Tensorflow实战:ResNet原理及实现(多注释)
参考《Tensorflow实战》黄文坚,对Inception_V3进行了实现与改进,增加了自己的理解,欢迎提问!!
残差神经单元:假定某段神经网络的输入是x,期望输出是H(x),如果我们直接将输入x传到输出作为初始结果,那么我们需要学习的目标就是F(x) = H(x) - x,这就是一个残差神经单元,相当于将学习目标改变了,不再是学习一个完整的输出H(x),只是输出和输入的差别 H(x) - x ,即残差。
如下图分别为两层及三层的ResNet残差学习模块:
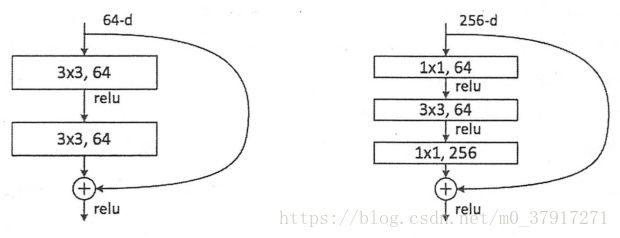
本文使用三层的ResNet残差学习模块:
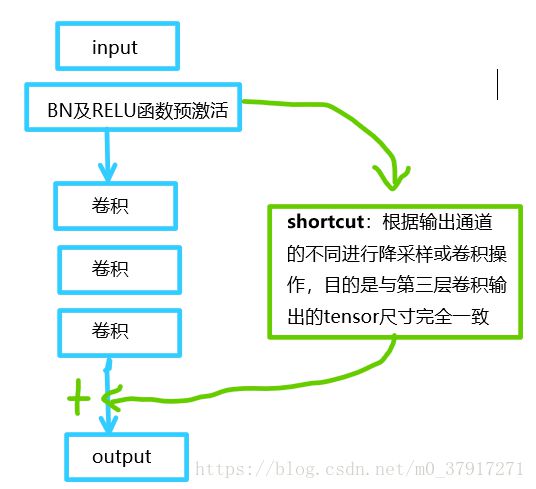
可以看到普通的直连的卷积神经网络和ResNet的最大区别在于,ResNet有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这种结构也被称为shortcut或skip connections。
传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络只需要学习输入、输出差别的那一部分,简化了学习目标和难度。
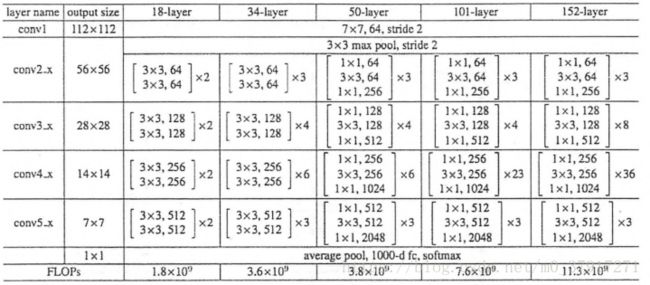
下图为ResNet不同层数时的网络配置,[ ]表示一个残差学习模块。本文使用152-layer的配置,构建ResNet_V2结构。
本文ResNet_V2结构如下图所示
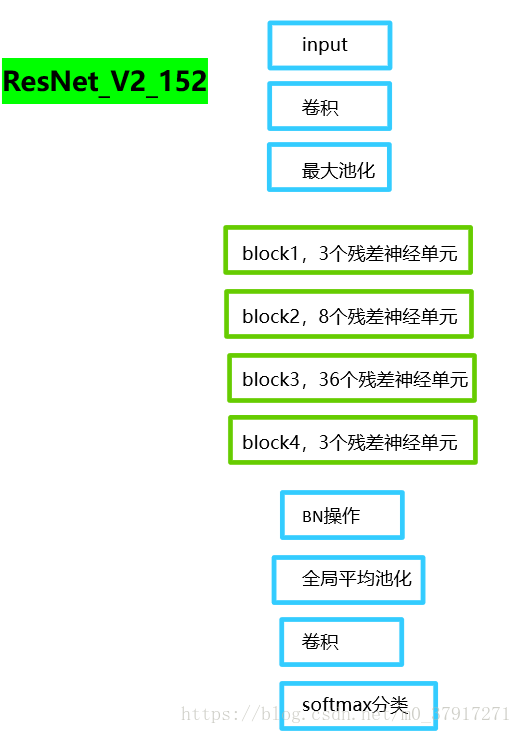
为方便理解,贴出方法调用关系,如下图,红色显示在该位置调用其他方法,绿色表示在该处返回参数。

本文使用ResNet_V2_152的结构及参数,进行了前向计算的测评,代码及详细注释如下:
import tensorflow as tf
import collections
import time
from datetime import datetime
import math
'''############################################04《TensorFlow实战》实现ResNet_V2##################################################'''
slim = tf.contrib.slim
'''使用collections.namedtuple设计ResNet基本Block模块组的named tuple,并用它创建Block类'''
class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])):
'a named tuple decribing a ResNet block.'
'''一个典型的Block
需要输入参数,分别是scope、unit_fn、args
以Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)])为例,它可以定义一个典型的Block
其中
1、block1就是这个Block的名称(或scope)
2、bottleneck是ResNet V2中的残差学习单元
3、[(256, 64, 1)] * 2 + [(256, 64, 2)]时这个Block的args,args是一个列表,其中每一个元素都对应一个bottleneck残差学习单元,
前面两个都是(256, 64, 1),最后一个是(256, 64, 2)。每个元素都是一个三元tuple,即(depth, depth_bottleneck, stride)
比如(256, 64, 3),代表构建的bottleneck残差学习单元(每个残差学习单元包含三个卷积层)中,第三层卷积输出通道数为256,
前两层卷积输出通道数depth_bottleneck为64,且中间那层的步长stride为3
'''
'''降采样的方法'''
def subsample(inputs, factor, scope=None):
#如果采样因子为1,之间返回输出
if factor == 1:
return inputs
#否则,最大池化处理,步长为采样因子
else:
return slim.max_pool2d(inputs, [1, 1], stride=factor, scope=scope)
'''创建卷积层'''
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope=None):
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, stride=1, padding='SAME', scope=scope)
else:
#步长不为1,则显示地pad zero
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
#补零操作,在第二和第三个维度上进行补零操作
inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, stride=stride, padding='VALID', scope=scope)
'''堆叠Blocks的函数,net为输入,bloks为Block类的列表,outputs_collections时用来收集各个end_points'''
@slim.add_arg_scope
def stack_blocks_dense(net, blocks, outputs_collections=None):
#遍历每一个Block
for block in blocks:
#使用两个tf.variable_scope将残差学习单元命名为block1/unit_1的形式
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
unit_depth, unit_depth_bottleneck, unit_stride = unit
#使用unit_fn函数(即残差学习单元生成函数)顺序创建并连接所有的残差学习单元
net = block.unit_fn(net, #block.unit_fn即调用了bottleneck()函数
depth=unit_depth, #第三层卷积输出通道数
depth_bottleneck=unit_depth_bottleneck, #前两层卷积输出通道数depth_bottleneck
stride=unit_stride) #中间那层卷积的步长 #其余参数是固定不变的
# net = bottleneck(net,
# depth=unit_depth,
# depth_bottleneck=unit_depth_bottleneck,
# stride=unit_stride)
#将输出net添加到collection中
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
#返回最后的net作为函数结果
return net
'''创建ResNet通用的arg_scope, arg_scope的功能是定义某些函数的参数默认值'''
def resnet_arg_scope(is_training=True, #训练标记
weight_decay=0.0001, #权重衰减速率
batch_norm_decay=0.997, #BN的衰减速率
batch_norm_epsilon=1e-5, #BN的epsilon
batch_norm_scale=True): #BN的scale
batch_norm_parmas = {
'is_training':is_training,
'decay':batch_norm_decay,
'epsilon':batch_norm_epsilon,
'scale':batch_norm_scale,
'updates_collections':tf.GraphKeys.UPDATE_OPS
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer = slim.l2_regularizer(weight_decay), #权重正则设为L2正则
weights_initializer = slim.variance_scaling_initializer(), #权重初始化器
activation_fn = tf.nn.relu, #激活函数
normalizer_fn = slim.batch_norm, #标准化器设为BN(batch_norm的缩写)
normalizer_params = batch_norm_parmas):
with slim.arg_scope([slim.batch_norm], **batch_norm_parmas): #设置BN的默认参数
with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc: #最大池化的padding默认设为SAME
return arg_sc
'''bottleneck残差学习单元'''
'''
知识点:
并不是所有的方法都能用arg_scope设置默认参数, 只有用@slim.add_arg_scope修饰过的方法才能使用arg_scope.
例如conv2d方法, 它就是被修饰过的(见源码).
所以, 要使slim.arg_scope正常运行起来, 需要两个步骤:
1、用@add_arg_scope修饰目标函数
2、用with arg_scope(...) 设置默认参数.
'''
@slim.add_arg_scope
def bottleneck(inputs, #输入
depth, depth_bottleneck, stride, #这三个参数是Blocks类中的args
outputs_collections=None, #收集end_points
scope=None): #名称
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
#获取输入的最后一个维度,即输出通道数。 min_rank=4限定最少为4个维度
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
#对输入进行BN(Batch Normalization)操作,并使用ReLU函数进行预激活Preactivate
preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact')
'''定义shortcut,即旁路的弯曲的支线'''
#如果残差单元的输入通道depth_in与第三层卷积的输出通道depth一致
if depth == depth_in:
#使用subsample按步长为stride对inputs进行空间降采样(因为输出通道一致了,还要确保空间尺寸和残差一致,因为残差中间那层的卷积步长为stride,tensor尺寸可能会缩小)
shortcut = subsample(inputs, stride, 'shortcut')
else:#输出通道不一致
#使用1×1的卷积核改变其通道数,并使用与步长为stride确保空间尺寸与残差一致
shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride, normalizer_fn=None,
activation_fn=None, scope='shortcut')
'''残差residual,三层卷积'''
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1, scope='conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride, scope='conv2') #步长为stride,并进行补零操作
residual = slim.conv2d(residual, depth, [1, 1], stride=1, normalizer_fn=None, #最后一层卷积没有正则项也没有激活函数
activation_fn=None, scope='conv3')
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections, sc.name, output) #将结果添加进collection并返回
'''生成ResNet的主函数,
只要预先定义好网络的残差学习模块组blocks,它就可以生成对应的完整的ResNet'''
def resnet_v2(inputs, #输入
blocks, #定义好的Block类列表
num_classes=None, #最后输出的类数
global_pool=True, #是否加上最后一层全局平均池化
include_root_block=True, #是否加上ResNet网络最前面通常使用的7*7卷积和最大池化
reuse=None, #是否重用
scope=None): #整个网络的名称
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse=reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
#将slim.conv2d, bottleneck, stack_blocks_dense这三个函数的参数outputs_collections默认设为end_points_collection
with slim.arg_scope([slim.conv2d, bottleneck, stack_blocks_dense], outputs_collections=end_points_collection):
net = inputs
#根据该标记,创建ResNet最前面的64输出通道的步长为2的7*7卷积
if include_root_block:
with slim.arg_scope([slim.conv2d], activation_fn=None, normalizer_fn=None):
net = conv2d_same(net, 64, 7, stride=2, scope='conv1')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
#使用前面定义好的函数stack_blocks_dense将残差学习模块组生成好,得到其输出
net = stack_blocks_dense(net, blocks)
net = slim.batch_norm(net, activation_fn=tf.nn.relu, scope='postnorm')
#根据标记添加全局平均池化层
if global_pool:
net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
#根据是否有分类数,添加一个1*1卷积
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, normalizer_fn=None, scope='logits')
#通过该方法将collection转化为python的dict词典
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
#根据是否有分类数,添加Softmax层输出网络结果
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope='predictions')
return net, end_points
'''设计层数为152层的ResNet
Resnet不断使用步长为2的层来缩减尺寸,同时输出通道数也在持续增加
'''
def resnet_v2_152(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_152'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
'''评估ResNet_V2每轮计算所用时间'''
def time_tensorflow_run(session, target, info_string):#target:需要评测的运算算字, info_string:测试的名称
num_steps_burn_in = 10 #给程序热身,头几轮迭代有显存的加载、cache命中等问题因此可以跳过,我们只考量10轮迭代之后的计算时间
total_duration = 0.0 #总时间
total_duration_squared = 0.0 #平方和
#循环计算每一轮耗时
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i>= num_steps_burn_in:#程序热身完成后,记录时间
if not i % 10: #每10轮 显示 当前时间,迭代次数(不包括热身),用时
print('%s: step %d, duration = %.3f' % (datetime.now(), i - num_steps_burn_in, duration))
#累加total_duration和total_duration_squared
total_duration += duration
total_duration_squared += duration * duration
#循环结束后,计算每轮迭代的平均耗时mn和标准差sd,最后将结果显示出来
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' % (datetime.now(), info_string, num_batches, mn, sd))
batch_size = 16
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(resnet_arg_scope(is_training=False)):
net, end_points = resnet_v2_152(inputs, 1000)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, net, "Forward")
结果如下:
2018-09-03 13:55:39.135312: step 0, duration = 0.203
2018-09-03 13:55:41.297068: step 10, duration = 0.203
2018-09-03 13:55:43.446128: step 20, duration = 0.210
2018-09-03 13:55:45.615464: step 30, duration = 0.223
2018-09-03 13:55:47.760008: step 40, duration = 0.210
2018-09-03 13:55:49.929766: step 50, duration = 0.212
2018-09-03 13:55:52.088576: step 60, duration = 0.211
2018-09-03 13:55:54.236349: step 70, duration = 0.210
2018-09-03 13:55:56.383887: step 80, duration = 0.203
2018-09-03 13:55:58.539430: step 90, duration = 0.204
2018-09-03 13:56:00.486147: Forward across 100 steps, 0.216 +/- 0.007 sec / batch