互联网公司校招Java面试题总结及答案——阿里、腾讯
部分重复的我已经去掉了,所以显得比较少,其他请参看我的系列文章:
互联网公司校招Java面试题总结及答案——京东
( 百度Java面经)互联网公司校招Java面试题总结及答案——百度(目前只是部分总结)
互联网公司校招Java面试题总结及答案——美团
互联网公司校招Java面试题总结及答案——CVTE
互联网公司校招Java面试题总结及答案——乐视、滴滴、华为
互联网公司校招Java面试题总结及答案——招银科技
互联网公司校招Java面试题总结及答案——微店、去哪儿、蘑菇街
---------------------------------------阿里---------------------------------------------------
1.HashMap和HashTable的区别,及其实现原理。
HashTable底层是用HashMap实现的,与HashMap的区别是,HashTable是按存入顺序排序的,而HashMap不是。HashMap的原理是有一个大的table数组组成,每个数组元素是一个Entry。为了处理冲突,通常会将Entry用链表实现。
ArrayList,LinkedList 和Vector的区别和实现原理。
ArrayList是基于数组的可变长数组,因为这个特性,所以它更适合实现get和set;LinkedList是基于双向链表的,所以比较适合实现插入和删除等操作;但以上两个都是非线程安全的,Vector的实现和ArrayList差不多,改进的地方是使用synchronized实现了线程安全。
TreeMap和TreeSet区别和实现原理。
其中 TreeMap 是 Map 接口的常用实现类,而 TreeSet 是 Set 接口的常用实现类。
TreeSet 底层是通过 TreeMap 来实现的(如同HashSet底层是是通过HashMap来实现的一样),因此二者的实现方式完全一样。而 TreeMap 的实现就是红黑树算法。
相同点:
- TreeMap和TreeSet都是有序的集合,也就是说他们存储的值都是拍好序的。
- TreeMap和TreeSet都是非同步集合,因此他们不能在多线程之间共享,不过可以使用方法Collections.synchroinzedMap()来实现同步
- 运行速度都要比Hash集合慢,他们内部对元素的操作时间复杂度为O(logN),而HashMap/HashSet则为O(1)。
不同点:
- 最主要的区别就是TreeSet和TreeMap非别实现Set和Map接口
- TreeSet只存储一个对象,而TreeMap存储两个对象Key和Value(仅仅key对象有序)
- TreeSet中不能有重复对象,而TreeMap中可以存在
- TreeMap的底层采用红黑树的实现,完成数据有序的插入,排序。
ConcurrentHashMap实现原理(锁分离技术)。String和StringBuffer,StringBuilder区别和联系,String为啥不可变,
在内存中的具体形态。
String:字符串常量,字符串长度不可变。
StringBuffer:字符串变量(Synchronized,即线程安全)。如果要频繁对字符串内容进行修改,出于效率考虑最好使用StringBuffer,如果想转成String类型,可以调用StringBuffer的toString()方法。
StringBuilder:字符串变量(非线程安全)。在内部,StringBuilder对象被当作是一个包含字符序列的变长数组。
StringBuilder与StringBuffer有公共父类AbstractStringBuilder(
抽象类)。
2.java中多线程机制,实现多线程的两种方式(继承Thread类和实现Runnable接口)的区别和联系。
3.java线程阻塞调用wait函数和sleep区别和联系,还有函数yield,notify等的作用。
wait是Object的方法,sleep是Thread类的方法;
wait让出CPU资源的同时会放弃锁,sleep让出CPU资源的同时不会释放锁;
wait需要notify或者notifyall来唤醒,sleep在沉睡指定时间后,会自动进入就绪状态;
4.java中的同步机制,synchronized关键字,锁(重入锁)机制,其他解决同步的方volatile关键字ThreadLocal类的实现原理要懂。
5.java中异常机制
Throwable是Error和Exception的父类,Error一般是指JVM抛出的错误,不需要捕获,Exception是程序错误,需要捕获处理;
6.comparable接口和comparator接口实现比较的区别和用法,Arrays静态类如下实现排序的。
7.问快排的优化,怎么选基准,我就说随机化,防止退化。谈谈快排,于是3种快排4种优化方式,以及partition函数的应用。
http://blog.csdn.net/hacker00011000/article/details/52176100
3种快排,是指3中基数的选择方法:固定位置、随机、三数取中;
4种优化:(1)当待排序序列的长度分割到一定大小后,使用插入排序;
(2)在一次分割结束后,可以把与Key相等的元素聚在一起,继续下次分割时,不用再对与key相等元素分割;
(3)优化递归操作;
(4)使用并行或多线程处理子序列;
随机化可以解决当数组有序或者部分有序时的退化,但是当数组元素全部重复的时候,时间复杂度依然很高;
三数取中:对待排序序列中low、mid、high三个位置上数据进行排序,取他们中间的那个数据作为枢轴,并用0下标元素存储枢轴。这个方法还是无法解决重复数组的问题。
在一次分割结束后,可以把与Key相等的元素聚在一起,继续下次分割时,不用再对与key相等元素分割,可以明显提高重复数组的效率。
STL中的Sort函数:当数据量较大时采用快速排序,分段递归。一旦分段后的数据量小于某个阀值,为避免递归调用带来过大的额外负荷,便会改用插入排序。而如果递归层次过深,有出现最坏情况的倾向,还会改用堆排序。
STL采用的做法称为
median-of-three,即取整个序列的首、尾、中央三个地方的元素,以其中值作为枢轴。
8.在栈上为什么不能用变量做数组的长度,堆上可以吗?
9.问了我的项目,QQ聊天系统,怎么实现的,客户端为什么要用TCP和UDP结合,用UDP协议有什么好处,消息是怎样定义的,怎样区分不同的 消息,怎么知道使用锁的。我给他说了epoll、线程池,Reactor模式,以及自己实现的哈希表,线程之间怎样同步等
---------------------------------------------腾讯-----------------------------------------------------
1.TCP/UDP区别,TCP三次握手,SYN攻击
TCP是面向连接的可靠传输,需要三次握手,保证可靠通信;有重传机制;
UDP是无连接的不可靠传输,但是速度快,适用于视频和电话会议等实时应用场景;
TCP三次握手是:SYN=x(SYN_SEND)、ACK=x+1,SYN=y(SYN_RECV)、ACK=y+1(ESTABLISHED);
SYN攻击是:SYN攻击属于DOS攻击的一种,它利用TCP协议缺陷,通过发送大量的半连接请求,耗费CPU和内存资源。
检测SYN攻击非常的方便,当你在服务器上看到大量的半连接状态时,特别是源IP地址是随机的,基本上可以断定这是一次SYN攻击。
一类是通过防火墙、路由器等过滤网关防护,另一类是通过加固TCP/IP协议栈防范。过滤网关防护主要包括超时设置,SYN网关和SYN代理三种。调整tcp/ip协议栈,修改tcp协议实现。主要方法有SynAttackProtect保护机制、SYN cookies技术、增加最大半连接和缩短超时时间等。
但一般服务器所能承受的连接数量比半连接数量大得多
2.SHA,MD5
SHA(安全哈希算法):该算法的思想是接收一段明文,然后以一种
不可逆的方式将它转换成一段(通常更小)密文,也可以简单的理解为取一串输入码(称为预映射或信息),并把它们转化为长度较短、位数固定的输出序列即散列值(也称为信息摘要或信息认证代码)的过程。可以对任意长度的数据运算生成一个
160位的数值。SHA将输入流按照每块512位(64个字节)进行分块,并产生20个字节的被称为信息认证代码或信息摘要的输出。SHA-1是不可逆的、防冲突,并具有良好的雪崩效应。
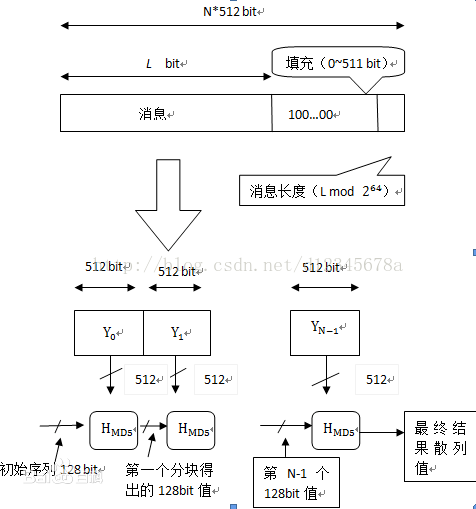
MD5(信息-摘要算法5):MD5将任意长度的“字节串”映射为一个128bit的大整数。MD5以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
原理参见:
http://baike.baidu.com/link?url=ZAyVdzKs-4Oj7e6VQFY4zbzSw-OhOfCyRGlneCm4f4J8fUuTCPomQyIX7kZwfbFA3Dwmry70s2RsSBiVvU_m9_
两者比较:
(1)对强行攻击的安全性:最显著和最重要的区别是SHA-1摘要比MD5摘要长32 位。使用强行技术,产生任何一个
报文使其摘要等于给定报摘要的难度对MD5是2^128数量级的操作,而对SHA-1则是2^160数量级的操作。这样,SHA-1对强行攻击有更大的强度。
(2)对密码分析的安全性:由于MD5的设计,易受密码分析的攻击,SHA-1显得不易受这样的攻击。
(3)速度:在相同的硬件上,SHA-1的运行速度比MD5慢。
3.了解的网络攻击手段,可以怎么预防
拒绝服务攻击:
(1)SYN拒绝服务攻击:目标计算机如果接收到大量的TCP SYN报文,而没有收到发起者的第三次ACK回应,会一直等待,处于这样尴尬状态的半连接如果很多,则会把目标计算机的资源(TCB控制结构,TCB,一般情况下是有限的)耗尽,而不能响应正常的TCP连接请求。
(2)ICMP洪水:。这样如果攻击者向目标计算机发送大量的ICMP ECHO报文(产生ICMP洪水),则目标计算机会忙于处理这些ECHO报文,而无法继续处理其它的网络数据报文,这也是一种拒绝服务攻击(DOS)。
(3)UDP洪水;
(4)死亡之PING:TCP/IP规范要求IP报文的长度在一定范围内(比如,0-64K),但有的攻击计算机可能向目标计算机发出大于64K长度的PING报文,导致目标计算机IP协议栈崩溃。
(5)IP地址欺骗:如果一个攻击者向一台目标计算机发出一个报文,而把报文的源地址填写为第三方的一个IP地址,这样这个报文在到达目标计算机后,目标计算机便可能向毫无知觉的第三方计算机回应。这便是所谓的IP地址欺骗攻击。
4.10亿条短信,找出前一万条重复率高的
(1)首先将文本导入数据库,再利用select语句某些方法得出前10条短信。(索引)但是这个时间效率很低;
(2)使用hash计算并存储次数,然后遍历一次找出top10;

5.对一万条数据排序,你认为最好的方式是什么
申请长度为一千万位的位向量bit[10000000],所有位设置为0,顺序读取待排序文件,每读入一个数i,便将bit[i]置为1。当所有数据读入完成,便对bit做从头到尾的遍历,如果bit[i]=1,则输出i到文件,当遍历完成,文件则已排好序。本机运行耗时9秒49毫秒。
(这种方法要求数组中的数据没有重复,且都不超过最大值)
1、10w行数据,每行一个单词,统计出现次数出现最多的前100个。
(1)可以使用小根堆;
(2)在linux中实现:
cat words.txt | sort | uniq -c | sort -k1,1nr | head -10
uniq -c:
显示唯一的行,并在每行行首加上本行在文件中出现的次数
sort -k1,1nr:
按照第一个字段,数值排序,且为逆序
2、一个文本文件,给你一个单词,判断单词是否出现。
grep -wq "fail" 123.txt && echo "no"||echo "yes"
新手推荐看
http://www.tldp.org/LDP/Bash-Beginners-Guide/Bash-Beginners-Guide.pdf
进阶推荐看
http://www.tldp.org/LDP/abs/abs-guide.pdf
3、两个线程如何同时监听一个端口。
多个线程可以监听同一个端口,但我们通常不这样做。
多个进程也可以同时监听一个端口,比如nginx。