【MOOC】Python网络爬虫与信息提取-北京理工大学-part 2
【第二周】 网络爬虫之提取
Beautiful Soup库入门
Beautiful Soup库的安装与测试
中文文档:Beautiful Soup 4.4.0 文档
安装方式:pip install beautifulsoup4
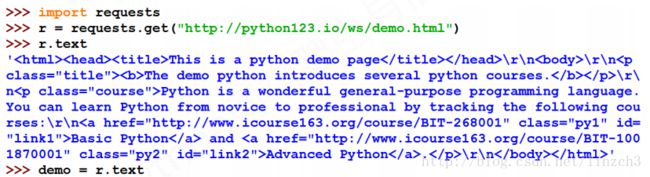
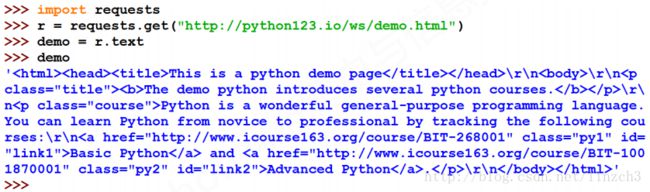
测试网站(http://python123.io/ws/demo.html)的源代码(当然用requests库获取便可):
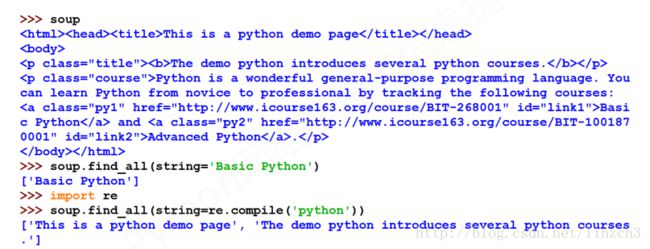
<html><head><title>This is a python demo pagetitle>head>
<body>
<p class="title"><b>The demo python introduces several python courses.b>p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Pythona> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Pythona>.p>
body>html>测试代码和对应的部分输出:
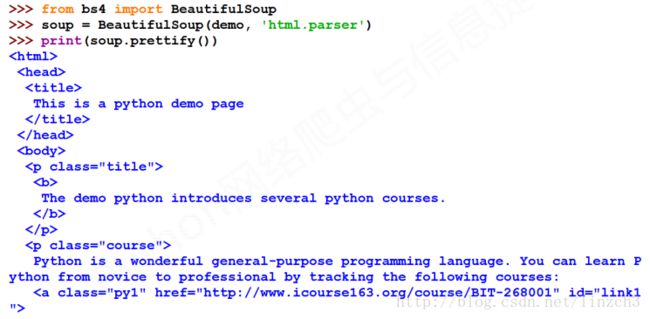
注: prettify函数的作用是:打印一下 soup 对象的内容,进行格式化输出,可以看到上面的该函数的输出的形式很适合我们直接阅读。另外,该函数使用得比较多,因此要多留意一下。更多的细节下面的“基于bs4库的HTML格式输出”章节。
常用使用方法:

Beautiful Soup库基本元素
Beautiful Soup库,也叫beautifulsoup4或 bs4,约定引用方式如下,即主要是用BeautifulSoup类:
from bs4 import BeautifulSoup对库的理解:

其他解析器:

对标签的理解:

对标签的进一步说明:

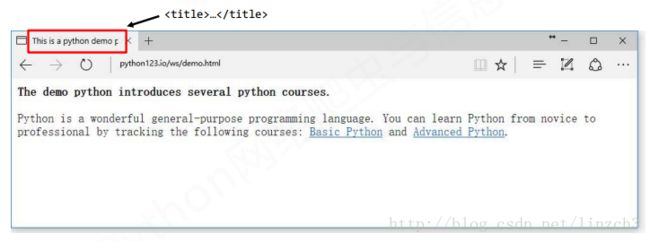
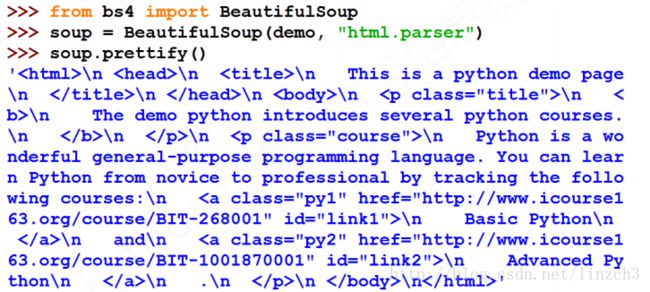
以之前的demo.html为例子:
在浏览器上显示为:
使用requests库爬取的效果:
具体分析demo的基本元素:

注意:
1.soup.a是指将soup中的名字为a的标签(在HMTL5中 代表 链接标签)提取出来
2.当HTML文档中存在多个相同对应内容时,soup.返回第一个
3.上面的tag的输出是将原先的tag的属性按照属性的字母序重新排列得到的。
原先的是:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Pythona> 输出的是:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Pythona> 

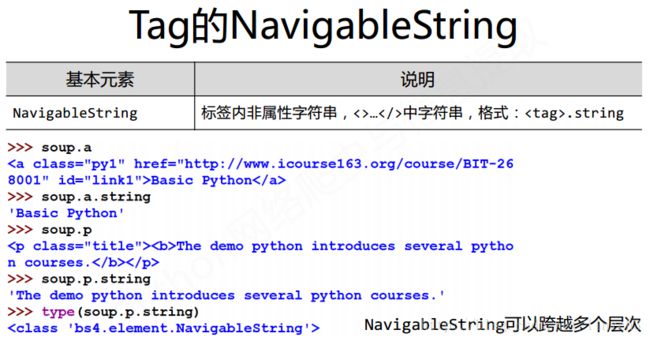
注:简单来说,Tag中的字符串即为NavigableString对象。
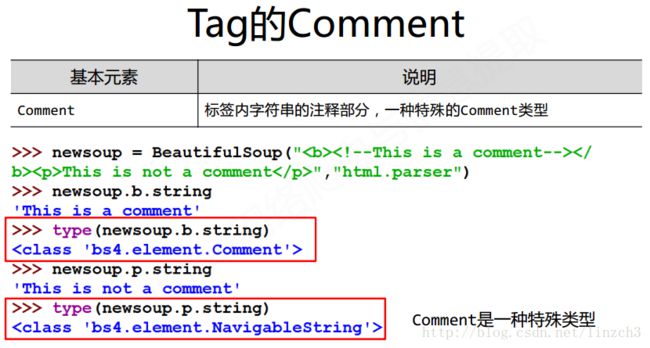
注:Commet这个元素我们一般用得比较少。而判断输出的string变量是Commet的,还是NavigableString的则要使用type()函数来判断。
基于bs4库的HTML内容遍历方法
掌握HTML内容遍历方法可帮助我们从一个节点出发到其他节点的信息。其遍历方法是我们提取HTML内容的重要手段。
仍旧以demo为例,其源代码为:
将其视为树(文档树)的形式,则有:

下面将介绍文档树的下行遍历、上行遍历、平行遍历。这3种遍历的形式如图:
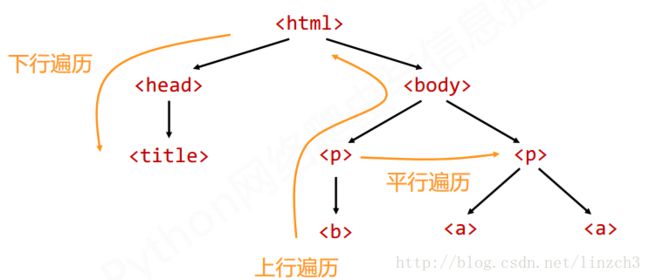
标签树的下行遍历
属性说明

实例输出

注意:对于标签节点的儿子节点,其除了是标签节点外还可能是字符串节点,比如上面的soup.body.contents的输出便是如此。可用len()函数获取儿子节点的数目。
用法总结
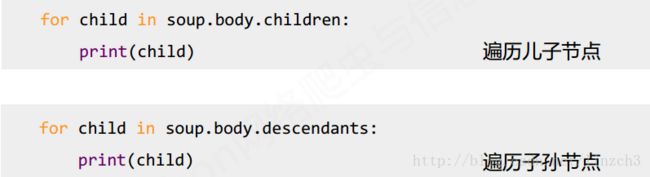
标签树的上行遍历
属性说明

实例输出1
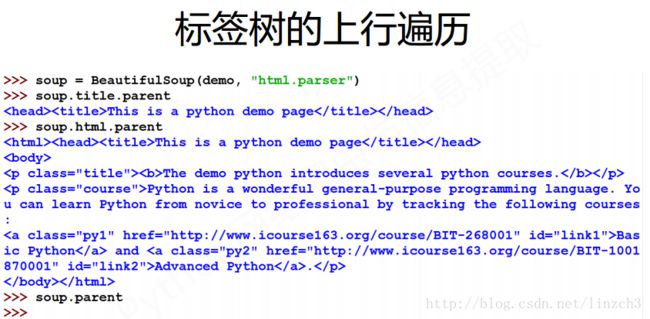
注意:上面的代码中,输出soup.parent的值是没有任何输出,这说明soup没有父亲节点。即BeautifulSoup类型是标签树的根节点,其没有父亲节点。
用法总结

注:BeautifulSoup类型是标签树的根节点。所以这里要区别判断。
标签树的平行遍历
**注意点:平行遍历发生在同一个父节点下的各节点间。
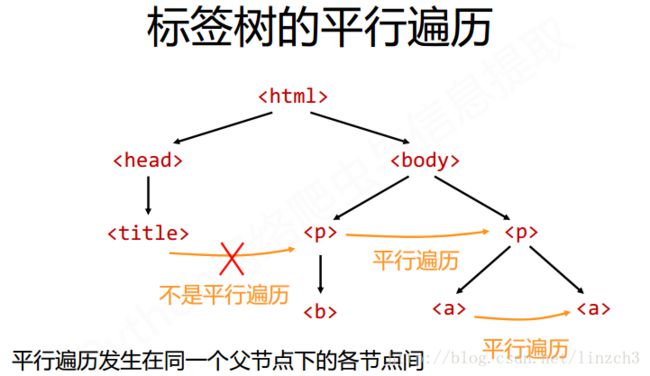
属性说明
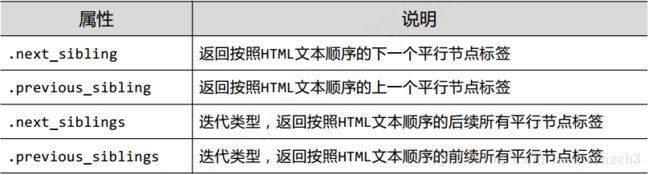
实例输出

注:注意上面第二行代码的输出,a标签的平行节点是一个字符串’and’。对应的解释为:在标签树中,尽管树形结构采用的是标签的形式来组织,但是标签之间的NavigableString也构成了节点,因此任何一个节点的父亲、孩子、平行节点都可能是NavigableString类型的。
这也提示了我们在编写代码的时候需要判断节点的平行节点是否是标签节点(以免将NavigableString类型节点误判为标签节点)。
用法总结

三种遍历的总结示意图

基于bs4库的HTML格式输出
在实际编写爬虫程序的时候,我们会遇到一个问题:如何让HTML的内容更加“ 友好”地输出?
这里的“友好”包含两方面的意思:
1.让我们(编写代码的人)更加方便地阅读HTML的内容
2.让程序更加方便地处理HTML的内容
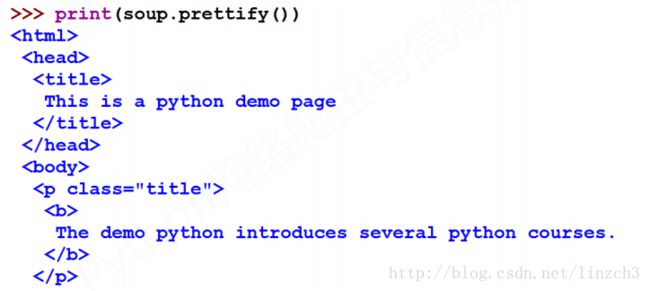
通常,我们使用bs4库的prettify()方法来解决这个问题。
bs4库的prettify()方法
仍旧以demo为例:
若直接输出demo,则其显示效果不怎么适合我们阅读,如下:

若使用bs4库的prettify()方法,则其显示效果很不错,如下:
同时,.prettify()也可用于标签,方法:

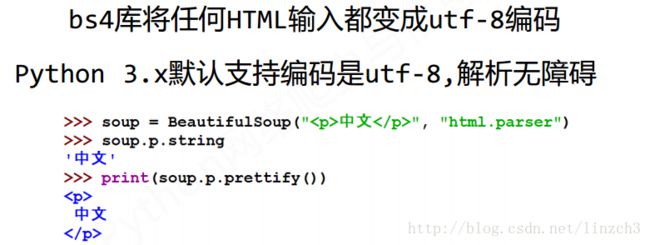
关于bs4库的编码
单元小结

信息组织与提取方法
信息标记的三种形式
信息标记的三种形式分别为:HTML、JSON、YAML。世界上所有类型的信息都可以通过这3种信息进行组织和标记,使得信息发挥更大的作用。
那么什么是信息标记呢?以下图为例,如果给你一个信息(见下图左侧),比如“北京理工大学”,那么你可以简单明了地理解它。但若是给你一组信息(见下图中侧),哪怕这一组信息都是与某个概念相关,我们可能都要仔细想一想。所以我们需要对信息进行一定的标记,使得我们能够理解信息的真实含义。比如,给“北京理工大学”标记为’name’,代表名字;给“北京市海淀区中关村”标记为‘addr’,代表地址(见下图右侧)。

信息标记后的好处:

HTML的信息标记(举例说明信息标记)


XML
XML可理解为是HTML的拓展。其简要介绍如下:


当标签内有内容时,我们用一对标签来表达信息:
当标签内没有内容时,我们可以使用一对尖括号来表达信息:
注释的形式:
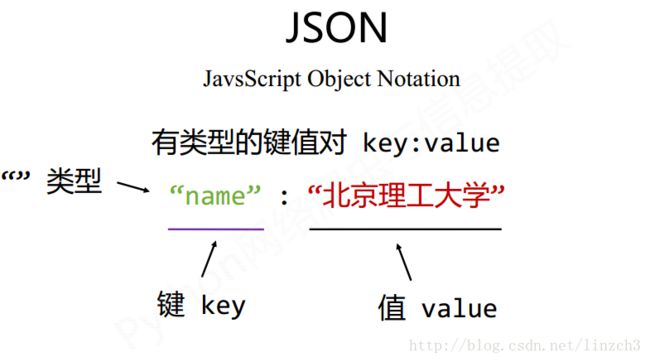
JSON
简要介绍:
一个key对应多个值时:

嵌套使用方法:

上述内容的简要总结:

对于Javascript这种语言,JSON格式的代码可直接作为程序的一部分,为编写程序带来了简化。
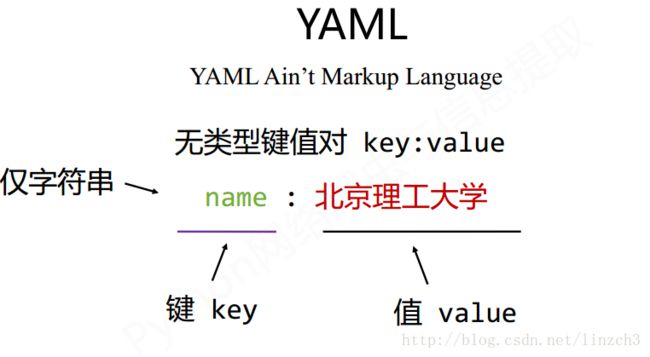
YAML
YAML也使用键值对来储存信息,但是相比JSON,其使用的是无类型的键值对来组织信息。
使用缩进表达所属关系:

使用“-”表达并列关系:

使用“| ”表达整块数据 、“#” 表示注释:

上述内容的简要总结:

三种信息标记形式的比较
下面先给出3个实例,然后再给出这三者的比较。
XML实例

JSON 实例

YAML 实例

| 信息标记形式 | 语法 | 比较 | 应用场景 |
|---|---|---|---|
| XML | 使用尖括号、标签标记信息 | 最早的通用信息标记语言,可扩展性好,但繁琐 | Internet上的信息交互与传递 |
| JSON | 使用有类型的键值对标记信息 | 信息有类型,适合程序处理(js),较XML简洁 | 移动应用云端和节点的信息通信,无注释 |
| YAML | 使用无类型的键值对标记信息 | 信息无类型,文本信息比例最高,可读性好 | 各类系统的配置文件,有注释易读 |
注意:JSON格式的文件中不能添加注释。
信息提取的一般方法
信息提取的一般方法:


注:第二种方式就相当于在word文档上搜索某些信息一样,我们根本不关心文章的标题是怎样的。
在实际使用中我们大多是使用以上这两种方法的融合。

实例

注:a标签就是带有链接的标签。
基于bs4库的HTML内容查找方法
这里仍旧以demo为例:

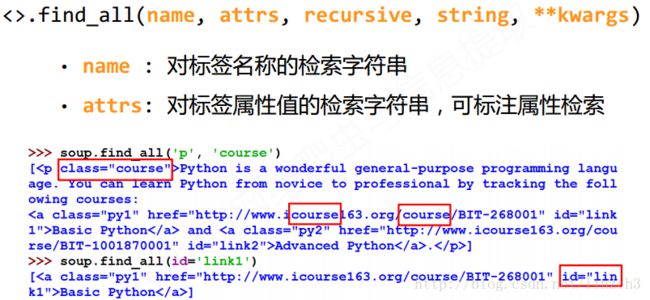
这里主要介绍的是bs4库中的find_all函数,具体如下:


注:
1.find_all函数的输入参数为True时,函数会返回所有的tag
2.re模块是正则表达式模块,re.compile()将正则表达式的字符串形式编译为Pattern实例。find_all(re.compile(‘b’))会返回所有以b开头的标签。


注:第二行代码的输出是一个空列表,这表明从根节点开始,没有找到标签为a的孩子节点。

注:
(..) 等价于 .find_all(..)
soup(..) 等价于 soup.find_all(..) 拓展方法

单元小结

实例1-中国大学排名爬虫
实例介绍
爬取的数据来自:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html

功能描述

爬虫程序终的显示效果应为:

定向爬虫可行性
在编写爬虫程序之前,需要了解网页的源代码的特点。查看源代码之后,发现我们需要的大学排名信息都已经“嵌入”到源代码之中了。

下一步,查找robots协议:
在浏览器上输入http://www.zuihaodaxue.cn/robots.txt,页面返回的是“404 Not Found”信息,因此没有robots协议文件,我们可以任意地爬取页面信息。
程序的结构设计

注:由于爬取的排名数据是二维的,因此我们可用列表来实现。
实例编写
代码主要框架:

注:这种编程方式很值得借鉴,在编写一个程序的时候,先将程序的功能模块化,先定义模块,然后编写main函数的调用代码,从而在完成代码主要框架之后再进行模块代码的详细编写。这样有助于我们理清思路和加快编码速度。
全部代码:
#CrawUnivRankingA.py
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
#查看网页源代码后发现 排名信息 在tbody标签 中的 tr标签
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):#过滤掉非标签类型
tds = tr('td') #取出tr标签的td标签,由于这一行代码的存在,因此需要import bs4
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))#format为格式化输出
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
实例优化
上面的代码运行结果为:
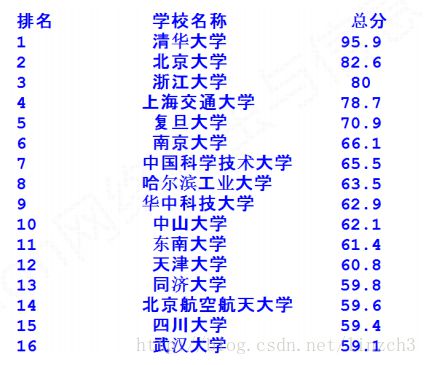
观察发现,中间的大学名字的输出没有居中对齐(代码中的^符号就是居中对齐的意思),而根据上面的这段代码:
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))理应是居中对齐输出的,那么问题在哪里呢?而观察旁边排名和总分信息,发现这两者的输出是居中对齐输出的。
中文对齐问题的原因
下面是format的一些常用使用语法:


原因便是:当中文字符宽度不够时,采用西文字符填充;而中西文字符占用宽度不同。
其解决方法就是:采用中文字符的空格填充 chr(12288)
因此将原来的printUnivList函数修改为:
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))#chr(12288)为中文字符的空格
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))修正后的输出:

单元小结
