SnappyData--一个统一OLTP+OLAP+流式写入的内存分布式数据库
一、背景:
阔别个人博客有大半年了,这大半年来我从一个all in flink的角色转变到了一个兼顾实时流式处理与实时OLAP处理的角色。
最近由于工作需要,在关注实时的OLTP+OLAP的HTAP场景的数据处理,优先保证低延迟的OLAP查询。说到这里,很容易让人想到Google的F1、Spanner,开源领域的代表TiDB。TiDB是个分布式的MySQL,对OLTP的支持很好,其有一个子项目叫做TiSpark,依赖Spark与TiKV做些OLAP的请求,但是这些复杂SQL执行的优先级(DistSQL API)是低于OLTP请求的,且当数据量大时(上亿条+多表join),这些SQL执行的时间不是很理想。
由于我们的需求是同时对流数据以及历史数据做OLAP查询,要求是快速的返回结果。Apache Flink等纯流式处理框架处理的是实时的数据,如果融入历史数据,那么实现起来也不是很方便。最主要的是如果OLAP查询的维度非常多,且不固定时,例如可以选择商圈、城市、省份、用户、时间等维度做聚合,那么flink去处理的话, 会发现key的选择很多,实现起来既麻烦也费时。如果选择druid或者kylin建立cube,那么由于我们的数据还会有些OLTP的操作,同时实时性也较差,因此也不太适合。
因此我们注意到一个完全基于内存的分布式数据库(同步或异步写到磁盘):SnappyData,其是一个行、列混和的内存分布式数据库,内部由GemFire(12306的商业版)+Spark SQL(支持列存可压缩)实现,既支持OLTP,也支持复杂的OLAP请求,且效率很高。
上边说了来龙去脉,下面开始针对SnappyData发表的论文,对其进行简单的介绍。
二、SnappyData介绍
在互联网时代,许多场景同时要求事务型操作、分析型操作以及流处理。企业为了应对这些需求,通常搭建各自用途的平台来分别处理OLTP类的关系型数据库,以及OLAP的数据仓库和Streaming流处理框架。在实现OLAP的过程中,已经有很多SQL On Hadoop的技术方案来实现OLAP的查询了,例如Hive、Impala、Kudu、Spark SQL等。这些系统的一大特点就是数据不可变,例如Spark RDD以及Hive中的数据,虽然各自在批处理的优化上做了很多的努力,但是还是缺乏对事务的ACID的支持。
流处理框架倒是可以支持流数据的处理,但是如果要关联大量的历史数据进行处理,显然效率也是较低的,且支持复杂的查询也比较困难。
那么为了支持这种混合负载的业务,通常公司都会进行大量的工作,既费时也费力,且效率较低。这些异构的系统虽然可以实现不同的需求,但是却有以下一些缺点:
1、复杂度和总成本增加:需要引入Hive、Spark、Flink、KV,Kylin、Druid等,且要求开发人员具备这些能力并进行运维。2、性能低下:一份数据要在不同的系统中存储和转换,例如RDBMS中一套、Hive中一套、Druid中一套,数据还得经过Spark、Flink转换处理。3、浪费资源:依赖的系统越多,使用的资源也就越多,这个是显而易见的。4、一致性的挑战:分布式系统事务的一致性实现困难,且当流处理失败时,虽然检查点可恢复但是有可能重复写入外部存储中(sink的exatcly-once没法保证)。我们的方法是将ApacheSpark作为计算引擎与Apache GemFire无缝集成,作为内存事务存储。 通过利用这两个开源框架的互补功能,SnappyData同时实现了这3种需求。同时,SnapppyData的商业版还通过概率的预算提供对超大历史数据查询时近似精确的结果。
下面我们看看SnappyData的具体实现。
三、方法与挑战
为了支持混合型的工作,SnappyData设计成了Spark+GemFire的组合。
Spark的RDD很高效,但是其毕竟只是个计算引擎,而并不是存储引擎;同时其要求数据是不可变的。
GemFire(也叫Geode),是一个面向行的分布式存储,可以实现分布式事务的一致性,同时支持点的更新以及批量更新,数据保存在内存中,也可以根据append-log持续的写入到磁盘中。
SnappyData则对两者进行了完美的结合,用Spark作为编程模型,数据的可变性和HA的需求则是使用GemFire的复制技术和细粒度的更新技术实现。
当然在两者融合上也有些挑战,最典型的需求就是扩展Spark,要其利用GemFire的锁服务以及可变性的操作,对数据进行点查询,点更新以及复杂结构上的insert操作。最后就是SnappyData要完全兼容Spark。
四、SnappyData架构
说到这,相信大家对SnappyData能干什么有个大体的了解,采用与Spark RDD一样的列存,同时根据GemFire支持行存,以及两者互补,在行、列存储上进行点查、点更新以及批量写入和更新。那么其架构到底是什么样呢?
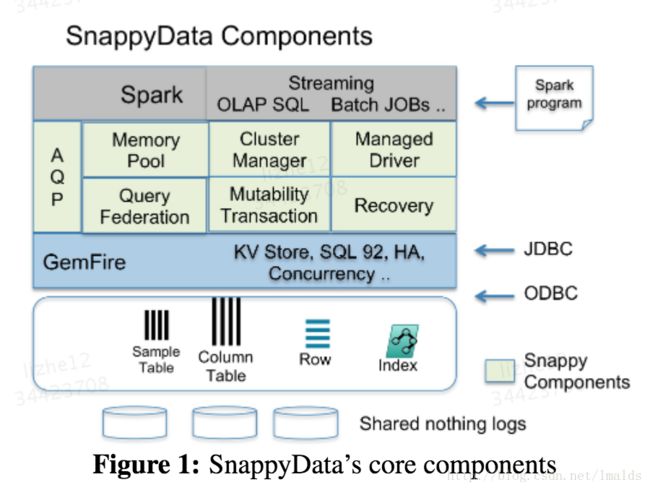
从图中可以看到,SnappyData的存储主要在内存中,同时支持行存与列存,以及预测型的存储。列存是来源于Spark的RDD,行存则扩展了GemFire的表且支持行存上建索引。而且SnappyData还有个AQP的概念,即以近似准确的结果来快速的响应对超大历史数据的查询,不过这个功能只能用于商业版上。
SnappyData支持2种编程模型:SQL和Spark API。因此SnappyData是一个SQL数据库,其可以使用Spark SQL进行开发。SnappyData的副本一致性和点更新则依赖GemFire的P2P对等网络,事务支持则是依赖GemFire中通过Paxos实现的2阶段提交实现。
五、混合存储模型
SnappyData中的表是可以分片的,也可以在每个节点的内存中复制。
行表会占用较大的内存空间,但是适合较小的表,且可以创建索引。列表也可以被更新,且做了压缩,减少了对内存的压力。那么SnappyData是如何对列存进行更新的呢?其使用了一个delta row buffer的区域,当记录被写入列表时,首先会进入delta row buffer中,它是一个在内存中与更新的列表有相同分区策略的行存,这个行存由混合队列支持,可以周期性的写入到列存中并清空自己,当连续的对同一记录进行更新操作时,只会把最终的状态写入列存中,即合并的含义,而不是一次一次的写入。同时,delta row buffer使用了copy-on-write的语义来保证并发更新时的数据一致性。
SnappyData中将GemFire的表进行分区或复制到不同的节点上,根据分区数据被放到不同的buckets中,因此访问数据是并行进行的。这个与Spark读取外部parquet或Json数据很像,但是SnappyData内部做了优化,例如每个分区本身就是列式存储,避免了数据的复制和序列化开销,同时允许表与表之间的存储本地化,即colocate相关联的数据,例如一个事实表可以根据分区键colocate其父表配置或者维度信息表,这样在做join时可以避免shuffle和跨节点的数据传输,效率非常高。

这里的colocate的作用,是为了在分布式join时,避免分布式锁、shuffle的网络开销。通过colocate操作,将分布式的join变成了本地join,并剪枝了不必要的分区。个人觉得这个技术或者思路,也许会应用到未来很多的分布式join的场景中。除了colocate外,还有一种方法是将一个表的数据进行replicated操作,即复制到每个server的内存中一份,也可以避免分布式join,但是其要求是个很小的表,否则内存压力太大了。
六、混合集群管理
SnappyData作为一个存储和计算引擎,必须要靠高并发、高可用以及数据的一致性。
为了快速的检测失败,SnappyData依赖于UDP的neighbor ping和TCP的ack超时机制,而一致性则依赖GemFire内部的机制。这里的具体实现忽略。
七、总结
SnappyData的性能有很多benchmark,例如早期的测试如下:
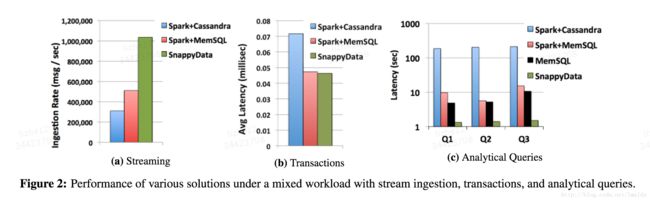
总结起来,SnappyData = stream写入+ OLTP + OLAP。由于其结合了GemFire与Spark,使得其可以在列存上进行更新;同时由于其数据既存在于内存又可刷到磁盘,因此全内存的计算使得其速度很快;最后其colocate的设置使得多表join的性能很高。综上所属,如果你的业务对OLAP类型的延时要求很低,同时要能够查询实时的数据,那么SnappyData是个非常不错的选择。
我们在SnappyData中具体的使用以及效果,我会在后续的文章中进行介绍。
相关资料:
SnappyData官网
SnappyData官方文档
SnappyData官方博客
SnappyData社区
SnappyData Twitter
SnappyData Youtube