大数据 - Spark Streaming介绍和实战
Spark Streaming
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
计算流程:
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备。
容错性
对于流式计算来说,容错性至关重要。首先我们要明确一下Spark中RDD的容错机制。每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
实时性
对于实时性的讨论,会牵涉到流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
扩展性与吞吐量
Spark目前在EC2上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6GB/s的数据量(60M records/s),其吞吐量也比流行的Storm高2~5倍,图4是Berkeley利用WordCount和Grep两个用例所做的测试,在Grep这个测试中,Spark Streaming中的每个节点的吞吐量是670k records/s,而Storm是115k records/s。
Storm与SparkStreaming如何选择
目前流式处理框架主要有Strom和SparkStreaming,那么在实际应用中我们该如何选择适合自己的框架呢?来看一下它们的主要区别:
Strom是一个纯实时的流式处理框架,即来一条数据就处理一条数据,这样势必集群内有频繁的网络通讯,吞吐量低。
SparkStreaming是微批处理框架,吞吐量高。
Strom的事务处理机制要比SparkStreaming的好,SparkStreaming中存在丢数据或者重复计算的问题,Storm中接受或拉取的每条数据可以准确的只处理一次。
Strom适合做简单的汇总型计算,SparkStreaming可以做复杂的计算,因为SparkStreaming是基于Dstream来开发的,Dstream可以抽出RDD(即Spark的核心),支持更多的复杂计算。
Strom支持动态资源的调整,而SparkStreaming是粗粒度的资源调度(新版本中即使有也是通过kill excutor的形式)。
基于以上的区别,我们的选择就变得简单多了,如金融类的肯定选择Strom,对精确度要求的高,如实时预测类的肯定是SparkStreaming,还可以根据公司的实际资源选择,如果现有Spark集群,那么肯定选择SparkStreaming更合适,我公司的日志处理是基于SparkStreaming开发的。
简单实战
模拟实时计算订单销售数据,生产者每秒产生订单数据发送到消息队列kafka,消费者接收kafka中的订单数据,实时计算订单销售数据后存储到redis中。
需要启动kafka和redis,kafka安装方式参考 https://blog.csdn.net/lyhkmm/article/details/79525238 ,redis略。
IDEA开发环境创建Spark项目,参考https://blog.csdn.net/lyhkmm/article/details/88025952
pom.xml引入需要的包
org.apache.spark
spark-core_2.11
2.4.0
org.apache.spark
spark-streaming_2.11
2.4.0
org.apache.spark
spark-streaming-kafka-0-8_2.11
2.4.0
com.alibaba
fastjson
1.2.8
redis.clients
jedis
2.9.0
项目结构
新建src/main/resources并创建log4j.properties,设置日志级别为wran
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
log4j.logger.org.spark-project.jetty=WARN
log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
订单生产者OrderProducer
import java.util.Properties
import com.alibaba.fastjson.JSONObject
import kafka.producer.{KeyedMessage, Producer, ProducerConfig}
import scala.util.Random
object OrderProducer {
def main(args: Array[String]): Unit = {
//Kafka参数设置
val topic = "order"
val brokers = "127.0.0.1:9092"
val props = new Properties()
props.put("metadata.broker.list", brokers)
props.put("serializer.class", "kafka.serializer.StringEncoder")
val kafkaConfig = new ProducerConfig(props)
//创建生产者
val producer = new Producer[String, String](kafkaConfig)
while (true) {
//随机生成10以内ID
val id = Random.nextInt(10)
//创建订单事件
val event = new JSONObject();
event.put("id", id)
event.put("price", Random.nextInt(10000))
//发送信息
producer.send(new KeyedMessage[String, String](topic, event.toString))
println("Message sent: " + event)
//随机暂停一段时间
Thread.sleep(Random.nextInt(100))
}
}
}
消费者OrderConsumer
import com.alibaba.fastjson.JSON
import com.lyhkmm.spark.utils.RedisClient
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka.KafkaUtils
object OrderConsumer {
//Redis配置
val dbIndex = 0
//每件商品总销售额
val orderTotalKey = "app::order::total"
//每件商品每分钟销售额
val oneMinTotalKey = "app::order::product"
//总销售额
val totalKey = "app::order::all"
def main(args: Array[String]): Unit = {
// 创建 StreamingContext 时间片为1秒
val conf = new SparkConf().setMaster("local").setAppName("UserClickCountStat")
val ssc = new StreamingContext(conf, Seconds(1))
// Kafka 配置
val topics = Set("order")
val brokers = "127.0.0.1:9092"
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers,
"serializer.class" -> "kafka.serializer.StringEncoder")
// 创建一个 direct stream
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
//解析JSON
val events = kafkaStream.flatMap(line => Some(JSON.parseObject(line._2)))
// 按ID分组统计个数与价格总合
val orders = events.map(x => (x.getString("id"), x.getLong("price"))).groupByKey().map(x => (x._1, x._2.size, x._2.reduceLeft(_ + _)))
//输出
orders.foreachRDD(x =>
x.foreachPartition(partition =>
partition.foreach(x => {
println("id=" + x._1 + " count=" + x._2 + " price=" + x._3)
//保存到Redis中
val jedis = RedisClient.pool.getResource
jedis.select(dbIndex)
//每个商品销售额累加
jedis.hincrBy(orderTotalKey, x._1, x._3)
//上一分钟第每个商品销售额
jedis.hset(oneMinTotalKey, x._1.toString, x._3.toString)
//总销售额累加
jedis.incrBy(totalKey, x._3)
RedisClient.pool.returnResource(jedis)
})
))
ssc.start()
ssc.awaitTermination()
}
}
RedisClient
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import redis.clients.jedis.JedisPool
object RedisClient extends Serializable {
val redisHost = "127.0.0.1"
val redisPort = 6379
val redisTimeout = 30000
lazy val pool = new JedisPool(new GenericObjectPoolConfig(), redisHost, redisPort, redisTimeout)
lazy val hook = new Thread {
override def run = {
println("Execute hook thread: " + this)
pool.destroy()
}
}
sys.addShutdownHook(hook.run)
def main(args: Array[String]): Unit = {
val dbIndex = 0
val jedis = RedisClient.pool.getResource
jedis.select(dbIndex)
jedis.set("test", "1")
println(jedis.get("test"))
RedisClient.pool.returnResource(jedis)
}
}
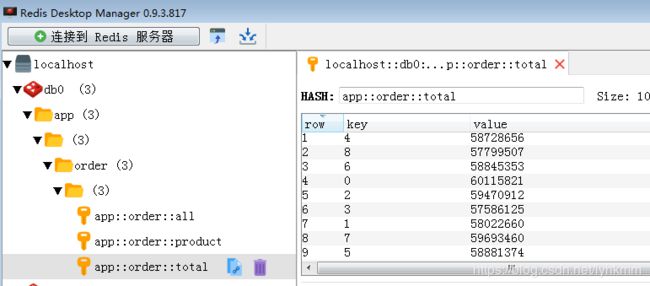
分别运行OrderProducer、OrderConsumer后通过redis客户端查看订单销售数据
Github地址:https://github.com/lyhkmm/spark-demo