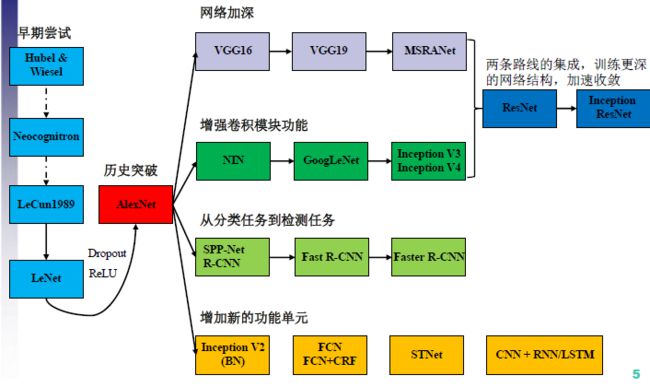
说一下卷积神经网络
首先是LeNet,七层结构,也就是早期的神经网络,但是中途一直没有得到发展,直到2012年出现了AlexNet,采用了(数据增强,大数据集(imagenet),dropout,relu激活函数,同时使用了GPU)这些技巧,使得准确率得到显著提升;VGG提出了一个新的概念,用小的卷积核的堆叠来替代大的卷积核,更加精确,也更深,使用了3*3的卷积来代替原先的11*11和5*5的卷积核;ResNet网络深到极致,采用了一种将之前的网络层输出也作为当前层的输入来防止网络过深造成的梯度消失现象;
既然深到了极致,又开始考虑能不能把网络拓宽,提出了inception v1的网络结构,使用了不同尺寸的卷积核,增加了网络的宽度,同时增加了网络对尺度的适应性,后来由于直接用不同尺寸进行卷积参数量巨大,采用了一个trick,在之前加入了一个1*1的卷积核进行运算,有效减小了参数;inception v2就仿照了VGG的特点,用2个3*3的卷积核来代替5*5的卷积核进一步减小参数;既然如此,做到极致那么n*n的卷积核可以用n*1和1*n的卷积核来代替,参数减少,同时网络更深,输入的尺寸由299*299变为了224*224,;Xception的提出基于一个假设,也就是空间相关性和通道相关性是可分离的,因此是采用了先进行一个整体的1*1的卷积操作,但每个通道形成的featuremap不进行叠加,而是对这些通道上所有的featuremap进行正常的多个3*3卷积,得到结果,模型变得很宽,参数没发生大变化,但是在性能上得到了提升。
-
全连接层和卷积层的作用?
全连接层是起到一个分类器的作用,卷积层是用来提取某些特征的层,参数量相对小很多,起到特征工程的作用,感受视野,将欲提取之外的数据的影响减弱,增强需要提取特征的那部分数据的影响
-
inception模块的作用?
通过堆叠多种不同尺度的卷积核,加宽网络宽度,在保证参数量的前提下提升了性能,使得网络能够适应多尺度的特征
-
Resnet之后还有什么网络?
出现了新的网络结构DenseNet, SENet,先简单介绍一下densenet,任意两层之间都有连接,将每一层学到的特征传送给之后的所有层,除去深度和宽度,在feature上做到极致化,实现特征的重复利用,并且将每一层设计的很窄,每层只学习很少的特征图,在保证精度的情况下减少了计算量
https://blog.csdn.net/u014380165/article/details/78006626 SENet
-
tensorflow中graph和session
如果在一个进程中创建了多个Graph,则需要创建不同的Session来加载每个Graph,而每个Graph则可以加载在多个Session中进行计算。
-
LR的输入,离散值还是连续值?
在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
-
gbdt的损失函数
gbdt可以用多种损失函数来进行拟合回归树
-
softmax原理分类
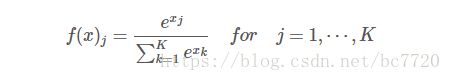
- Softmax 函数可以导,这点很关键,当损失函数是交叉熵时,计算很方便。
- Softmax 函数能够指数级扩大最后一层的输出,每个值都会增大,然而最大的那个值相比其他值扩大的更多,最终归一化。
-
LSTM和GRU
lstm如何来防止梯度爆炸和梯度消失的?
针对RNN, 要解决梯度爆炸可以使用梯度裁剪的方式来进行,而对于梯度消失,由于
传统的RNN是用覆盖的的方式计算状态:,也就是说,这有点类似于复合函数,那么根据链式求导的法则,复合函数求导:设和为的可导函数,则,他们是一种乘积的方式,那么如果导数都是小数或者都是大于1的数的话,就会使得总的梯度发生vanishing或explosion的情况,当然梯度爆炸(gradient explosion)不是个严重的问题,一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩),但是梯度消失做不到,这个时候就要用lstm了。
在lstm中,我们发现,状态S是通过累加的方式来计算的,。那这样的话,就不是一直复合函数的形式了,它的的导数也不是乘积的形式,这样就不会发生梯度消失的情况了。
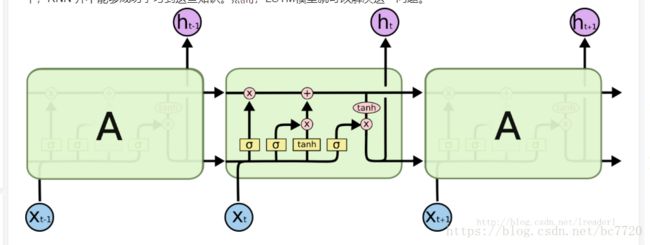
如果只是对gru和lstm来说的话,一方面GRU的参数更少,因而训练稍快或需要更少的数据来泛化。另一方面,如果你有足够的数据,LSTM的强大表达能力可能会产生更好的结果。GRU作为LSTM的一种变体,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
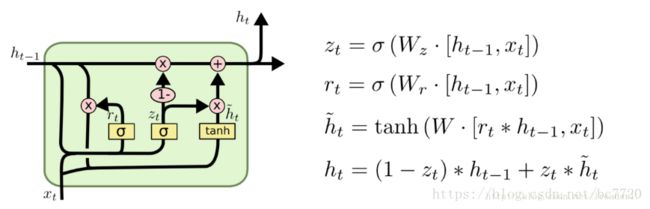
-
BN的参数

-
SVM相关
- 简单介绍SVM:从分类平面,到求两类之间的最大间隔,到转化为max 1/w^2 即min w^2,带限制条件的优化问题,然后就是找到优化问题的解决办法,首先是用拉格朗日乘子把约束优化转化为无约束优化,对各个变量求导令其为0,并且增加KKT条件,对α(y(wx+b))=0 以及α>=0,将得到的式子带入拉格朗日式子中转化为对偶问题,最后利用SMO来解决这个对偶问题
- SVM推导:解释原问题和对偶问题,一般一个最优化问题对偶问题给出的是主问题的最优解的下界,当强对偶条件成立时,两者相等
- SVM和LR最大区别:损失函数不同。LR损失函数是对数损失,SVM损失是hinge损失,SVM只考虑分类面上的点,而LR考虑所有点,在SVM中,在支持向量之外添加减少任何点都对结果没有影响,而LR则是会对每一个点都会影响决策;SVM不能产生概率,LR可以产生概率,SVM不是改了模型,基于的假设不是关于概率的