【Python机器学习及实践】进阶篇:模型实用技巧(特征提升)
Python机器学习及实践——进阶篇:模型实用技巧(特征提升)
所谓特征抽取,就是逐条将原始数据转化为特征向量的形式,这个过程同时涉及对数据特征的量化表示;而特征筛选则进一步,在高维度、已量化的特征向量中选择对指定任务更有效的特征组合,进一步提升模型性能。
1.特征抽取
原始数据的种类有很多种,除了数字化的信号数据(声纹、图像),还有大量符号化的文本。然而,我们无法直接将符号化的文本本身用于计算任务,而是需要通过某些处理手段,预先将文本量化为特征向量。
有些用符号表示的数据特征已经相对结构化,并且以字典这种数据结构进行存储。这时,使用DictVectorizer对特征进行抽取和向量化。
DictVectorizer对使用字典存储的数据进行特征抽取与向量化
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@File : FeatureExtraction.py
@Author: Xinzhe.Pang
@Date : 2019/7/23 20:59
@Desc :
"""
# 定义一组字典列表,用来表示多个数据样本(每个字典代表一个数据样本)
measurements = [{'city': 'Dubai', 'temperature': 33.}, {'city': 'London', 'temperature': 12.},
{'city': 'San Fransisco', 'temperature': 18.}]
# 从sklearn.feature_extraction中导入DictVectorizer
from sklearn.feature_extraction import DictVectorizer
# 初始化DictVectorizer特征抽取器
vec = DictVectorizer()
# 输出转化之后的特征矩阵
print(vec.fit_transform(measurements).toarray())
# 输出各个维度的特征含义
print(vec.get_feature_names())
在特征向量化的过程中,DictVectorizer对于类别型(Categorical)与数值型(Numerical)特征的处理方式有很大差异。由于类别型特征无法直接数字化表示,因此需要借助原特征的名称,组合产生新的特征,并采用0/1二值方式进行量化;而数值型特征的转化则相对方便,一般情况下只需要维持原始特征值即可。
另外一些文本数据则表现得更为原始,几乎没有使用特殊的数据结构进行存储,只是一系列字符串。我们处理这些数据,比较常用的文本特征表示方法为词袋法(Bag of Words):即不考虑词语出现的顺序,只是将训练文本中的每个出现过的词汇单独视作一列特征。称这些不重复的词汇集合为词表(Vocabulary),于是每条训练文本都可以在高维度的词表上映射出一个特征向量。特征数值的常见计算方式有两种:CountVectorizer和TfidfVectorizer。对于每一条训练文本,CountVectorizer只考虑每种词汇(Term)在该条训练文本中出现的概率(Term Frequency)。而TfidfVectorizer除了考虑某一词汇在当前文本中出现的频率(Term Frequency)之外,同时关注包含这个词汇的文本条数的倒数(Inverse Document Frequency)。相比之下,训练文本的条目越多,TfidfVectorizer这种特征量化方式就更有优势。因为我们计算词频(Term Frequency)的目的在于找出对所在文本的含义更有贡献的重要词汇。然而,如果一个词汇几乎在每篇文本种出现,说明这是一个常用词汇,反而不会帮助模型对文本的分类;在训练文本量较多的时候,利用TfidfVectorizer压制这些常用词汇的对分类决策的干扰,往往可以起到提升模型性能的作用。
通常称这些在每条文本中都出现的常用词汇为停用词(Stop Words)。这些停用词在文本特征抽取中经常以黑名单的方式过滤掉,并且用来提高模型的性能表现。
使用CountVectorizer并且不去掉停用词的条件下,对文本特征进行量化的朴素贝叶斯分类性能测试:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@File : CountVectorizer.py
@Author: Xinzhe.Pang
@Date : 2019/7/23 22:08
@Desc :
"""
# 从sklearn.datasets里导入20类新闻文本数据抓取器。
from sklearn.datasets import fetch_20newsgroups
# 从互联网上即时下载新闻样本,subset='all'参数代表下载全部近2万条文本存储在变量news中。
news = fetch_20newsgroups(subset='all')
# 从sklearn.cross_validation导入train_test_split模块用于分割数据集。
from sklearn.model_selection import train_test_split
# 对news中的数据data进行分割,25%的文本用作测试集;75%作为训练集。
X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33)
# 从sklearn.feature_extraction.text里导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# 采用默认的配置对CountVectorizer进行初始化(默认配置不去除英文停用词),并且赋值给变量count_vec。
count_vec = CountVectorizer()
# 只使用词频统计的方式将原始训练和测试文本转化为特征向量。
X_count_train = count_vec.fit_transform(X_train)
X_count_test = count_vec.transform(X_test)
# 从sklearn.naive_bayes里导入朴素贝叶斯分类器。
from sklearn.naive_bayes import MultinomialNB
# 使用默认的配置对分类器进行初始化。
mnb_count = MultinomialNB()
# 使用朴素贝叶斯分类器,对CountVectorizer(不去除停用词)后的训练样本进行参数学习。
mnb_count.fit(X_count_train, y_train)
# 输出模型准确性结果。
print('The accuracy of classifying 20newsgroups using Naive Bayes (CountVectorizer without filtering stopwords):',
mnb_count.score(X_count_test, y_test))
# 将分类预测的结果存储在变量y_count_predict中。
y_count_predict = mnb_count.predict(X_count_test)
# 从sklearn.metrics 导入 classification_report。
from sklearn.metrics import classification_report
# 输出更加详细的其他评价分类性能的指标。
print(classification_report(y_test, y_count_predict, target_names=news.target_names))
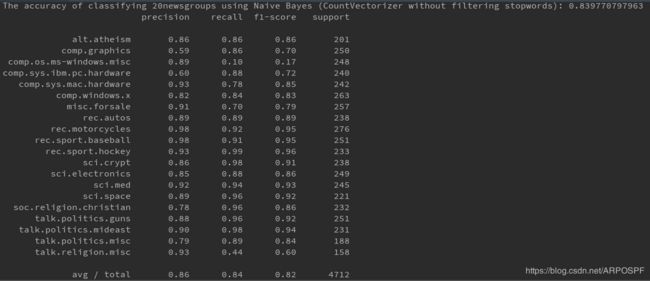
使用TfidfVectorizer并且在不去掉停用词的条件下,对文本特征进行量化的朴素贝叶斯分类性能测试
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@File : TfidfVectorizer.py
@Author: Xinzhe.Pang
@Date : 2019/7/23 22:26
@Desc :
"""
# 从sklearn.datasets里导入20类新闻文本数据抓取器。
from sklearn.datasets import fetch_20newsgroups
# 从互联网上即时下载新闻样本,subset='all'参数代表下载全部近2万条文本存储在变量news中。
news = fetch_20newsgroups(subset='all')
# 从sklearn.cross_validation导入train_test_split模块用于分割数据集。
from sklearn.model_selection import train_test_split
# 对news中的数据data进行分割,25%的文本用作测试集;75%作为训练集。
X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33)
# 从sklearn.feature_extraction.text里导入TfidfVectorizer。
from sklearn.feature_extraction.text import TfidfVectorizer
# 采用默认的配置对TfidfVectorizer进行初始化(默认配置不去除英文停用词),并且赋值给变量tfidf_vec。
tfidf_vec = TfidfVectorizer()
# 使用tfidf的方式,将原始训练和测试文本转化为特征向量。
X_tfidf_train = tfidf_vec.fit_transform(X_train)
X_tfidf_test = tfidf_vec.transform(X_test)
from sklearn.naive_bayes import MultinomialNB
# 从sklearn.metrics 导入 classification_report。
from sklearn.metrics import classification_report
# 依然使用默认配置的朴素贝叶斯分类器,在相同的训练和测试数据上,对新的特征量化方式进行性能评估。
mnb_tfidf = MultinomialNB()
mnb_tfidf.fit(X_tfidf_train, y_train)
print('The accuracy of classifying 20newsgroups with Naive Bayes (TfidfVectorizer without filtering stopwords):',
mnb_tfidf.score(X_tfidf_test, y_test))
y_tfidf_predict = mnb_tfidf.predict(X_tfidf_test)
print(classification_report(y_test, y_tfidf_predict, target_names=news.target_names))
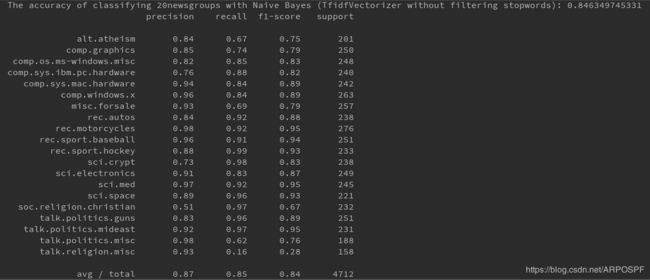
说明在训练文本量较多的情况下,使用TfidfVectorizer能够减少常用词汇对分类决策的影响,往往可以起到提升模型性能的作用。
分别使用CountVectorizer和TfidfVectorizer,并且去掉停用词的条件下,对文本特征进行量化的朴素贝叶斯分类性能测试
# 去掉停用词
print("去掉停用词之后:")
count_filter_vec = CountVectorizer(analyzer='word', stop_words='english')
# 使用带有停用词过滤的CountVectorizer对训练和测试文本分别进行量化处理
X_count_filter_train = count_filter_vec.fit_transform(X_train)
X_count_filter_test = count_filter_vec.transform(X_test)
# 初始化默认参数的朴素贝叶斯分类器,并对CountVectorizer后的数据进行预测与准确性评估
mnb_count_filter = MultinomialNB()
mnb_count_filter.fit(X_count_filter_train, y_train)
print('The accuracy of classifying 20newsgroups using Naive Bayes (CountVectorizer by filtering stopwords):',
mnb_count_filter.score(X_count_filter_test, y_test))
y_count_filter_pred = mnb_count_filter.predict(X_count_filter_test)
# 输出更加详细的其他评价分类性能的指标
print(classification_report(y_test, y_count_filter_pred, target_names=news.target_names))

# 去掉停用词
print("去掉停用词之后:")
tfidf_filter_vec = TfidfVectorizer(analyzer='word', stop_words='english')
# 使用带有停用词过滤的TfidfVectorizer对训练和测试文本分别进行量化处理
X_tfidf_filter_train = tfidf_filter_vec.fit_transform(X_train)
X_tfidf_filter_test = tfidf_filter_vec.transform(X_test)
# 初始化默认参数的朴素贝叶斯分类器,并对TfidfVectorizer后的数据进行预测和准确性评估
mnb_tfidf_filter = MultinomialNB()
mnb_tfidf_filter.fit(X_tfidf_filter_train, y_train)
print('The accuracy of classifying 20newsgroups with Naive Bayes (TfidfVectorizer by filtering stopwords):',
mnb_tfidf_filter.score(X_tfidf_filter_test, y_test))
y_tfidf_filter_predict = mnb_tfidf_filter.predict(X_tfidf_filter_test)
# 输出更加详细的其他评价分类性能的指标
print(classification_report(y_test, y_tfidf_filter_predict, target_names=news.target_names))
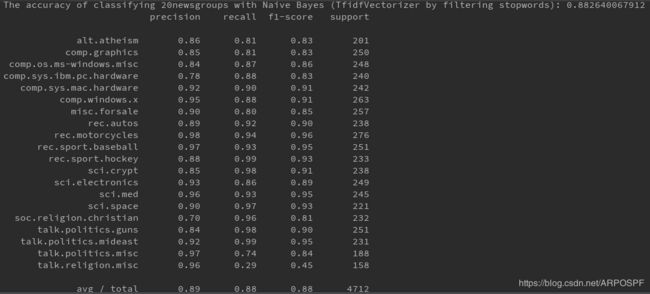
结果表明,对停用词进行过滤的文本特征抽取方法,平均要比不过滤停用词的模型综合性能高出3%~4%。
2.特征筛选
总体来讲,良好的数据特征组合不需太多,便可以使得模型的性能表现突出。
特征筛选与PCA这类通过选择主成分对特征进行重建的方法略有区别:对于PCA,经常无法解释重建之后的特征;但是特征筛选不存在对特征值的修改,而更加侧重于寻找那些对模型的性能提升较大的少量特征。
使用Titanic数据集,通过特征筛选的方法一步步提升决策树的预测性能
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@File : FeatureSelctionbyDT.py
@Author: Xinzhe.Pang
@Date : 2019/7/23 22:53
@Desc :
"""
import pandas as pd
titanic = pd.read_csv('./titanic.txt')
# 分离数据特征与预测目标
y = titanic['survived']
X = titanic.drop(['row.names', 'name', 'survived'], axis=1)
# 对缺失数据进行填充
X['age'].fillna(X['age'].mean(), inplace=True)
X.fillna('UNKNOWN', inplace=True)
# 分割数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
# 类别特征向量化
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
X_test = vec.transform(X_test.to_dict(orient='record'))
# 输出处理后特征向量的维度
print("处理后特征向量的维度:")
print(len(vec.feature_names_))
# 使用决策树模型依靠所有特征进行预测,并做出性能评估
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion='entropy')
dt.fit(X_train, y_train)
print("使用决策树模型依靠所有特征进行预测:")
print(dt.score(X_test, y_test))
# 从sklearn导入特征筛选器
from sklearn import feature_selection
# 筛选前20%的特征,使用相同配置的决策树模型进行预测,并评估性能
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=20)
X_train_fs = fs.fit_transform(X_train, y_train)
dt.fit(X_train_fs, y_train)
X_test_fs = fs.transform(X_test)
print("筛选前20%的特征,使用相同配置的决策树模型进行预测")
print(dt.score(X_test_fs, y_test))
# 通过交叉验证的方法,按照固定间隔的百分比筛选特征,并作图展示性能随特征筛选比例的变化
from sklearn.model_selection import cross_val_score
import numpy as np
percentiles = range(1, 100, 2)
results = []
for i in percentiles:
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=i)
X_train_fs = fs.fit_transform(X_train, y_train)
scores = cross_val_score(dt, X_train_fs, y_train, cv=5)
results = np.append(results, scores.mean())
print(results)
# 找到体现最佳性能的特征筛选的百分比
opt = np.where(results == results.max())[0]
print('Optimal number of features %d' % np.array(percentiles)[opt])
# 绘制变化曲线图
import pylab as pl
pl.plot(percentiles, results)
pl.xlabel('percentiles of features')
pl.ylabel('accuracy')
pl.show()
# 使用最佳筛选后的特征,利用相同参数的模型在测试集上进行性能评估
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=opt)
X_train_fs = fs.fit_transform(X_train, y_train)
dt.fit(X_train_fs, y_train)
X_test_fs = fs.transform(X_test)
print("使用最佳筛选后的特征,利用相同参数的模型在测试集上进行性能评估结果:")
print(dt.score(X_test_fs, y_test))
问题1:Traceback (most recent call last):
File "E:/python_learning/MyKagglePath/Advanced/PracticalSkills/Feature Selection/FeatureSelctionbyDT.py", line 72, in
print('Optimal number of features %d' %percentiles[opt])
TypeError: only integer scalar arrays can be converted to a scalar index
解决办法:print 'Optimal number of features',np.array(percentiles)[opt]


使用前7%维度的特征,最终的测试结果比最初使用全部特征的性能高出接近3个百分点。