【性能优化实战】4次版本迭代,我们将项目性能提升了360倍!
作者:闪客sun
https://www.cnblogs.com/flashsun
一直不知道性能优化都要做些什么,从哪方面思考,直到最近接手了一个公司的小项目,可谓麻雀虽小五脏俱全。让我这个编程小白学到了很多性能优化的知识,或者说一些思考方式。真的感受到任何一点效率的损失放大一定倍数时,将会是天文数字。
最初我的程序计算下来需要跑2个月才能跑完,经过2周不断地调整架构和细节,将性能提升到了4小时完成。整体性能提升了360倍
很多心得体会,希望和大家分享,也希望多多批评指正,共同进步。
一、项目描述
我将公司的项目内容抽象,大概是要做这样一件事情:
1、数据库A中有2000万条用户数据;
2、将数据库A中的用户读出,为每条用户生成guid,并保存到数据库B中;
3、同时在数据库A中生成关联表;

项目要求为:
1、将用户存入数据库B的过程需要调用sdk的注册接口,不允许直接操作jdbc进行插入;
2、数据要求可恢复:再次运行要跳过已成功的数据;出错的数据要进行持久化以便下次可以选择恢复该部分数据;
3、数据要保证一致性:在不出错的情况下,数据库B的用户必然一一对应数据库A的关联表。如果出错,那么正确的数据加上记录下来的出错数据后要保证一致性;
4、速度要尽可能块:共2000万条数据,在保证正确性的前提下,至多一天内完成;
二、第一版:面向过程——2个月
特征:面向过程、单一线程、不可拓展、极度耦合、逐条插入、数据不可恢复

最初的一版简直是汇聚了一个项目的所有缺点。整个流程就是从A库读出一条数据,立刻做处理,然后调用接口插入B库
然后在拼一个关联表的sql语句,插入A库。没有计数器,没有错误信息处理。
这样下来的代码最终预测2000万条数据要处理2个月。如果中间哪怕一条数据出错,又要重新再来2个月。简直可怕。
这个流程图就等同于废话,是完全基于面向过程的思想,整个代码就是在一个大main方法里写的,实际业务流程完全等同于代码的流程。
思考起来简单,但实现和维护起来极为困难,代码结构冗长混乱。而且几乎是不可扩展的。暂且不谈代码的设计美观,它的效率如此低下主要有一下几点:
1、每一条数据的速度受制于整个链条中最慢的一环。
试想假如有一条A库插入关联表的数据卡住了,等待将近1分钟(夸张了点),那这一分钟jvm完全就在傻等,它完全可以继续进行之前的两步。
正如你等待鸡蛋煮熟的过程中可以同时去做其他的事一样。
2、向B库插入用户需要调用sdk(HTTP请求)接口
那每一次调用都需要建立连接,等待响应,再释放链接。正如你要给朋友送一箱苹果,你分成100次每次只送一个,时间全搭载路上了。
三、第二版:面向对象——21天
特征:面向对象、单一线程、可拓展、略微耦合、批量插入、数据可恢复
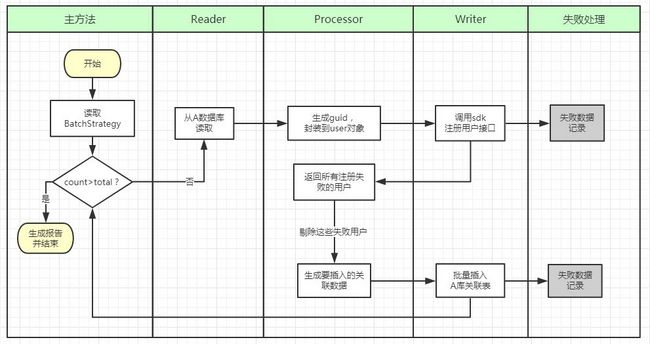
3.1、架构设计
根据第一版设计的问题,第二版有了一些改进。当然最明显的就是从面向过程的思想转变为面向对象。
我将整个过程抽离出来,分配给不同的对象去处理。这样,我所分配的对象时这样的:
1、一个配置对象:BatchStrategy。
负责从配置文件中读取本次任务的策略并传递给执行者,配置包括基础配置如总条数,每次批量查询的数量,每次批量插入的数量。
还有一些数据源方面的,如来源表的表名、列名、等,这样如果换成其他数据库的类似导入,就能供通过配置进行拓展了。
2、三个执行者:
整个执行过程可以分成三个部分:读数据--处理数据--写数据,可以分别交给三个对象Reader,Processor,Writer进行。
这样如果某一处逻辑变了,可以单独进行改变而不影响其他环节。
3、一个失败数据处理类:ErrorHandler。
这样每当有数据出现异常时,便把改数据扔给这个类,在这给类中进行写入日志,或者其他的处理办法。在一定程度上将失败数据的处理解耦。
这种设计很大程度上解除了耦合,尤其是失败数据的处理基本上完全解耦。
但由于整个执行过程仍然是需要有一个main来分别调用三个对象处理任务,因此三者之间还是没有完全解耦
main部分的逻辑依然是面向过程的思想,比较复杂。即使把main中执行的逻辑抽出一个service,这个问题依然没有解决。
3.2、效率问题
由于将第一版的逐条插入改为批量插入。其中sdk接口部分是批量传入一组数据,减少了http请求的次数。生成关联表的部分是用了jdbc batch操作,将之前逐条插入的excute改为excuteBatch,效率提升很明显。
这两部分批量带来的效率提升,将原本需要两个月时间的代码,提升到了21天,但依然是天文数字。
可以看出,本次效率提升仅仅是在减少http请求次数,优化sql的插入逻辑方面做出来努力,但依然没有解决第一版的一个致命问题
即一次循环的速度依然受制于整个链条中最慢的一环,三者没有解耦也可以从这一点看出,在其他两者没有将工作做完时,就只能傻等,这是效率损失最严重的地方了。
四、第三版:完全解耦(队列+多线程)——3天
特征:面向对象、多线程、可拓展、完全解耦、批量插入、数据可恢复。
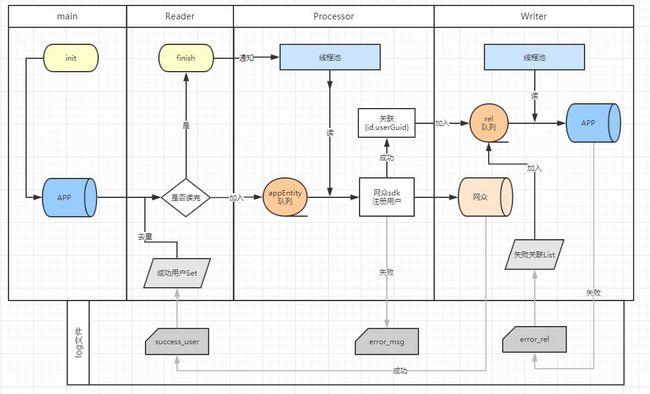
4.1、架构设计
该版并没有代码实现,但确是过度到下一版的重要思考过程,故记录在次。这一版本较上一版的重大改进之处有两点:队列和多线程。
队列:其中队列的使用使上一版未完全解耦的执行类之间,实现了完全解耦,将同步过程变为异步,同时也是多线程能够使用的前提。
Reader做的事就是读取数据,并放入队列,至于它的下一个环节Processor如何处理队列的数据,它完全不用理会,
这时便可以继续读取数据。这便做到了完全解耦,处理队列的数据也能够使用多线程了。
多线程:Processor和Writer所做的事情,就是读取自身队列中的数据,然后处理。只不过Processor比Writer还承担了一个往下一环队列里放数据的过程。
此处的队列用的是多线程安全队列ConcurrentLinkedQueue。因此可以肆无忌惮地使用多线程来执行这两者的任务。
由于各个环节之间的完全解耦,某一环上的偶尔卡主并不再影响整个过程的进度,所以效率提升不知一两点。
还有一点就是数据的可恢复性在这个设计中有了保障,成功过的用户被保存起来以便再次运行不会冲突,失败的关联表数据也被记录下来
在下次运行时Writer会先将这一部分加入到自己的队列里,整个数据的正确性就有了一个不是特别完善的方案,效率也有了可观的提升。
4.2、效率问题
虽然效率从21天提升到了3天,但我们还要思考一些问题。实际在执行的过程中发现,Writer所完成的数据总是紧跟在Processor之后。
这就说明Processor的处理速度要慢于Writer,因为Processor插入数据库之前还要走一段注册用户的业务逻辑。
这就有个问题,当上一环的速度慢过下一环时,还有必要进行批量的操作么?
答案是不需要的。
试想一下,如果你在生产线上,你的上一环2秒钟处理一个零件,而你的速度是1秒钟一个。这时即使你的批量处理速度更快,从系统最优的角度考虑,你也应该来一个零件就马上处理,而不是等积攒到100个再批量处理。
还有一个问题是,我们从未考虑过Reader的性能。实际上我用的是limit操作来批量读取数据库
而mysql的limit是先全表查再截取,当起始位置很大时,就会越来越慢。0-1000万还算轻松,但1000万到2000万简直是“寸步难行”。所以最终效率的瓶颈反而落到了读库操作上。
五、第四版:高度抽象(一键启动)——4小时
特征:面向接口、多线程、可拓展、完全解耦、批量或逐条插入、数据可恢复、优化查询的limit操作
5.1、架构的思考
优雅的代码应该是整洁而美妙,不应是冗长而复杂的。这一版将会设计出简洁度如第一版,而性能和拓展性超越所有版本的架构。
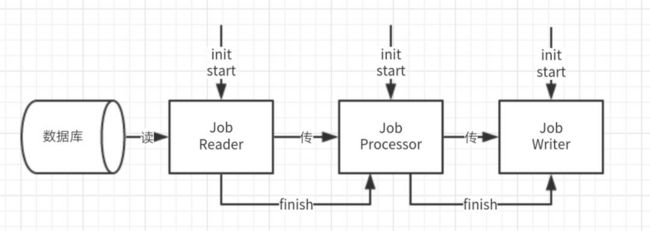
通过总结前三版特征,我发现不论是Reader,Processor,Writer,都有共同的特征:启动任务、处理任务、结束任务。
而Reader和Processor又有一个共同的可以向下一道工序传递数据,通知下一道工序数据传递结束的功能。
他们就像生产线上的一个个工序,相互关联而又各自独立地运行着。每一道工序都可以启动,疯狂地处理任务,直到上一道工序通知结束为止。
而第一个发起通知结束的便是Reader,之后便一个通知下一个,直到整个工序停止,这个过程就是美妙的。

因此我们可以将这三者都看做是Job,除了Reader外又都有与上一道工序交互的能力(其实Reader的上一道工序就是数据库),因此便有了如下的接口设计。


有了这样的接口设计,不论实现类具体怎么写,主方法已经可以写出了,变得异常整洁有序。
只提炼主干部分,去掉了一些细枝末节,如日志输出、时间记录等。
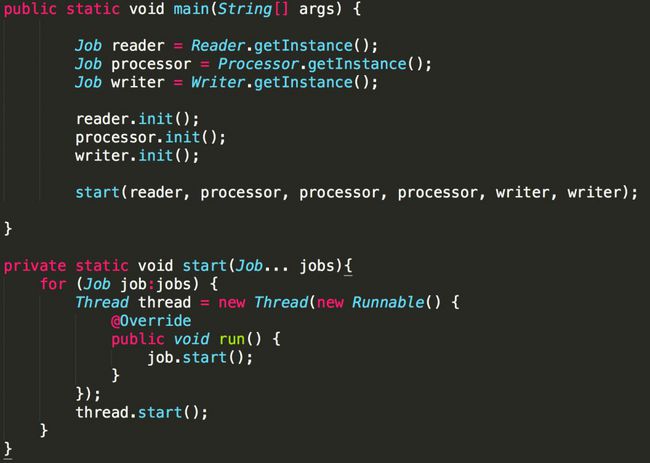
接下来就是具体实现类的问题了,这里实现类主要实现的是三个功能:
1、接收上一环的数据:
属于Interactive接口的receive方法的实现,基于之前的设计,即是对象中有一个ConcurrentLinkedQueue类型的属性,用来接收上一环传来的数据。
2、处理数据并传递给下一环:
在每一个(有下一环的)对象属性中,放入下一环的对象。如Reader中要有Processor对象,Processor要有Writer,一旦有数据需要加入下一环的队列,调用其receiive方法即可。
3、告诉下一环我结束了:
本任务结束时,调用下一环对象的closeInteractive方法。而每个对象判断自身结束的方法视情况而定
比如Reader结束的条件是批量读取的数据超过了一开始设置的total,说明数据读取完毕,可以结束。
而Processor结束的条件是,它被上一环通知了结束,并且从自己的队列中poll不出东西了,证明应该结束,结束后再通知下一环节。
这样整个工序就安全有序地退出了。不过由于是多线程,所以Processor不能贸然通知Writer结束信号,需要在Processor内部弄一个计数器,只有计数器达到预期的数量的那个线程的Processor,才能发起结束通知。
5.2、效率问题:
正如上一版提出的,Processor的处理速度要慢于Writer,所以Writer并不需要用batch去处理数据的插入,该成逐条插入反而是提高性能的一种方式。
大数据量limit操作十分耗时,由于测试部分只是在前几百万条测试,所以还是大大低估了效率的损失。在后几百万条可以说每一次limit的读取都寸步难行。
考虑到这个问题,我选去了唯一一个有索引并且稍稍易于排序的字段“用户的手机号”,(不想吐槽它们设计表的时候居然没有自增id。。。)
每次全表将手机号排序,再limit查询。查询之后将最后一条的手机号保存起来,成为当前读取的最后一条数据的一个标识。下次再limit操作就可以从这个手机号之后开始查询了。
这样每次查询不论从哪里开始,速度都是一样的。虽然前面部分的数据速度与之前的方案相比慢了不少,但却完美解决了大数据量limit操作的超长等待时间,预防了危险的发生。
至此,项目架构再次简洁起来,但同第一版相比,已经不是同一级别的简洁了。
六、关于继续优化的思考
1、Reader部分是单线程在处理,由于读取是从数据库中,并不是队列中,因此设计成多线程有些麻烦,但并不是不可,这里是优化点
2、日志部分占有很大一部分比例,2000万条读、处理、写就要有至少6000万次日志输出。如果设计成异步处理,效率会提升不少。
正文结束
推荐阅读 ↓↓↓
1.不认命,从10年流水线工人,到谷歌上班的程序媛,一位湖南妹子的励志故事
2.如何才能成为优秀的架构师?
3.从零开始搭建创业公司后台技术栈
4.写代码千万别用User这个单词!
5.37岁程序员被裁,120天没找到工作,无奈去小公司,结果懵了...
6.BAT都不让多表 join?这是为什么?
7.日均5亿查询量的京东订单中心,为什么舍MySQL用ElasticSearch?
8.15张图看懂瞎忙和高效的区别!
一个人学习、工作很迷茫?
点击「阅读原文」加入我们的小圈子!
