BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 论文笔记
Introduction
BERT在11项NLP任务中取得如此令人振奋的成绩主要来源与以下的三个方面:
(1)BERT使用“遮蔽”语言模型去 pre-trained 深度语言表示。
(2)许多pre-trained 模型受限于特种结构、特种模型。BERT使用fine-tuning(微调)模型在众多句子级别或者是单词级别的任务中去得了最先进的效果。
(3)BERT使用双向语言模型在11项NLP任务中都去得了最先进的效果。
Related Work
众多的实验证明了基于预训练的语言模型效果是真实有效的。预训练的语言模型主要有两种:
(1)基于特征方法的
对于众多的词嵌入技术,他们使用的都是基于特征方法的。其中包括我们熟知的 Word2Vec(https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf),Glove(https://www.aclweb.org/anthology/D14-1162),和基于上下文特征的ELMO语言模型(http://aclweb.org/anthology/N18-1202)。
(2)基于微调方法的
近年来对于基于迁移学习的语言模型吸引了越来越多的目光。它们最大的好处就是在下游任务中只需要重新学习少量的特殊化参数,使得pre-trained的优势能够以非常低的成本应用到更多的任务中去。其中Open AI GPT(https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)表现的十分出色。
BERT
Model Architecture
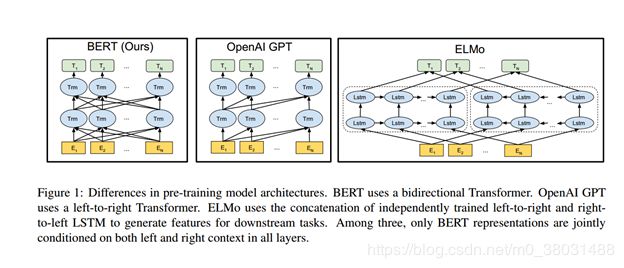
BERT的模型结果是基于 multi-layer bidirectional Transformer 编码器的,对于Transformer的详细了解学习我们可以参考这篇论文(https://openreview.net/pdf?id=rJvJXZb0W)。
论文中也列出了三种语言模型的详细结构:
BERT: bidirectional self-attention
Open AI GPT: self-attention (由于模型结构是left-to-right的,所以只利用到了单词左部的上下文信息。)
ELMO: 使用两个相互独立的 left-to-right and right-to-left LSTM 去融合生成特征供下游任务使用。
Input Representation
模型的输入表示能够在一个token序列中明确的区分出任务是单个文本句子或是一对文本句子(例如,{Question, Answer})。
对于输入表示由以下三个方面构成:
token embeddings : WordPiece embeddings
segmentation embeddings : 使用A和B来区分一对句子中的单句。
position embeddings : 最多支持521个token

Pre-training Tasks
不同与传统的语言模型,BERT使用两个非常重要的无监督任务来训练模型。
Task #1: Masked LM
为了训练一个深度双向,BERT表示采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token。但是其存在两个缺点:
- [MASK] token is never seen during fine-tuning。
Solve:
- 80% of the time: Replace the word with the [MASK] token, e.g., my dog is hairy --- my dog is [MASK]
- 10% of the time: Replace the word with a random word, e.g., my dog is hairy --- my dog is apple.
- 10% of the time: Keep the word unchanged, e.g., my dog is hairy --- my dog is hairy.
2.MLM suggests that more pre-training steps may be required for the model to converge. (解决方案:不解决,就是豪)
Task #2: Next Sentence Prediction
许多重要的下游任务,如问答(QA)和自然语言推理(NLI)都是基于理解两个句子之间的关系,这并没有通过语言建模直接获得。 在为了训练一个理解句子的模型关系,预先训练下一句测任务,这一任务可以从任何单语语料库中生成。具体地说,当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。

Experiments
sequence-level tasks
对于不同句子级别的任务我们可以使用(a)或者是(b)模型来进行解决。CLASS LABEL 可以标识我们的类别信息,如果没有的话它将不代表任何意义。

token-level tasks
对于token级别的任务(例如,命名实体识别),我们可以使用(c)或者是(d)模型来解决。对于(c)如果任务是问答,我们可以根据问题,在给定的答案范围中圈定出来答案来源句的起始位置。对于(d)如果任务是命名实体识别,我们可以为每个token生成一个标签来区分是否是实体。

Ablation Studies
对于横扫11个NLP任务的实验结果我们就不全列出了,如果有兴趣可以在文章底部的原文链接来详细观摩。我们只给出关于命名实体识别和问答两个任务的结果,其实就有超过人类表现的的结果。
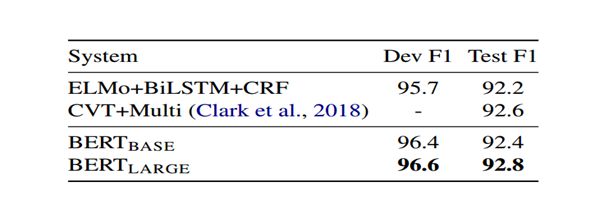

Effect of Pre-training Tasks(总结:两个BERT提出的任务很有效)
Effect of Model Size(总结:模型参数越多越有效)
Effect of Number of Training Steps(总结:因为模型收敛较慢,高迭代次数是十分必须的)
论文链接:https://arxiv.org/abs/1810.04805
github链接:https://github.com/google-research/bert