Spring Boot整合Flink
使用spring boot整合flink可以快速的构建起整个应用,将关注点重点放在业务逻辑的实现上。在整合的过程中遇到许多问题,最大的问题是flink流无法访问spring容器中的类,从而导致空指针异常,解决思路是在流中进行spring bean的初始化以获得ApplicationContext,进而使用其getBean方法获取类实例。
软件版本:Spring Boot 2.1.6+Flink1.6.1+JDK1.8
程序主体:
@SpringBootApplication
public class HadesTmsApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication application = new SpringApplication(HadesTmsApplication.class);
application.setBannerMode(Banner.Mode.OFF);
application.run(args);
}
@Override
public void run(String... args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer010 kafkaConsumer = new FlinkKafkaConsumer010<>("topic-name"), new SimpleStringSchema(), getProperties());
DataStream dataStream = env.addSource(kafkaConsumer);
// 此处省略处理逻辑
dataStream.addSink(new MySink());
}
private Properties getProperties() {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", bootstrap_servers);
properties.setProperty("zookeeper.connect", zookeeper_connect);
properties.setProperty("group.id", group_id);
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return properties;
}
}
说明一下:因为是非web项目,所以实现CommandLineRunner接口,重写run方法。在里面编写流处理逻辑。
如果在MySink中需要使用spring容器中的类,而MySink是一个普通的类,那么是无法访问到的。会引发空指针异常。可能有人想到了ApplicationContextAware这个接口,实现这个接口获取ApplicationContext,也即是:
@Component
public class ApplicationContextUtil implements ApplicationContextAware, Serializable {
private static final long serialVersionUID = -6454872090519042646L;
private static ApplicationContext applicationContext = null;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
if (ApplicationContextUtil.applicationContext == null) {
ApplicationContextUtil.applicationContext = applicationContext;
}
}
public static ApplicationContext getApplicationContext() {
return applicationContext;
}
//通过name获取 Bean.
public static Object getBean(String name) {
return getApplicationContext().getBean(name);
}
//通过class获取Bean.
public static T getBean(Class clazz) {
return getApplicationContext().getBean(clazz);
}
//通过name,以及Clazz返回指定的Bean
public static T getBean(String name, Class clazz) {
return getApplicationContext().getBean(name, clazz);
}
}
这种做法实际上在flink流处理中也是不可行的,在我之前的flink文章中 Flink读写系列之-读mysql并写入mysql 其中读和写阶段有一个open方法,这个方法专门用于进行初始化的,那么我们可以在这里进行spring bean的初始化。那么MySink改造后即为:
@EnableAutoConfiguration
@MapperScan(basePackages = {"com.xxx.bigdata.xxx.mapper"})
public class SimpleSink extends RichSinkFunction {
TeacherInfoMapper teacherInfoMapper;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
SpringApplication application = new SpringApplication(SimpleSink.class);
application.setBannerMode(Banner.Mode.OFF);
ApplicationContext context = application.run(new String[]{});
teacherInfoMapper = context.getBean(TeacherInfoMapper.class);
}
@Override
public void close() throws Exception {
super.close();
}
@Override
public void invoke(String value, Context context) throws Exception {
List teacherInfoList = teacherInfoMapper.selectByPage(0, 100);
teacherInfoList.stream().forEach(teacherInfo -> System.out.println("teacherinfo:" + teacherInfo.getTeacherId() + "," + teacherInfo.getTimeBit() + "," + teacherInfo.getWeek()));
}
}
在invoke中就可以访问spring容器中的Mapper方法了。
pom如下:
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.6.RELEASE
com.xxx.bigdata
flink-project
1.0.0
flink-project
jar
My project for Spring Boot
UTF-8
UTF-8
1.8
1.6.1
true
1.8
1.8
org.springframework.boot
spring-boot-starter
ch.qos.logback
logback-classic
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_2.11
${flink.version}
org.apache.flink
flink-connector-kafka-0.10_2.11
${flink.version}
com.cloudera
ImpalaJDBC41
2.6.4
com.zaxxer
HikariCP
3.2.0
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.1
com.alibaba
fastjson
1.2.47
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
src/main/java
src/main/resources
true
application.properties
application-${package.environment}.properties
org.springframework.boot
spring-boot-maven-plugin
true
com.xxx.bigdata.xxx.Application
repackage
org.mybatis.generator
mybatis-generator-maven-plugin
1.3.5
${basedir}/src/main/resources/generatorConfig.xml
true
true
com.cloudera
ImpalaJDBC41
2.6.4
dev
dev
true
pre
pre
pro
pro
项目打包使用了默认的spring boot插件,配置了skip为true,如果不配置此项,打包后会多一个BOOT-INF目录,运行时会引起ClassNotFoundException等各种异常,比如KafkaStreming问题,甚至需要反转flink的类加载机制,由child-first变为parent-first(修改flink配置文件)等等。
遇到的问题:
1. java.lang.NoSuchMethodError: com.google.gson.GsonBuilder.setLenient()Lcom/google/gson/GsonBuilder
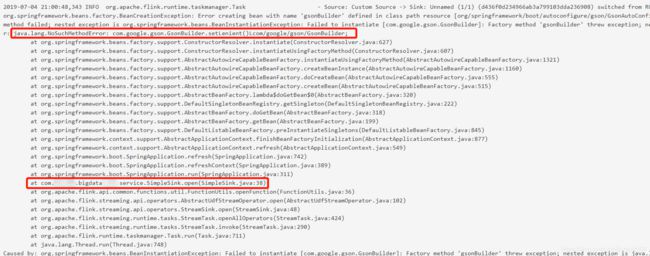 GsonBuilder类来自gson-xxx.jar包,而我在自己的项目中执行mvn dependency:tree并没有发现依赖这个包。莫非在flink运行时会使用自己lib库下的gson包,转而去flink的lib库下,发现flink-dist_2.11-1.6.1.jar里包含了gson-xxx包,但是打开这个包一看类中没有setLenient方法,于是在服务器上建立一个commlib,把gson-2.8.0.jar(包含setLenient方法)放进去,然后使用flink run提交时,指定classpath即可。
GsonBuilder类来自gson-xxx.jar包,而我在自己的项目中执行mvn dependency:tree并没有发现依赖这个包。莫非在flink运行时会使用自己lib库下的gson包,转而去flink的lib库下,发现flink-dist_2.11-1.6.1.jar里包含了gson-xxx包,但是打开这个包一看类中没有setLenient方法,于是在服务器上建立一个commlib,把gson-2.8.0.jar(包含setLenient方法)放进去,然后使用flink run提交时,指定classpath即可。
2.日志冲突
Caused by: java.lang.IllegalArgumentException: LoggerFactory is not a Logback LoggerContext but Logback is on the classpath. Either remove Logback or the competing implementation (class org.slf4j.impl.Log4jLoggerFactory loaded from file:/opt/flink-1.6.1/lib/slf4j-log4j12-1.7.7.jar). If you are using WebLogic you will need to add 'org.slf4j' to prefer-application-packages in WEB-INF/weblogic.xml: org.slf4j.impl.Log4jLoggerFactory
排除springboot中的日志即可:
org.springframework.boot
spring-boot-starter
ch.qos.logback
logback-classic
3.flink run提交作业到yarn上时,如果需要指定classpath,则需要指定到确定的jar包,指定目录不可行。那么假如所有依赖包已经放置在目录中,拼接的shell可以这么写:
lib_classpath="";
for jar in `ls /home/hadoop/lib`
do
jar_suffix=${jar##*.}
if [ "$jar_suffix" = "jar" ]
then
jar_path=" --classpath file:///home/hadoop/lib/$jar "
lib_classpath=${lib_classpath}${jar_path}
else
echo "the jar file $jar it not legal jar file,skip appendig"
fi
done
拼接后的lib_classpath值如下效果:
--classpath file:///home/hadoop/lib/accessors-smart-1.2.jar --classpath file:///home/hadoop/lib/akka-actor_2.11-2.4.20.jar
注意:如果jar包放本地文件系统,那么需要每台机器都放一份。