后BERT时代
目录
一、迁移学习与模型预训练:何去何从
迁移学习分类
何去何从
现状分析
未来可期
二、各类代表性工作
有监督模型预训练:CoVe
自监督学习同时训练:CVT
无监督模型预训练
ELMo
ULMFiT & SiATL
GPT/GPT-2
BERT
ERNIE: Enhanced Representation through Knowledge Integration(Baidu/2019)
ERNIE: Enhanced Language Representation with Informative Entities(THU/ACL2019)
Cross-lingual Language Model Pretraining(Facebook/2019)
MASS: Masked Sequence to Sequence Pre-training for Language Generation(Microsoft/2019)
Unified Language Model Pre-training for Natural Language Understanding and Generation(Microsoft/2019)
多任务学习:MT-DNN
XLNet
三、实践、观点、总结
实践与建议
观点
总结和一点感(敢)想
参考资料

2018年是NLP的收获大年,模型预训练技术终于被批量成功应用于多项NLP任务。之前搞NLP的人一直羡慕搞CV的人,在ImageNet上训练好的模型,居然拿到各种任务里用都非常有效。现在情形有点逆转了。搞CV的人开始羡慕搞NLP的人了。CV界用的还是在有监督数据上训练出来的模型,而NLP那帮家伙居然直接搞出了在无监督数据上的通用预训练模型!要知道NLP中最不缺的就是无监督的文本数据,几乎就是要多少有多少。还有个好消息是目前NLP中通用预训练模型的效果还远没达到极限。目前发现只要使用更多的无监督数据训练模型,模型效果就会更优。这种简单粗暴的优化方法对大公司来说实在再经济不过。而且,算法本身的效果也在快速迭代中。NLP的未来真是一片光明啊~
BERT发布之后,点燃了NLP各界的欢腾,各路神仙开始加班加点各显神通,很多相关工作被发表出来。本文会介绍其中的一些代表性工作,但更重要的是希望理清这些背后的逻辑,为它们归归类。通过这些思考,也对NLP以后的工作方向有些预测,供大家参考。
本文的内容主要包括以下几部分:
- 对迁移学习和模型预训练的一些思考,以及对未来工作方向的粗略预测
- 各类代表性工作的具体介绍(熟悉的同学可忽略),又细分为以下几大类:
- 有监督数据预训练
- 自监督训练
- 无监督数据预训练
- 多个有监督数据同时训练:多任务学习
3. 一些实践经验、别人和自己的观点、以及总结和感想
第一和第三部分内容相对少,原创密度大点,大家要是赶时间的话看这两部分就够了。第二部分的内容都是具体技术,有很多很好的文章都介绍过。放在本文当中一是为了文章的完备性,另一个是里面提到的一些知识点在其他地方没怎么提到。第三部分也会涉及到在一些任务上的调研实验工作,期望这些结果能坚定大家在自己的工作中把模型预训练技术用起来。
终于可以开始了。
一、迁移学习与模型预训练:何去何从
迁移学习分类
把当前要处理的NLP任务叫做T(T称为目标任务),迁移学习技术做的事是利用另一个任务S(S称为源任务)来提升任务T的效果,也即把S的信息迁移到T中。至于怎么迁移信息就有很多方法了,可以直接利用S的数据,也可以利用在S上训练好的模型,等等。
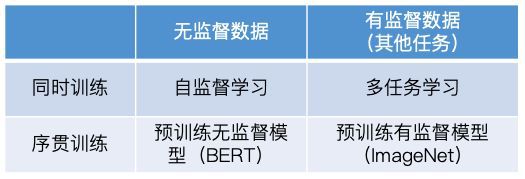
依据目标任务T是否有标注数据,可以把迁移学习技术分为两大类,每个大类里又可以分为多个小类。
第一大类是T没有任何标注数据,比如现在很火的无监督翻译技术。但这类技术目前主要还是偏学术研究,离工业应用还有挺长距离的。工业应用中的绝大部分任务,我们总是能想办法标注一些数据的。而且,目前有监督模型效果要显著优于无监督模型。所以,面对完全没有标注数据的任务,最明智的做法是先借助于无监督技术(如聚类/降维)分析数据,然后做一些数据标注,把原始的无监督任务转变为有监督任务进行求解。基于这些原因,本文不再介绍这大类相关的工作。
第二大类是T有标注数据,或者说T是个有监督任务。这类迁移学习技术又可以依据源任务是否有监督,以及训练顺序两个维度,大致分为四小类:
- 源任务S是无监督的,且源数据和目标数据同时用于训练:此时主要就是自监督(self-supervised)学习技术,代表工作有之后会讲到的CVT。
- 源任务S是有监督的,且源数据和目标数据同时用于训练:此时主要就是多任务(multi-task)学习技术,代表工作有之后会讲到的MT-DNN。
- 源任务S是无监督的,且先使用源数据训练,再使用目标数据训练(序贯训练):此时主要就是以BERT为代表的无监督模型预训练技术,代表工作有ELMo、ULMFiT、GPT/GPT-2、BERT、MASS、UNILM。
- 源任务S是有监督的,且先使用源数据训练,再使用目标数据训练(序贯训练):此时主要就是有监督模型预训练技术,类似CV中在ImageNet上有监督训练模型,然后把此模型迁移到其他任务上去的范式。代表工作有之后会讲到的CoVe。
何去何从
现状分析
先说说上表中四个类别的各自命运。以BERT为代表的无监督模型预训练技术显然是最有前途的。NLP中最不缺的就是无监督数据。只要堆计算资源就能提升效果的话,再简单不过了。
而无监督预训练的成功,也就基本挤压掉了自监督学习提升段位的空间。这里说的自监督学习不是泛指,而是特指同时利用无监督数据和当前有监督数据一起训练模型的方式。既然是同时训练,就不太可能大规模地利用无监督数据(要不然就要为每个特定任务都训练很久,不现实),这样带来的效果就没法跟无监督预训练方式相比。但自监督学习还是有存在空间的,比如现在发现在做有监督任务训练时,把语言模型作为辅助损失函数加入到目标函数中,可以减轻精调或多任务学习时的灾难性遗忘(Catastrophic Forgetting)问题,提升训练的收敛速度。所以有可能在训练时加入一些同领域的无监督数据,不仅能减轻遗忘问题,还可能因为让模型保留下更多的领域信息而提升最终模型的泛化性。但这个方向迎来大的发展可能性不大。
而类似CV中使用大规模有监督数据做模型预训练这条路,看着也比较暗淡,它自己单独不太可能有很大前景。几个原因:1) 这条路已经尝试了很久,没有很显著的效果提升。2) NLP中获取大规模标注数据很难,而且还要求对应任务足够复杂以便学习出的模型包含各种语言知识。虽然机器翻译任务很有希望成为这种任务,但它也存在很多问题,比如小语种的翻译标注数据很少,翻译标注数据主要还是单句形式,从中没法学习到背景信息或多轮等信息。但从另一个方面看,NLP搞了这么久,其实还是积累了很多标注或者结构化数据,比如知识图谱。如何把这些信息融合到具体任务中最近一直都是很活跃的研究方向,相信将来也会是。只是BERT出来后,这种做法的价值更像是打补丁,而不是搭地基了。
多任务学习作为代价较小的方法,前景还是很光明的。多个同领域甚至同数据上的不同任务同时训练,不仅能降低整体的训练时间,还能降低整体的预测时间(如果同时被使用),还能互相提升效果,何乐而不为。当然,多任务学习的目标一开始就不是搭地基。

上面说了这么多,其实想说的重点在下面。这些技术不一定非要单独使用啊,组合起来一起用,取长补短不是就皆大欢喜了嘛。
先回顾下现在的无监督模型预训练流程,如下图:

首先是利用大的无监督数据预训练通用模型,优化目标主要是语言模型(或其变种)。第二步,利用有监督数据精调上一步得到的通用模型。这么做的目的是期望精调以后的通用模型更强调这个特定任务所包含的语言信息。这一步是可选的(所以图中对应加了括号),有些模型框架下没有这个步骤,比如BERT里面就没有。第三步才是利用有监督数据中对应的标注数据训练特定任务对应的模型。
那这个流程接下来会怎么发展呢?
未来可期
上面已经对四类方法做了分别的介绍,包括对它们各自前途的简单判断,也介绍了当下效果最好的模型预训练流程。相信未来NLP的很多工作都会围绕这个流程的优化展开。猜测这个流程会继续发展为下面这个样子:
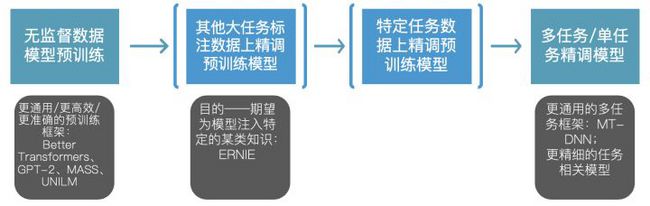
详细说明下每个步骤:
- 第一步还是利用大的无监督数据预训练通用模型。但这里面目前可以改进的点有很多,比如发展比Transformer更有效的特征抽取结构,现在的Evolved Transformer和Universal Transformer等都是这方面的探索。发展更有效更多样化的预训练模型目标函数。目前预训练模型的目标函数主要是(Masked) LM和Next Sentence Prediction (NSP),还是挺单一的。面向文档级背景或多轮这种长文本信息,未来应该会发展出更好的目标函数。比如有可能会发展出针对多轮对话这种数据的目标函数。
BERT主要面向的是NLU类型的任务,目前微软提出的MASS、UNILM从不同的角度把BERT框架推广到NLG类型的任务上了,细节我们之后会讲到。GPT-2利用更大的模型获得了更好的语言模型。更多更好的数据,更大的模型带来的改进有没有极限?目前还不知道,相信很多公司已经在做这方面的探索了。但这个游戏目前还是只有大公司能玩得起,训练通用大模型太耗钱了。提升训练效率,很自然的就是另一个很重要的优化方向。 - 第二步是利用其他大任务的标注数据或已有结构化知识精调第一步获得的通用模型。这一步不一定以单独的形式存在,它也可以放到第一步中,在预训练通用模型时就把这些额外信息注入进去,比如百度的ERNIE就是在预训练时就把实体信息注入进去了。既然人类在漫长的AI研究史上积累了大量各式各样的结构化数据,比如机器翻译标注数据,没理由不把它们用起来。相信未来会有很多知识融合(注入)这方面的工作。
- 第三步和前面流程的第二步相同,即利用当前任务数据进一步精调上一步得到的通用模型。这么做的目的是期望精调后的模型更强调这个特定任务所包含的语言信息。ELMo的实验结论是,加入这一步往往能提升下一步的特定任务有监督训练的收敛速度,但仅在部分任务上最终模型获得了效果提升(在另一部分任务上持平)。
另一种做法是把这一步与下一步的特定任务有监督训练放在一块进行,也即在特定任务有监督训练时把语言模型作为辅助目标函数加入到训练过程中,以期提升模型收敛速度,降低模型对已学到知识的遗忘速度,提升最终模型的效果。GPT的实验结论是,如果特定任务有监督训练的数据量比较大时,加入辅助语言模型能改善模型效果,但如果特定任务有监督训练的数据量比较小时,加入辅助语言模型反而会降低模型效果。但ULMFiT上的结论刚好相反。。所以就试吧。 - 利用多任务或者单任务建模方式在有监督数据集上训练特定任务模型。多任务的很多研究相信都能移植到这个流程当中。我们之后会介绍的微软工作MT-DNN就是利用BERT来做多任务学习的底层共享模型。论文中的实验表明加入多任务学习机制后效果有显著提升。相信在这个方向还会有更多的探索工作出现。在单任务场景下,原来大家发展出的各种任务相关的模型,是否能在无监督预训练时代带来额外的收益,这也有待验证。
总结下,未来NLP的主要工作可能都会围绕这个流程展开。对流程前面步骤的优化带来的收益比后面步骤大,也更难。所以诸君请自己拿捏吧~。
二、各类代表性工作
套用下前面对迁移学习分类的方式,把接下来要介绍的具体模型放到对应的模块里,这样逻辑会更清楚一些。
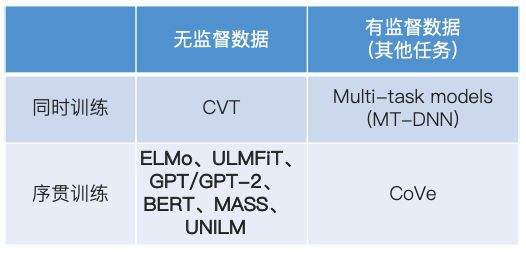
我们先介绍CoVe和CVT。
有监督模型预训练:CoVe
CoVe是在 McCann et al., Learned in Translation: Contextualized Word Vectors 这个论文中提出的。自然语言中的一词多义非常常见,比如“苹果手机”和“苹果香蕉”里的“苹果”,含义明显不同。以Word2Vec为代表的词表示方法没法依据词所在的当前背景调整表示向量。所以NLPer一直在尝试找背景相关的词表示法(Contextualized Word Representation)。CoVe就是这方面的一个尝试。
CoVe首先在翻译标注数据上预训练encoder2decoder模型。其中的encoder模块使用的是BiLSTM。训练好的encoder,就可以作为特征抽取器,获得任意句子中每个token的带背景词向量:
使用的时候,只要把 和 拼接起来就行。
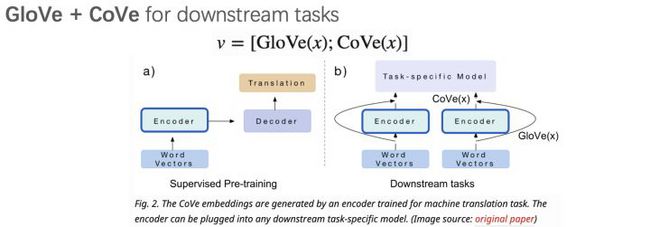
论文作者在分类和匹配下游任务对CoVe的效果做过验证,效果肯定是有一些提升了,但提升也不是很明显。
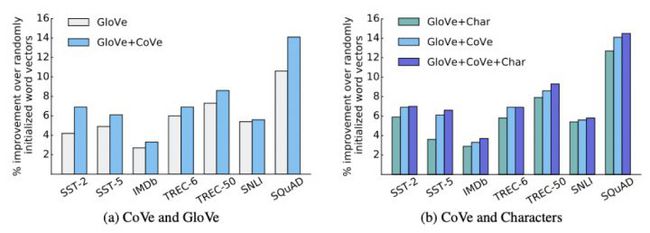
总结下CoVe的特点:
- 预训练依赖于有监督数据(翻译数据)。
- CoVe结果以特征抽取的方式融合到下游任务模型中,但下游任务还是要自定义对应的模型。
自监督学习同时训练:CVT
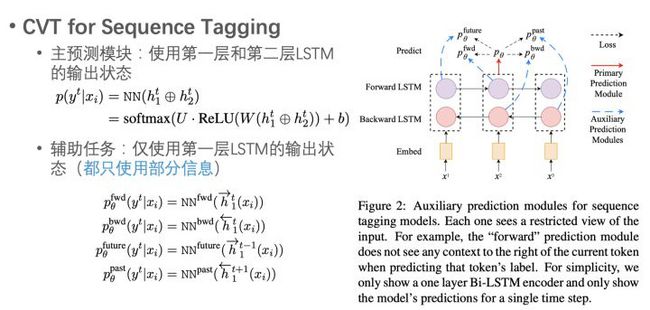
CVT (Cross-View Training)在利用有监督数据训练特定任务模型时,同时会使用无监督数据做自监督学习。Encoder使用的是2层的CNN-BiLSTM,训练过程使用标注数据和非标注数据交替训练。利用标注数据训练主预测模块,同时构造多个辅助模块,辅助模块利用非标注数据拟合主模块的预测概率。辅助模块的输入仅包含所有输入中的部分信息,这个思想和dropout有点像,可以提高模型的稳定性。不同的特定任务,辅助模块的构造方式不同,如何选输入中部分信息的方式也不同。
例如,对于序列标注任务,论文中以biLSTM第一层和第二层的状态向量拼接后输入进主预测模块。而4个辅助模块则使用了第一层的各个单向状态向量作为输入。 使用的是第一层前向LSTM当前词的状态向量, 使用的是第一层后向LSTM当前词的状态向量。 使用的是第一层前向LSTM前一个词的状态向量,而 使用的是第一层后向LSTM后一个词的状态向量。
作者也在多任务学习上验证了CVT带来效果提升。CVT使用多个标注数据和非标注数据交替训练。使用标注数据训练时,CVT随机选择一个任务,优化对应任务的主模块目标函数。使用非标注数据训练时,CVT为所有任务产生对应的辅助模块。这些辅助模块同时被训练,相当于构造了一些所有任务共用的标注数据。这种共用的训练数据能提升模型收敛速度。作者认为效果提升的主要原因是,同时训练多个任务能降低模型训练一个任务时遗忘其他任务知识的风险。
总结下CVT的特点:
- 在训练特定任务模型时加入无监督数据做自监督学习,获得了精度的提升。其中辅助模块的构建是关键。
- 嗯,需要为不同任务定制不同的辅助模块。
- 应用于MTL问题效果比ELMo好。
无监督模型预训练
ELMo
ELMo (Embedding from Language Models) 的目的是找到一种带背景的词向量表示方法,以期在不同的背景下每个词能够获得更准确的表示向量。
ELMo的使用过程分为以下三个步骤:

第一步是预训练阶段,ELMo利用2层的biLSTM和无监督数据训练两个单向的语言模型,它们统称为biLM。

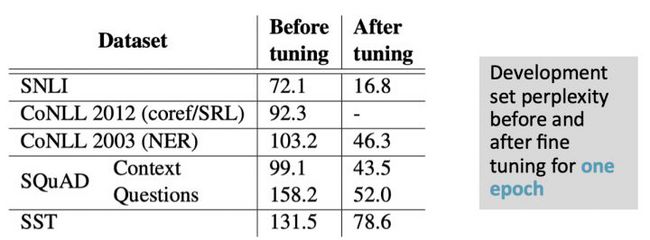
第二步利用特定任务的数据精调第一步得到的biLM。作者发现这步能显著降低biLM在特定任务数据上的PPL,结果如下图。但对特定任务最终的任务精度未必有帮助(但也不会降低任务精度)。作者发现在SNLI(推断)任务上效果有提升,但在SST-5(情感分析)任务上效果没变化。
第三步是训练特定的任务模型。任务模型的输入是上面已训练biLM的各层状态向量的组合向量。
其中 是经过softmax归一化后的权重, 是整体的scale参数。它们都是任务模型中待学习的参数。
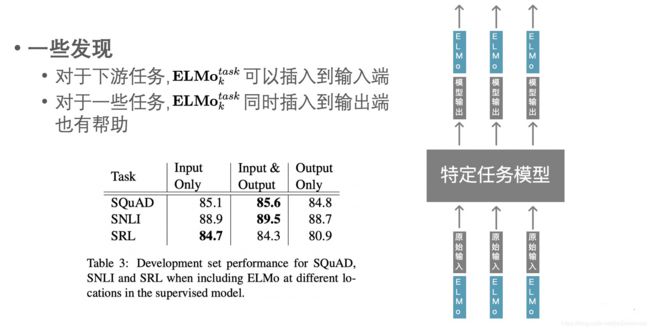
可以以额外特征的方式,加入到特定任务的输入和输出特征中。作者发现,对于某些任务,把 同时加入到输入和输出特征中效果最好,具体见下图。
作者发现,biLM底层LSTM的输出状态对句法任务(如POS)更有帮助,而高层LSTM的输出状态对语义任务(如WSD)更有帮助。ELMo对(标注)数据量少的有监督任务精度提升较大,对数据量多的任务效果提升就不明显了。这说明ELMo里存储的信息比较少,还是它主要功能是帮助有监督数据更好地提炼出其中的信息?
总结下ELMo的特点:
- 把无监督预训练技术成功应用于多类任务,获得了效果提升。
- ELMo以特征抽取的形式融入到下游任务中,所以不同下游任务依旧需要使用不同的对应模型。
- ELMo改进的效果依赖于下游任务和对应的模型,且改进效果也不是特别大。
ULMFiT & SiATL
ULMFiT (Universal Language Model Fine-tuning) 使用和ELMo类似的流程:
- 使用通用数据预训练LM,模型使用了3层的AWD-LSTM。
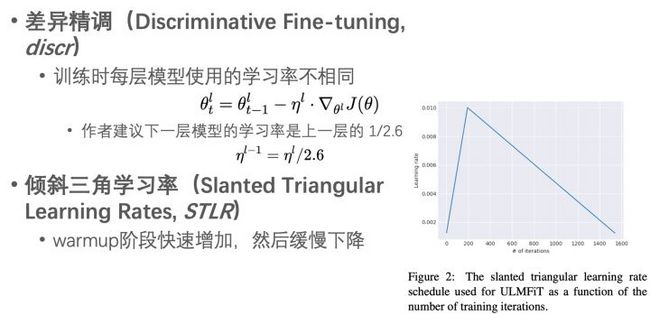
- 在特定任务数据上精调LM,其中使用到差异精调和倾斜三角lr两个策略。
- 以LM作为初始值,精调特定任务分类模型,其中使用到逐层解冻、差异精调和倾斜三角lr三个策略。经过AWD-LSTM之后,输出给分类器的向量为三个向量的拼接:
。
- 最后一层最后一个词对应的向量;
- 最后一层每个词向量做max pooling;
- 最后一层每个词向量做mean pooling。

论文中提出了几个优化策略,能够提升精调后模型的最终效果。

论文中的实验主要针对各种分类任务,相比于之前最好的结果,ULMFiT把分类错误率降低了18-24%。
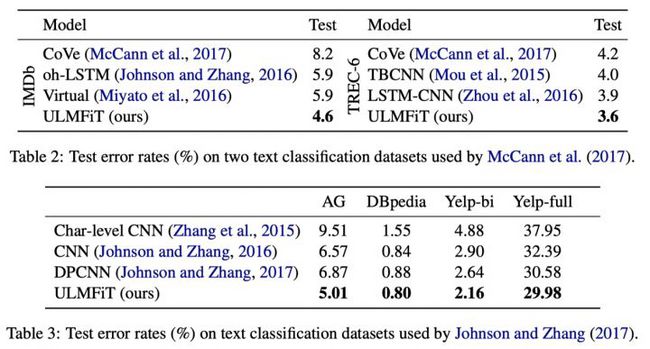
论文中也设计了实验来说明流程中第二步(在特定任务数据上精调LM)的作用。结果表明第二步的加入,能够让第三步的分类任务在很少的数据量下获得好的结果。只要使用 1%~10%的标注数据,就能达到不加第二步时的模型效果。
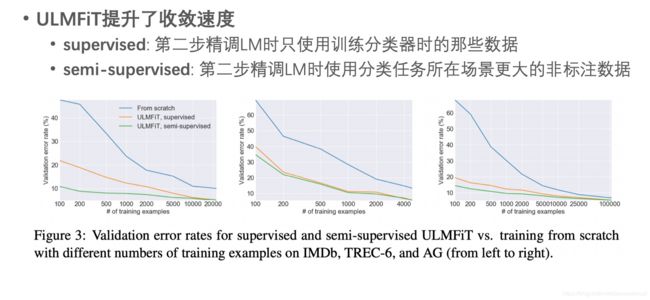
作者也设计了去除实验验证论文中提出的三个策略的效果:差异精调(discr)、倾斜三角lr(stlr)、逐层解冻(Freez)。结果表明相比于其他人提出的策略,这几个策略能获得更好的结果。而且,相比于不使用discr和stlr机制的精调策略(Full),ULMFiT模型更稳定,没出现灾难性遗忘。

之后的另一篇论文 An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models 建议了一些新的策略,解决精调时的灾难性遗忘问题。模型称为 SiATL (Single-step Auxiliary loss Transfer Learning)。SiATL只包含两个步骤:无监督数据预训练LM、精调分类模型。但在精调分类模型时,SiATL把LM作为辅助目标加入到优化目标函数当中。SiATL的第二步相当于把ULMFiT的第二步和第三步一起做了。所以它们的流程其实是一样的。
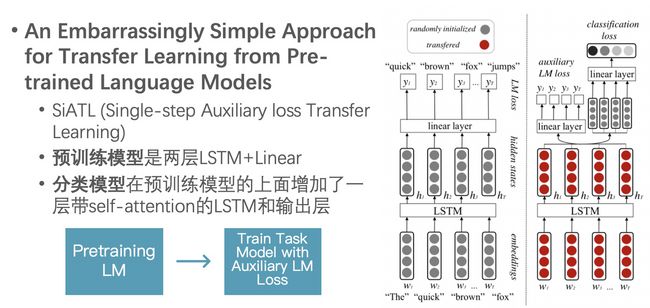
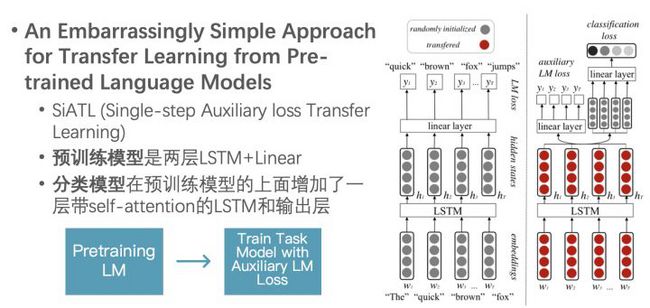
预训练模型使用的是两层LSTM+Linear,而分类模型在预训练模型的上面增加了一层带self-attention的LSTM和输出层。SiATL建议的几个策略:

论文发现辅助LM目标对于小数据集更有用,可能是辅助LM减轻了小数据集上的过拟合问题。其中的系数 ,论文实验发现初始取值为 0.2,然后指数下降到 0.1效果最好。 的取值需要考虑到 和 的取值范围。这个结论和ULMFiT中验证第二步流程作用的实验结果相同,也侧面说明了它们本质上差不多。
另一个发现是如果预训练用的无监督数据和任务数据所在领域不同,序贯解冻带来的效果更明显。这也是合理的,领域不同说明灾难性遗忘问题会更严重,所以迁移知识时要更加慎重,迁移过程要更慢。序贯解冻主要就是用途就是减轻灾难性遗忘问题。
论文还发现,和ULMFiT相比,SiATL在大数据集上效果差不多,但在小数据集要好很多。
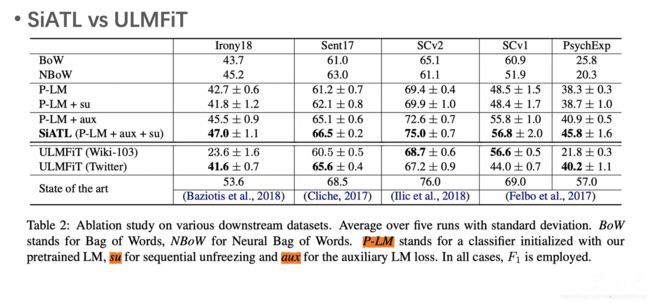
总结下 ULMFiT 和 SiATL:
- ULMFiT使用序贯训练的方式组合特定任务LM和任务目标函数,而SiATL使用同时训练的方式,也即加入辅助LM目标函数。
- 它们建议的策略都是在解决灾难性遗忘问题,也都解决的不错。可以考虑组合使用这些策略。
- 它们在小数据集上都提升明显,只要使用 1%~10% 的标注数据,就能达到之前的效果。
- 虽然它们只在分类任务上验证了各自的效果,但这些策略应该可以推广到其他任务上。
GPT/GPT-2
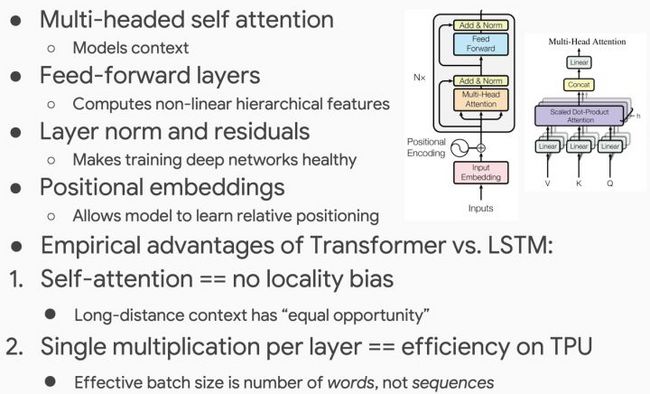
前面介绍的工作中预训练模型用的都是多层LSTM,而OpenAI GPT首次使用了Transformer作为LM预训练模型。GPT使用12层的Transformer Decoder训练单向LM,也即mask掉当前和后面的词。
在做精调时,使用最高层最后一个词的向量作为后续任务的输入,类似SiATL也加入了辅助LM目标函数。
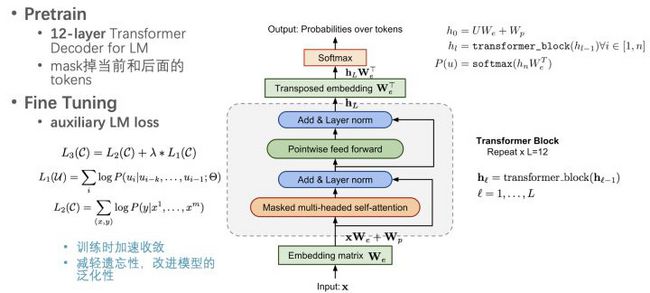
GPT的另一个大贡献是为下游任务引入了统一的模型框架,也即不再需要为特定任务定制复杂的模型结构了。不同的任务只需把输入数据做简单的转换即可。

GPT在多种类型的任务上做了实验,12个任务中的9个任务有提升,最高提升幅度在9%左右,效果相当不错。
针对预训练、辅助LM和Transformer,论文中做了去除实验,结果表明预训练最重要,去掉会导致指标下降14.8%,而Transformer改为LSTM也会导致指标下降5.6%。比较诡异的是去掉辅助LM的实验结果。去掉辅助LM,只在QQP (Quora Question Pairs)和NLI上导致指标下降。在其他任务上反而提升了指标。作者观察到的趋势是辅助LM对于大的数据集比小的数据集更有帮助。。这也跟ULMFiT和SiATL中的结论相反。
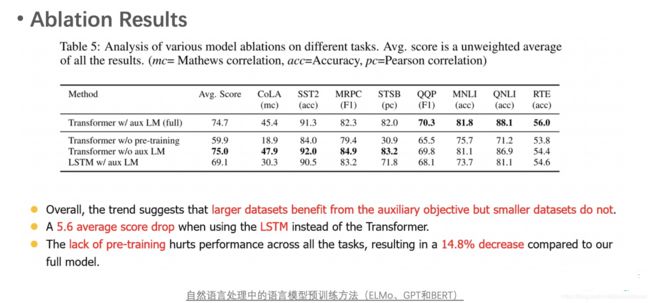
总结下GPT的主要贡献:
- 验证了Transformer在Unsupervised Pretraining中的有效性。
- 验证了更大的模型效果更好: 6 --> 12 层。
- 为下游任务引入了通用的求解框架,不再为任务做模型定制。
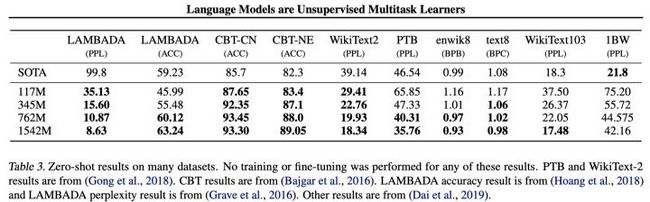
之后OpenAI又训练一个更大的模型,叫GPT-2。GPT-2把GPT中12层的Transformer提升到48层,参数数量是GPT的十几倍,达到了15亿。
GPT-2依旧使用单向LM训练语言模型,但使用数量更多、质量更好、覆盖面更广的数据进行训练。而且,GPT-2没有针对特定模型的精调流程了。作者想强调的是,预训练模型中已经包含很多特定任务所需的信息了,只要想办法把它们取出来直接用即可,可以不用为特定任务标注数据,真正达到通用模型的能力。
那,没有精调如何做特定任务呢?一些任务说明如下:

不做精调的GPT-2不仅在很多特定任务上已经达到了SOTA,还在生成任务上达到了吓人的精度。

BERT
和GPT一样,BERT的基本模型使用了Transformer,只是模型又变大了(12层变成了24层)。
相比于GPT的单向LM,BERT使用了双向LM。但显然预测时不能让待预测的词看到自己,所以需要把待预测词mask掉。BERT建议了masked LM机制,即随机mask输入中的 k%个词,然后利用双向LM预测这些词。

但mask时需要把握好度。mask太少的话,训练时每次目标函数中包含的词太少,训练起来就要迭代很多步。mask太多的话,又会导致背景信息丢失很多,与预测时的情景不符。而且,简单的mask会带来预训练和精调训练的不一致性:精调阶段,输入数据里是不mask词的。
BERT建议了以下的策略,解决这些问题:

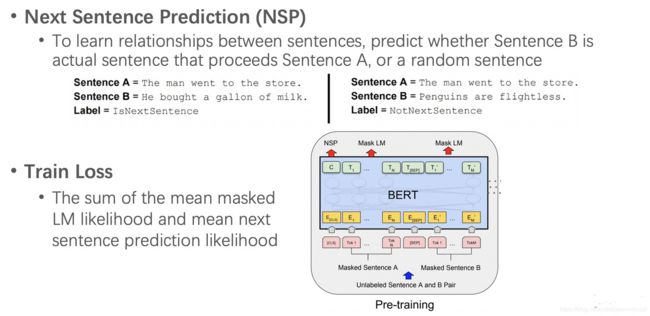
BERT的另一大贡献,是引入了新的预训练目标 Next Sentence Prediction (NSP) 。对于两个句子A和B,NSP预测B是不是A的下一个句子。训练时NSP的正样本就是从文档从随机选的两个临近句子,而负样本就是B是随机从文档中选取的,与A的位置没关系。NSP可以学习句子与句子间的关系。
预训练的目标函数是Masked LM和NSP的加和。
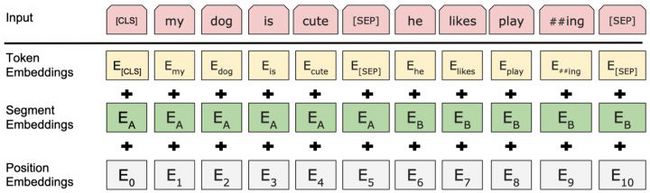
BERT的输入词向量是三个向量之和:
- Token Embedding:WordPiece tokenization subword词向量。
- Segment Embedding:表明这个词属于哪个句子(NSP需要两个句子)。
- Position Embedding:学习出来的embedding向量。这与Transformer不同,Transformer中是预先设定好的值。
BERT也为下游任务引入了通用的求解框架,不再为任务做模型定制。对于分类和匹配任务,下游任务只要使用第一个词 [CLS]对应的最上层输出词向量作为分类器的输入向量即可。对于抽取式QA和序列标注问题,使用每个词对应的最上层输出词向量作为下游任务的输入即可。
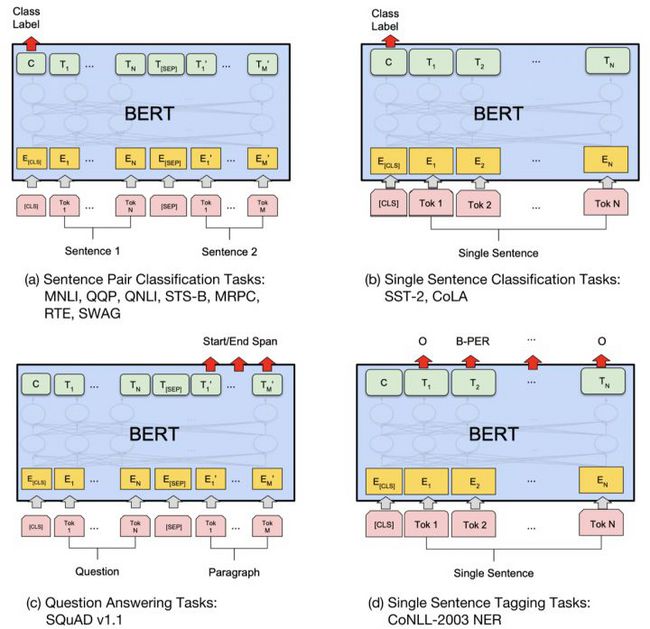
BERT的惊艳结果,引爆了NLP行业。BERT在11个任务上获得了最好效果,GLUE上达到了80.4%,提升了整整7.6个点,把SQuAD v1.1 F1又往上提升了1.5个点,达到了93.2 。
BERT的去除实验表明,双向LM和NSP带了的提升最大。
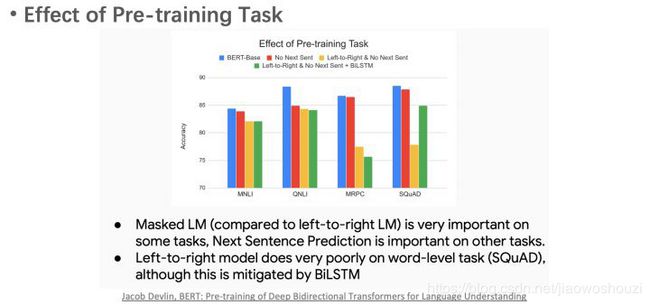
另一个结论是,增加模型参数数量可以提升模型效果。
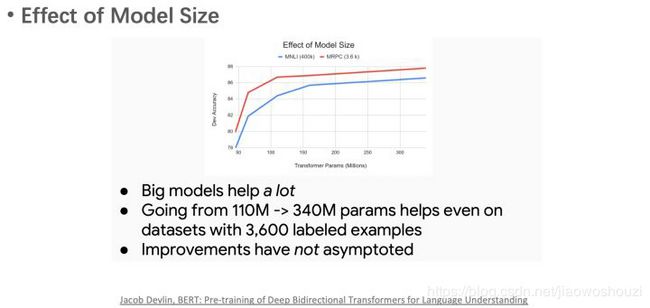
BERT预训练模型的输出结果,无非就是一个或多个向量。下游任务可以通过精调(改变预训练模型参数)或者特征抽取(不改变预训练模型参数,只是把预训练模型的输出作为特征输入到下游任务)两种方式进行使用。BERT原论文使用了精调方式,但也尝试了特征抽取方式的效果,比如在NER任务上,最好的特征抽取方式只比精调差一点点。但特征抽取方式的好处可以预先计算好所需的向量,存下来就可重复使用,极大提升下游任务模型训练的速度。

后来也有其他人针对ELMo和BERT比较了这两种使用方式的精度差异。下面列出基本结论:
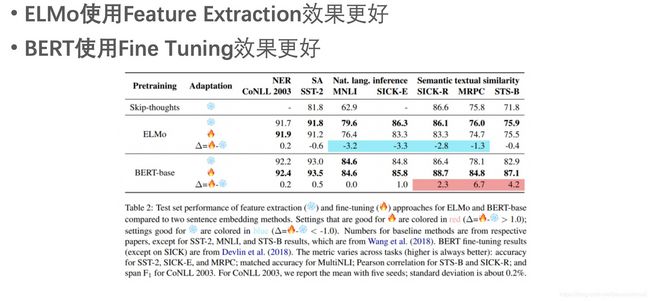

总结下BERT的主要贡献:
- 引入了Masked LM,使用双向LM做模型预训练。
- 为预训练引入了新目标NSP,它可以学习句子与句子间的关系。
- 进一步验证了更大的模型效果更好: 12 --> 24 层。
- 为下游任务引入了很通用的求解框架,不再为任务做模型定制。
- 刷新了多项NLP任务的记录,引爆了NLP无监督预训练技术。
ERNIE: Enhanced Representation through Knowledge Integration(Baidu/2019)
百度提出的ERNIE模型主要是针对BERT在中文NLP任务中表现不够好提出的改进。我们知道,对于中文,bert使用的基于字的处理,在mask时掩盖的也仅仅是一个单字,举个栗子:
我在上海交通大学玩泥巴-------> 我 在 上 海 [mask] 交 通 【mask】学 玩 【mask】 巴。
作者们认为通过这种方式学习到的模型能很简单地推测出字搭配,但是并不会学习到短语或者实体的语义信息, 比如上述中的【上海交通大学】。于是文章提出一种知识集成的BERT模型,别称ERNIE。ERNIE模型在BERT的基础上,加入了海量语料中的实体、短语等先验语义知识,建模真实世界的语义关系。
在具体模型的构建上,也是使用的Transformer作为特征抽取器。这里如果对于特征抽取不是很熟悉的同学,强烈推荐张俊林老师的"放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较"。
那么怎么样才能使得模型学习到文本中蕴含的潜在知识呢?不是直接将知识向量直接丢进模型,而是在训练时将短语、实体等先验知识进行mask,强迫模型对其进行建模,学习它们的语义表示。
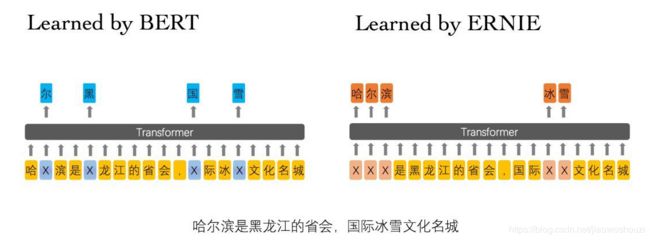
具体来说, ERNIE采用三种masking策略:
-
Basic-Level Masking: 跟bert一样对单字进行mask,很难学习到高层次的语义信息;
-
Phrase-Level Masking: 输入仍然是单字级别的,mask连续短语;
-
Entity-Level Masking: 首先进行实体识别,然后将识别出的实体进行mask。
经过上述mask训练后,短语信息就会融入到word embedding中了

此外,为了更好地建模真实世界的语义关系,ERNIE预训练的语料引入了多源数据知识,包括了中文维基百科,百度百科,百度新闻和百度贴吧(可用于对话训练)。关于论文后面的试验就不再赘述。
ERNIE: Enhanced Language Representation with Informative Entities(THU/ACL2019)
本文的工作也是属于对BERT锦上添花,将知识图谱的一些结构化信息融入到BERT中,使其更好地对真实世界进行语义建模。也就是说,原始的bert模型只是机械化地去学习语言相关的“合理性”,而并学习不到语言之间的语义联系,打个比喻,就比如调包侠只调掉包,而不懂每个包里面具体是什么含义。于是,作者们的工作就是如何将这些额外的知识告诉bert模型,而让它更好地适用于NLP任务。
但是要将外部知识融入到模型中,又存在两个问题:
Structured Knowledge Encoding: 对于给定的文本,如何高效地抽取并编码对应的知识图谱事实;
Heterogeneous Information Fusion: 语言表征的预训练过程和知识表征过程有很大的不同,它们会产生两个独立的向量空间。因此,如何设计一个特殊的预训练目标,以融合词汇、句法和知识信息又是另外一个难题。
为此,作者们提出了ERNIE模型,同时在大规模语料库和知识图谱上预训练语言模型:
抽取+编码知识信息: 识别文本中的实体,并将这些实体与知识图谱中已存在的实体进行实体对齐,具体做法是采用知识嵌入算法(如TransE),并将得到的entity embedding作为ERNIE模型的输入。基于文本和知识图谱的对齐,ERNIE 将知识模块的实体表征整合到语义模块的隐藏层中。
语言模型训练: 在训练语言模型时,除了采用bert的MLM和NSP,另外随机mask掉了一些实体并要求模型从知识图谱中找出正确的实体进行对齐(这一点跟baidu的entity-masking有点像)。
okay,接下来看看模型到底长啥样?
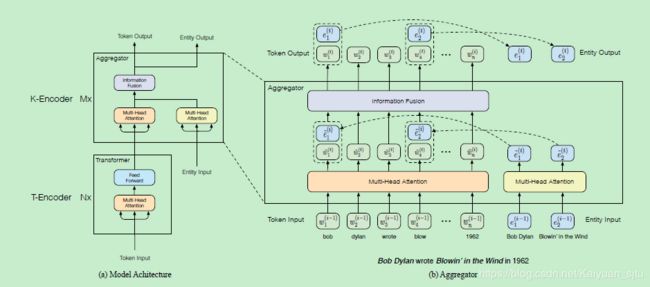
如上图,整个模型主要由两个子模块组成:
底层的textual encoder (T-Encoder),用于提取输入的基础词法和句法信息,N个;
高层的knowledgeable encoder (K-Encoder), 用于将外部的知识图谱的信息融入到模型中,M个。
knowledgeable encoder
改进的预训练
除了跟bert一样的MLM和NSP预训练任务,本文还提出了另外一种适用于信息融合的预训练方式,denoising entity auto-encoder (dEA). 跟baidu的还是有点不一样,这里是有对齐后的entity sequence输入的,而百度的是直接去学习entity embedding。dEA 的目的就是要求模型能够根据给定的实体序列和文本序列来预测对应的实体: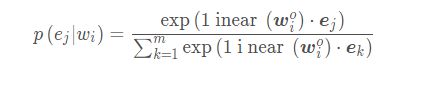
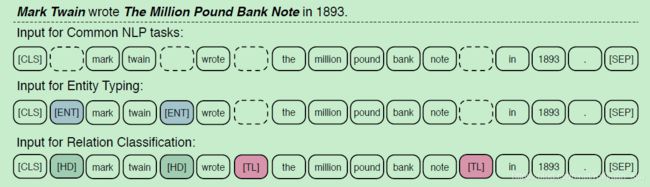
为了使得模型可以更广泛地适用于不同的NLP任务,作者也学习BERT设计了不同的特殊的token:
- 【CLS】:该token含有句子信息的表示,可适用于一般任务
- 【HD】和【TL】:该token表示关系分类任务中的头实体和尾实体(类似于传统关系分类模型中的位置向量),然后使用【CLS】来做分类;
- 【ENT】:该token表示实体类型,用于entity typing等任务。
Cross-lingual Language Model Pretraining(Facebook/2019)
对于BERT的改进可以大体分为两个方向:第一个是纵向,即去研究bert模型结构或者算法优化等方面的问题,致力于提出一种比bert效果更好更轻量级的模型;第二个方向是横向,即在bert的基础上稍作修改去探索那些vanilla bert还没有触及的领域。直观上来看第二个方向明显会比第一个方向简单,关键是出效果更快。本文就属于第二类。
我们知道,bert预训练的语料全是单语言的,所以可想而知最终的模型所适用的范围基本也是属于单语范围的NLP任务,涉及到跨语言的任务可能表现就不那么好。基于此,作者们提出了一种有效的跨语言预训练模型,Cross-lingual Language Model Pretraining(XLMs)。 XLMs可以认为是跨语言版的BERT,使用了两种预训练方式
- 基于单语种语料的无监督学习
- 基于跨语言的平行语料的有监督学习
其在几个多语任务上比如XNLI和机器翻译都拉高了SOTA。那么我们就来看看具体的模型,整体框架和BERT是非常类似,修改了几个预训练目标。
Shared sub-word vocabulary
目前的词向量基本都是在单语言语料集中训练得到的,所以其embedding不能涵盖跨语言的语义信息。为了更好地将多语言的信息融合在一个共享的词表中,作者在文本预处理上使用了字节对编码算法(Byte Pair Encoding (BPE)),大致思想就是利用单个未使用的符号迭代地替换给定数据集中最频繁的符号对(原始字节)。这样处理后的词表就对语言的种类不敏感了,更多关注的是语言的组织结构。
关于BEP的具体栗子可以参考:Byte Pair Encoding example
Causal Language Modeling (CLM)
这里的CLM就是一个传统的语言模型训练过程,使用的是目前效果最好的Transformer模型。对于使用LSTM 的语言模型,通过向 LSTM 提供上一个迭代的最后隐状态来执行时间反向传播 (backpropagation through time, BPTT)。而对于 Transformer,可以将之前的隐状态传递给当前的 batch,为 batch 中的第一个单词提供上下文。但是,这种技术不能扩展到跨语言设置,因此在这里作者们进行了简化,只保留每个 batch 中的第一个单词,而不考虑上下文。
Masked Language Modeling (MLM)
这一个预训练目标同BERT的MLM思想相同,唯一不同的就是在于模型输入。BERT的输入是句子对,而XLM使用的是随机句子组成的连续文本流。此外,为了避免采样不均,对相对频繁的输出采用与频率倒数的平方根成正比的权重从多项式分布中进行子采样。
Translation Language Modeling (TLM)
这一部分应该是对跨语言任务取得提升的最大原因。不同于以上两个预训练模型(单语言语料训练 + 无监督训练),翻译语言模型使用的是有监督的跨语言并行数据。如下图所示输入为两种并行语言的拼接,同时还将BERT的原始embedding种类改进为代表语言ID的Laguage embedding和使用绝对位置的Position embedding。这些新的元数据能够帮助模型更好地学习不同语言相关联Token之间的关系信息。
TLM训练时将随机掩盖源语言和目标语言的token,除了可以使用一种语言的上下文来预测该Token之外(同BERT),XLM还可以使用另一种语言的上下文以及Token对应的翻译来预测。这样不仅可以提升语言模型的效果还可以学习到source和target的对齐表示。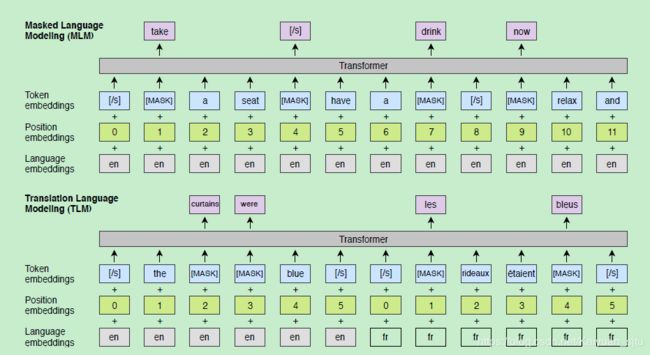
MASS: Masked Sequence to Sequence Pre-training for Language Generation(Microsoft/2019)
BERT只能做NLU类型的任务,无法直接用于文本产生式(NLG)类型的任务,如摘要、翻译、对话生成。NLG的基本框架是encoder2decoder,微软的MASS (MAsked Sequence to Sequence pre-training)把BERT推广到NLG任务。MASS的结构如下,它的训练数据依旧是单句话,但是会随机mask这句话中连续的 k个词,然后把这些词放入decoder模块的相同位置,而encoder中只保留未被mask的词。MASS期望decoder利用encoder的信息和decoder前面的词,预测这些被mask的词。
BERT的大火,也带动了NLP届的pre-training大火,受到bert的启发,作者们提出联合训练encoder和decoder的模型:Masked Sequence to Sequence Pre-training for Language Generation(MASS),框架如下: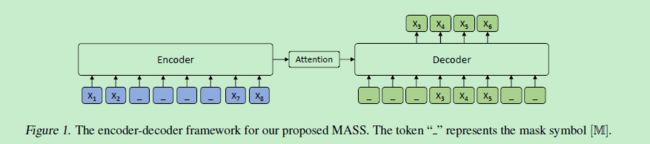
训练步骤主要分为两步:
- Encoder: 输入为被随机mask掉连续部分token的句子,使用Transformer对其进行编码;这样处理的目的是可以使得encoder可以更好地捕获没有被mask掉词语信息用于后续decoder的预测;
- Decoder: 输入为与encoder同样的句子,但是mask掉的正好和encoder相反,和翻译一样,使用attention机制去训练,但只预测encoder端被mask掉的词。该操作可以迫使decoder预测的时候更依赖于source端的输入而不是前面预测出的token,防止误差传递

比较有意思的是,BERT和GPT都是MASS的特例。当 k=1时,也即随机mask单个词时,MASS就退化成BERT;当 k=句子长度 时,也即mask所有词时,MASS就退化成GPT,或者标准的单向LM。(当k=m时,即encoder完全mask掉,decoder输入为完整句子,该形式与OPENAI的GPT模型一致)
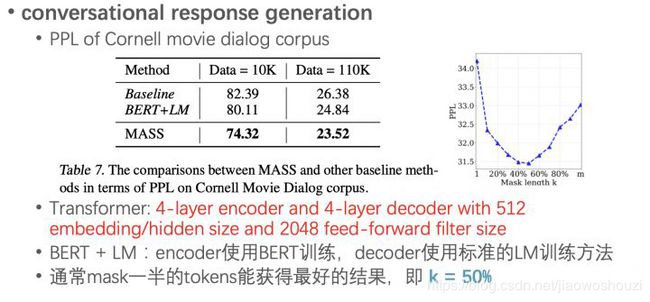
论文中使用了4层的Transformer作为encoder和decoder,跟encoder使用BERT,decoder
使用标准单向LM的框架BERT+LM做了效果对比,PPL上降低了不少。而且作者也对比了 k 取不同值时的效果变化,结果发现在多个任务上它取50%-70%句子长度都是最优的。
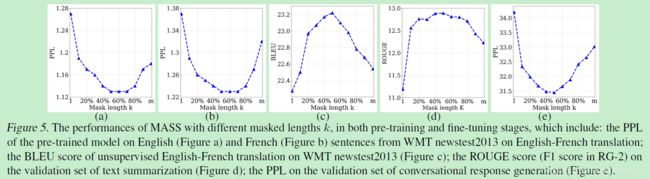
为什么MASS能取得比较好的效果?作者给出了以下解释:
- Encoder中mask部分tokens,迫使它理解unmasked tokens。
- Decoder中需要预测masked的连续tokens,让decoder能获取更多的语言信息。
- Decoder中只保留了masked的tokens,而不是所有的tokens,迫使decoder也会尽量从encoder中抽取信息。
作者也做了两个去除实验验证上面的后两条解释。

总结下MASS的特点:
- 把BERT推广到NLG类型任务,并且统一了BERT和传统单向LM框架。
- 实验表明MASS效果比BERT+LM好,但实验使用的模型太小,不确定这种优势在模型变大后是否还会存在。
Unified Language Model Pre-training for Natural Language Understanding and Generation(Microsoft/2019)
UNILM (UNIfied pretrained Language Model)是微软另一波人最近放出的论文。UNILM同时训练BERT中的双向LM、GPT中的单向LM和seq2seq中的LM。用的方法也很自然,核心思想在Transformer那篇论文中其实就已经在用了。
这个就更炸了,也是微软的最近才放出的工作,直接预训练了一个微调后可以同时用于自然语言理解和自然语言生成下游任务的模型:UNIfied pre-trained Language Model (UNILM)。
看完论文之后会发现非常自然,使用的核心框架还是Transformer,不同的是预训练的目标函数结合了以下三个:
- 单向语言模型(同ELMO/GPT)
- 双向语言模型(同BERT)
- seq2seq语言模型(同上一篇)

注意哦,这里的Transformer是同一个,即三个LM目标参数共享,有点multi-task learning的感觉,可以学习到更general的文本表示。
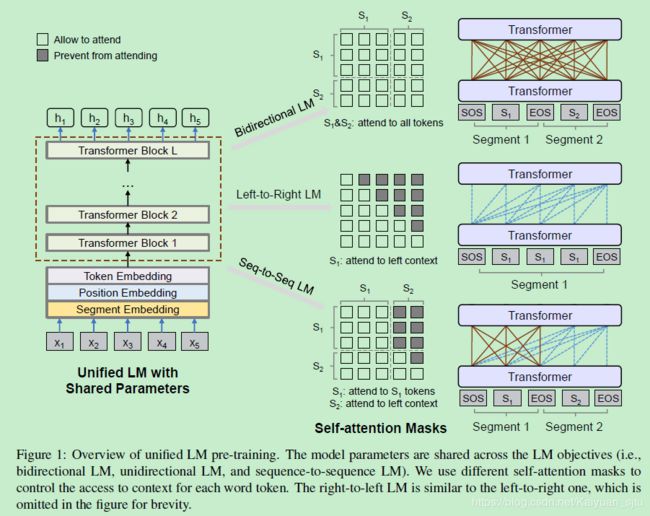
Input Representation
模型的输入是一个序列,对于单向LM是一个文本片段,对于双向LM和seq2seq LM是两段文本。embedding模式使用的是跟BERT一样的三类:
- token embedding:使用subword unit
- position embedding:使用绝对位置
- segment embedding:区分第一段和第二段
另外,[SOS]为输入序列起始标志; [EOS]为在NLU任务中为两个segment的分界标志,在NLG任务中为解码结束标志。
Backbone Network: Transformer

Unidirectional LM
对于单向LM(left-to-right or right-to-left),我们在做attention的时候对每一个词只能attend其一个方向的上下文。如对left-to-right LM, 我们就只能attend该词左边的信息,需要将右侧的词给mask掉;对于right-to-left LM也是同理。这样我们得到的Mask矩阵就是一个上三角或者下三角。
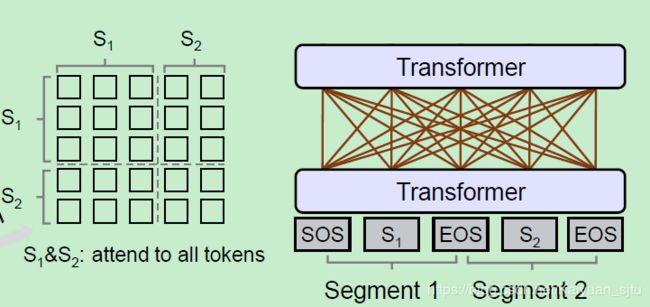
Bidirectional LM
和BERT一样,双向LM在训练时可以看到左边和右边的信息,所以这里的Mask矩阵全是0,表示全局信息可以attend到该token上
Sequence-to-Sequence LM
对于seq2seq LM,情况稍微复杂一点点,有点像上述两个Mask矩阵的结合版本。该模型输入为两个segment S1 S1S1和S2 S2S2,表示为“[SOS] t1 t2 [EOS] t3 t4 t5 [EOS]”,encoder是双向的即有四个token可以attend到t1 和t2上;decoder是单向的,仅仅能attend到一个方向的token以及encoder的token,以t4为例,它只能有6个token可以attend。
在训练时会随机mask掉两个segment中的token,然后让模型去预测被mask掉的词。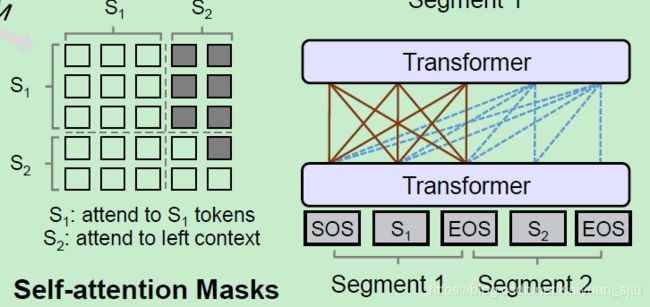
Next Sentence Prediction
对于双向LM,作者也设置了NSP预训练任务,除了特殊TOKEN不一样,其他跟bert是一样的。
UNILM中的核心框架还是Transformer,只是用无监督数据预训练模型时,同时以双向LM、单向LM和seq2seq LM为目标函数。这些目标函数共享一个Transformer结构,训练也都使用了类似BERT中的 [MASK]机制。
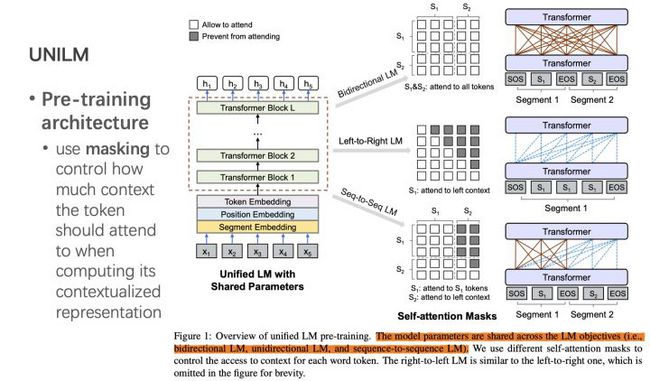
和BERT的双向LM不同的是,单向LM在做self-attention时不能使用这个词后面的词。seq2seq LM在做decoder 预测时也有类似的约束,做self-attention时能使用encoder中的所有词,以及decoder中当前词(替换为 [MASK]了)和前面的词,而不能使用decoder中这个词后面的词。UNILM在做self-attention时通过mask机制来满足这些约束,也即在softmax函数中把后面词对应的向量元素值改为 -∞。
seq2seq LM是把两个句子拼起来(和BERT相同)直接输入一个Transformer(只是预测encoder和decoder中被mask的词时,对self-attention使用了不同的约束条件),所以encoder和decoder使用的是同一个Transformer。seq2seq LM的训练样本,和NSP任务类似,为连续的两个句子,然后随机mask掉两个句子中的词让模型进行预测。
对词随机mask的机制和BERT类似,只是会以一定概率mask临近的两个或三个词,具体说明如下:

训练时目标函数的设定也参照BERT,只是要同时兼顾双向LM、单向LM和seq2seq LM。作者使用的模型大小同 ,也即用了24层的Transformer。

精调阶段,对于NLU类型的任务UNILM和BERT相同。对于NLG类型的任务,UNILM随机mask decoder中的一些词,然后再预测它们。以下是UNILM应用于生成式QA任务的做法,效果提升很明显。

对于GLUE的所有任务,UNILM据说是首次不添加外部数据打赢BERT的模型!
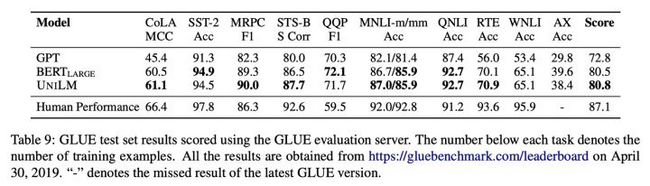
总结下UNILM的特点:
- 预训练同时训练双向LM、单向LM和seq2seq LM,使用
mask机制解决self-attention中的约束问题。 - 可以处理NLU和NLG类型的各种任务。
- 在GLUE上首次不加外部数据打赢了BERT。
多任务学习:MT-DNN
MT-DNN (Multi-Task Deep Neural Network)是去年年底微软的一篇工作,思路很简单,就是在MTL中把BERT引入进来作为底层共享的特征抽取模块。

预训练就是BERT,精调时每个batch随机选一个任务进行优化。整体算法步骤如下:

MT-DNN在GLUE上效果比BERT好不少,当然主要原因可能是加入了额外的数据了。作者也对比了多任务与单任务的结果,多任务确实能给每个任务都带来效果提升。
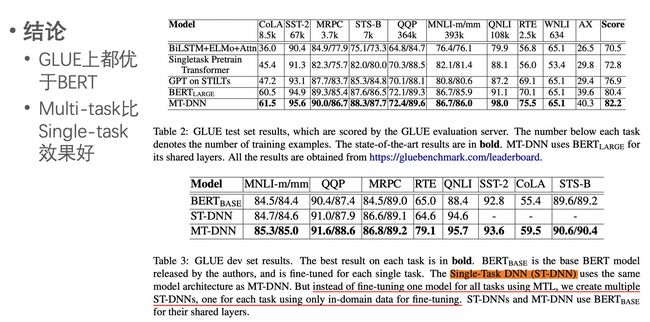
总结下MT-DNN的特点:
- 框架简单明了:MT-DNN = BERT + MTL。
XLNet
这两天,XLNet又开始屠屏幕。从实验数据看,在某些场景下,确实XLNet相对Bert有很大幅度的提升。感觉Bert打开两阶段模式的魔法盒开关后,在这条路上,会有越来越多的同行者,而XLNet就是其中比较引人注目的一位。当然,估计很快我们会看到更多的这个模式下的新工作。未来两年,在两阶段新模式(预训练+Finetuning)下,应该会有更多的好工作涌现出来。根本原因在于:这个模式的潜力还没有被充分挖掘,貌似还有很大的提升空间。当然,这也意味着NLP在未来两年会有各种技术或者应用的突破,现在其实是进入NLP领域非常好的时机。
那么XLNet和Bert比,有什么异同?有什么模型方面的改进?在哪些场景下特别有效?原因又是什么?本文通过论文思想解读及实验结果分析,试图回答上述问题。
首先,XLNet引入了自回归语言模型以及自编码语言模型的提法,简单说明下。
自回归语言模型(Autoregressive LM)
在ELMO/BERT出来之前,大家通常讲的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的LM被称为自回归语言模型。GPT 就是典型的自回归语言模型。ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归LM,这个跟模型具体怎么实现有关系。ELMO是做了两个方向(从左到右以及从右到左两个方向的语言模型),但是是分别有两个方向的自回归LM,然后把LSTM的两个方向的隐节点状态拼接到一起,来体现双向语言模型这个事情的。所以其实是两个自回归语言模型的拼接,本质上仍然是自回归语言模型。
自回归语言模型有优点有缺点,缺点是只能利用上文或者下文的信息,不能同时利用上文和下文的信息,当然,貌似ELMO这种双向都做,然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不是太好。它的优点,其实跟下游NLP任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。
自编码语言模型(Autoencoder LM)
自回归语言模型只能根据上文预测下一个单词,或者反过来,只能根据下文预测前面一个单词。相比而言,Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
这种DAE LM的优缺点正好和自回归LM反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,这是好处。缺点是啥呢?主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的。DAE吗,就要引入噪音,[Mask] 标记就是引入噪音的手段,这个正常。
XLNet的出发点就是:能否融合自回归LM和DAE LM两者的优点。就是说如果站在自回归LM的角度,如何引入和双向语言模型等价的效果;如果站在DAE LM的角度看,它本身是融入双向语言模型的,如何抛掉表面的那个[Mask]标记,让预训练和Fine-tuning保持一致。当然,XLNet还讲到了一个Bert被Mask单词之间相互独立的问题,个人认为这个不太重要。
上文说过,Bert这种自编码语言模型的好处是:能够同时利用上文和下文,所以信息利用充分。对于很多NLP任务而言,典型的比如阅读理解,在解决问题的时候,是能够同时看到上文和下文的,所以当然应该把下文利用起来。在Bert原始论文中,与GPT1.0的实验对比分析也可以看出来,BERT相对GPT 1.0的性能提升,主要来自于双向语言模型与单向语言模型的差异。这是Bert的好处,很明显,Bert之后的改进模型,如果不能把双向语言模型用起来,那明显是很吃亏的。当然,GPT 2.0的作者不信这个邪,坚持沿用GPT 1.0 单向语言模型的旧瓶,装进去了更高质量更大规模预训练数据的新酒,而它的实验结果也说明了,如果想改善预训练语言模型,走这条扩充预序列模型训练数据的路子,是个多快好但是不省钱的方向。这也进一步说明了,预训练LM这条路,还远远没有走完,还有很大的提升空间,比如最简单的提升方法就是加大数据规模,提升数据质量。
但是Bert的自编码语言模型也有对应的缺点,就是XLNet在文中指出的,第一个预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失;另外一个是,Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的,XLNet则考虑了这种关系(关于这点原因是否可靠,后面会专门分析)。
上面两点是XLNet在第一个预训练阶段,相对Bert来说要解决的两个问题。
能不能类似Bert那样,比较充分地在自回归语言模型中,引入双向语言模型呢?因为Bert已经证明了这是非常关键的一点。这一点,想法简单,但是看上去貌似不太好做,因为从左向右的语言模型,如果我们当前根据上文,要预测某个单词Ti,那么看上去它没法看到下文的内容。具体怎么做才能让这个模型:看上去仍然是从左向右的输入和预测模式,但是其实内部已经引入了当前单词的下文信息呢?XLNet在模型方面的主要贡献其实是在这里。
XLNet是怎么做到这一点的呢?其实思路也比较简洁,可以这么思考:XLNet仍然遵循两阶段的过程,第一个阶段是语言模型预训练阶段;第二阶段是任务数据Fine-tuning阶段。它主要希望改动第一个阶段,就是说不像Bert那种带Mask符号的Denoising-autoencoder的模式,而是采用自回归LM的模式。就是说,看上去输入句子X仍然是自左向右的输入,看到Ti单词的上文Context_before,来预测Ti这个单词。但是又希望在Context_before里,不仅仅看到上文单词,也能看到Ti单词后面的下文Context_after里的下文单词,这样的话,Bert里面预训练阶段引入的Mask符号就不需要了,于是在预训练阶段,看上去是个标准的从左向右过程,Fine-tuning当然也是这个过程,于是两个环节就统一起来。当然,这是目标。剩下是怎么做到这一点的问题。
那么,怎么能够在单词Ti的上文中Contenxt_before中揉入下文Context_after的内容呢?你可以想想。XLNet是这么做的,在预训练阶段,引入Permutation Language Model的训练目标。什么意思呢?就是说,比如包含单词Ti的当前输入的句子X,由顺序的几个单词构成,比如x1,x2,x3,x4四个单词顺序构成。我们假设,其中,要预测的单词Ti是x3,位置在Position 3,要想让它能够在上文Context_before中,也就是Position 1或者Position 2的位置看到Position 4的单词x4。可以这么做:假设我们固定住x3所在位置,就是它仍然在Position 3,之后随机排列组合句子中的4个单词,在随机排列组合后的各种可能里,再选择一部分作为模型预训练的输入X。比如随机排列组合后,抽取出x4,x2,x3,x1这一个排列组合作为模型的输入X。于是,x3就能同时看到上文x2,以及下文x4的内容了。这就是XLNet的基本思想,所以说,看了这个就可以理解上面讲的它的初衷了吧:看上去仍然是个自回归的从左到右的语言模型,但是其实通过对句子中单词排列组合,把一部分Ti下文的单词排到Ti的上文位置中,于是,就看到了上文和下文,但是形式上看上去仍然是从左到右在预测后一个单词。
当然,上面讲的仍然是基本思想。难点其实在于具体怎么做才能实现上述思想。首先,需要强调一点,尽管上面讲的是把句子X的单词排列组合后,再随机抽取例子作为输入,但是,实际上你是不能这么做的,因为Fine-tuning阶段你不可能也去排列组合原始输入。所以,就必须让预训练阶段的输入部分,看上去仍然是x1,x2,x3,x4这个输入顺序,但是可以在Transformer部分做些工作,来达成我们希望的目标。具体而言,XLNet采取了Attention掩码的机制,你可以理解为,当前的输入句子是X,要预测的单词Ti是第i个单词,前面1到i-1个单词,在输入部分观察,并没发生变化,该是谁还是谁。但是在Transformer内部,通过Attention掩码,从X的输入单词里面,也就是Ti的上文和下文单词中,随机选择i-1个,放到Ti的上文位置中,把其它单词的输入通过Attention掩码隐藏掉,于是就能够达成我们期望的目标(当然这个所谓放到Ti的上文位置,只是一种形象的说法,其实在内部,就是通过Attention Mask,把其它没有被选到的单词Mask掉,不让它们在预测单词Ti的时候发生作用,如此而已。看着就类似于把这些被选中的单词放到了上文Context_before的位置了)。具体实现的时候,XLNet是用“双流自注意力模型”实现的,细节可以参考论文,但是基本思想就如上所述,双流自注意力机制只是实现这个思想的具体方式,理论上,你可以想出其它具体实现方式来实现这个基本思想,也能达成让Ti看到下文单词的目标。
这里简单说下“双流自注意力机制”,一个是内容流自注意力,其实就是标准的Transformer的计算过程;主要是引入了Query流自注意力,这个是干嘛的呢?其实就是用来代替Bert的那个[Mask]标记的,因为XLNet希望抛掉[Mask]标记符号,但是比如知道上文单词x1,x2,要预测单词x3,此时在x3对应位置的Transformer最高层去预测这个单词,但是输入侧不能看到要预测的单词x3,Bert其实是直接引入[Mask]标记来覆盖掉单词x3的内容的,等于说[Mask]是个通用的占位符号。而XLNet因为要抛掉[Mask]标记,但是又不能看到x3的输入,于是Query流,就直接忽略掉x3输入了,只保留这个位置信息,用参数w来代表位置的embedding编码。其实XLNet只是扔了表面的[Mask]占位符号,内部还是引入Query流来忽略掉被Mask的这个单词。和Bert比,只是实现方式不同而已。

上面讲的Permutation Language Model是XLNet的主要理论创新,所以介绍的比较多,从模型角度讲,这个创新还是挺有意思的,因为它开启了自回归语言模型如何引入下文的一个思路,相信对于后续工作会有启发。当然,XLNet不仅仅做了这些,它还引入了其它的因素,也算是一个当前有效技术的集成体。
个人感觉XLNet就是Bert、GPT 2.0和Transformer XL的综合体变身,首先,它通过PLM预训练目标,吸收了Bert的双向语言模型;然后,GPT2.0的核心其实是更多更高质量的预训练数据,这个明显也被XLNet吸收进来了;再然后,Transformer XL的主要思想也被吸收进来,它的主要目标是解决Transformer对于长文档NLP应用不够友好的问题。
以上是XLNet的几个主要改进点,有模型创新方面的,有其它模型引入方面的,也有数据扩充方面的。
三、实践、观点、总结
实践与建议
虽然前面介绍的很多模型都能找到实现代码。但从可用性来说,对于NLU类型的问题,基本只需考虑ELMo,ULMFiT和BERT。而前两个没有中文的预训练模型,需要自己找数据做预训练。BERT有官方发布的中文预训练模型,很多深度学习框架也都有BERT的对应实现,而且BERT的效果一般是最好的。但BERT的问题是速度有点慢,使用12层的模型,对单个句子(30个字以内)的预测大概需要100~200毫秒。如果这个性能对你的应用没问题的话,建议直接用BERT。
对于分类问题,如果特定任务的标注数据量在几千到一两万,可以直接精调BERT,就算在CPU上跑几十个epoches也就一两天能完事,GPU上要快10倍以上。如果标注数据量过大或者觉得训练时间太长,可以使用特征抽取方式。先用BERT抽取出句子向量表达,后续的分类器只要读入这些向量即可。
调研论文中很多分类问题上测试了BERT的效果,确实比之前的模型都有提升,有些问题上提升很明显。下图给出了一些结果示例。
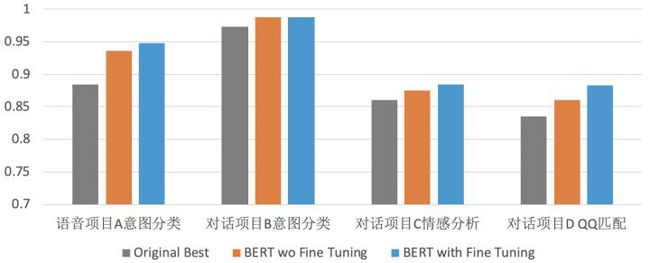
比如在常用的检索机器人FAQBot中,用户的一个query来了,FAQBot首先从标准问答库中检索出一些候选问题/答案,然后排序或匹配模块再计算query跟每个候选问题/答案的匹配度,再按这些匹配度从高到低排序,top1的结果返回给用户。上图中给出了一个QQ 匹配的结果,原始模型的准确度为83.5%,BERT精调后的模型准确度提升到88.3%。
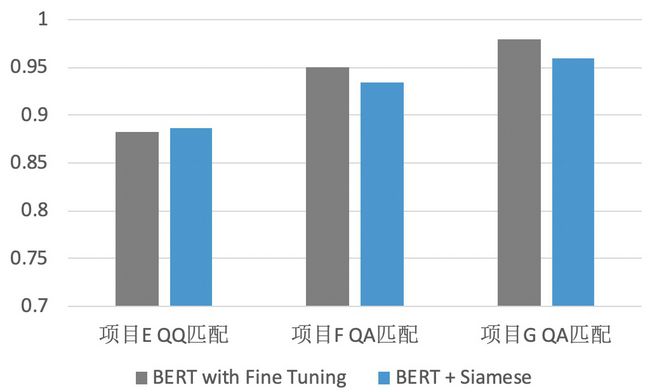
BERT当然可以直接用来计算两个句子的匹配度,只要把query和每个候选句子拼起来,然后走一遍BERT就能算出匹配度。这样做的问题是,如果有100个候选结果,就要算100次,就算把它们打包一起算,CPU上的时间开销在线上场景也是扛不住的。但如果使用Siamese结构,我们就可以把候选句子的BERT向量表达预先算好,然后线上只需要计算query的BERT向量表达,然后再计算query和候选句子向量的匹配度即可,这样时间消耗就可以控制在200ms以内了。
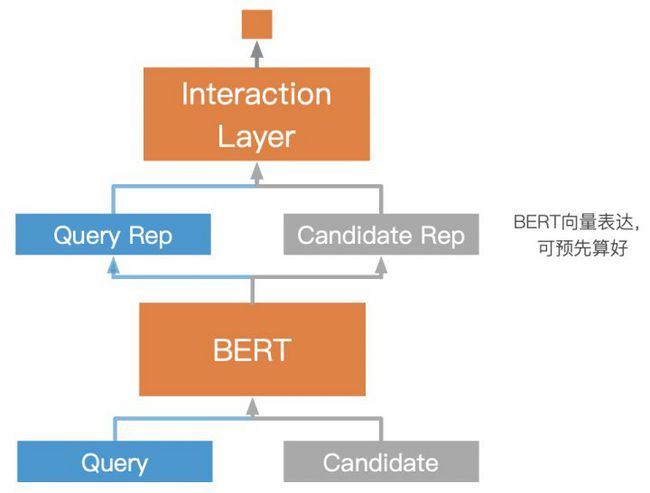
使用Siamese这种结构理论上会降低最终的匹配效果,之前也有相关工作验证过在一些问题上确实如此。调研论文有用户在三个数据上做了对比实验,发现在两个问题上效果确实略有下降,而在另一个问题上效果基本保持不变。估计只要后续交互层设计的合理,Siamese结构不会比原始BERT精调差很多。
观点
按理ELMo的想法很简单,也没什么模型创新,为什么之前就没人做出来然后引爆无监督模型预训练方向?BERT的一作Jacob Devlin认为主要原因是之前使用的数据不够多,模型不够大。无监督预训练要获得好效果,付出的代价需要比有监督训练大到1000到10w倍才能获得好的效果。之前没人想到要把数据和模型规模提高这么多。
为了让预训练的模型能对多种下游任务都有帮助,也即预训练模型要足够通用,模型就不能仅仅只学到带背景的词表示这个信息,还需要学到很多其他信息。而预测被mask的词,就可能要求模型学到很多信息,句法的,语义的等等。所以,相对于只解决某个下游特定任务,预训练模型要通用的话,就要大很多。目前发现只要使用更多(数量更多、质量更好、覆盖面更广)的无监督数据训练更大的模型,最终效果就会更优。目前还不知道这个趋势的极限在什么量级。
BERT虽然对NLU的各类任务都提升很大,但目前依旧存在很多待验证的问题。比如如何更高效地进行预训练和线上预测使用,如何融合更长的背景和结构化知识,如何在多模态场景下使用,在BERT之后追加各种任务相关的模块是否能带来额外收益等等。这些机会我在第一部分已经讲到,就不再赘述了。
总结和一点感(敢)想
最后,简单总结一下。
无监督预训练技术已经在NLP中得到了广泛验证。BERT成功应用于各种NLU类型的任务,但无法直接用于NLG类型的任务。微软最近的工作MASS把BERT推广到NLG类型任务,而UNILM既适用于NLU也适用于NLG任务,效果还比BERT好一点点。
相信未来NLP的很多工作都会围绕以下这个流程的优化展开:
在这个过程中,我们还收获了诸多副产品:
- 相对于biLSTM,Transformers在知识抽取和存储上效果更好,潜力还可发掘。它们之间的具体比较,推荐俊林老师的“放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较”,里面介绍的很清楚。
- 目前无监督模型预训练常用以下几种目标函数:
- 一般的LM。基于token的交叉熵。
- Masked LM。相比于一般的LM,masked LM能够使用双向tokens,且在模型训练和预测时的数据使用方式更接近,降低了它们之间的gap。
- Consecutive masked LM。Mask时不仅随机mask部分离散的token,还随机mask一些连续的tokens,如bi-grams、tri-grams等。这种consecutive mask机制是否能带来普遍效果提升,还待验证。
- Next Sentence Prediction。预测连续的两个句子是否有前后关系。
- 精调阶段,除了任务相关的目标函数,还可以考虑把LM作为辅助目标加到目标函数中。加入LM辅助目标能降低模型对已学到知识的遗忘速度,提升模型收敛速度,有些时候还能提升模型的精度。精调阶段,学习率建议使用linear warmup and linear decay机制,降低模型对已学到知识的遗忘速度。如果要精调效果,可以考虑ULMFiT中引入的gradual unfreezing和discriminative fine-tuning:机制。
- 使用数量更多、质量更好、覆盖面更广的无监督数据训练更大的模型,最终效果就会更优。目前还不知道这个趋势的极限在什么地方。
最后说一点自己的感想。
NLP中有一部分工作是在做人类知识或人类常识的结构化表示。有了结构化表示后,使用时再想办法把这些表示注入到特定的使用场景中。比如知识图谱的目标就是用结构化的语义网络来表达人类的所有知识。这种结构化表示理论上真的靠谱吗?人类的知识真的能完全用结构化信息清晰表示出来吗?显然是不能,我想这点其实很多人都知道,只是在之前的技术水平下,也没有其他的方法能做的更好。所以这是个折中的临时方案。
无监督预训练技术的成功,说明语言的很多知识其实是可以以非结构化的方式被模型学习到并存储在模型中的,只是目前整个过程我们并不理解,还是黑盒。相信以后很多其他方面的知识也能找到类似的非结构化方案。所以我估计知识图谱这类折中方案会逐渐被替代掉。当然,这只是我个人的理解或者疑惑。
参考资料
张俊林,【知乎专栏】深度学习前沿笔记
Lilian Weng, Generalized Language Models
McCann et al.2017, Learned in Translation: Contextualized Word Vectors
ELMo: Deep Contextual Word Embeddings, AI2 & University of Washington, 2018
The Illustrated Transformer
The Annotated Transformer
Ashish Vaswani, et al. “Attention is all you need.” NIPS 2017
Jacob Devlin, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT)
To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks
Yifan Qiao, et al. "Understanding the Behaviors of BERT in Ranking", 2019
Kevin Clark et al. “Semi-Supervised Sequence Modeling with Cross-View Training.”EMNLP 2018
Matthew E. Peters, et al. “Deep contextualized word representations.” NAACL-HLT 2017
Jeremy Howard and Sebastian Ruder. “Universal language model fine-tuning for text classification.” ACL 2018
Alexandra Chronopoulou, et al. “An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models”, 2019
Alec Radford et al. “Improving Language Understanding by Generative Pre-Training”. OpenAI Blog, June 11, 2018
Alec Radford, et al. “Language Models are Unsupervised Multitask Learners”, Open AI
Kaitao Song, et al. "MASS: Masked Sequence to Sequence Pre-training for Language Generation", 2019
Li Dong, et al. "Unified Language Model Pre-training for Natural Language Understanding and Generation", 2019
Xiaodong Liu, el al. "Multi-Task Deep Neural Networks for Natural Language Understanding", 2019