数据结构 图论
文章目录
- 0.引入
- 0.1身边的图
- 0.2为什么用图
- 1.图论概述
- 1.1图论起源:七桥问题(欧拉路径、一笔画问题)
- 1.2图论知识点总览
- 2.图基本概念
- 2.1图的定义
- 2.2图的种类
- 2.3图的基本术语
- 2.4图的表示
- 3.图遍历
- 3.1深度优先遍历(DFS)
- 3.2广度优先遍历(BFS)
- 4.最小生成树
- 4.1定义
- 4.2经典算法
- 4.3Prim算法
- 4.4Kruskal 算法(最短边)
- 4.5应用
- 5.最短路径
- 5.1 定义
- 5.2 经典算法
- 5.3 Dijkstra算法
- 5.4 Floyd算法
0.引入
0.1身边的图
在生活中,随处可见与图相关的应用:
- 地图:在使用地图中,经常会想知道“从xx到xx的最短路线”这样的问题,要回答这些问题,需要把地图抽象成一个图(Graph),十字路口就是顶点,公路就是边。
- 互联网: 整个互联网其实就是一张图,它的顶点为网页,边为超链接,图论可以帮我们在网络上定位信息。
- 任务调度:当一些任务拥有优先级限制且需要满足前置条件时,如何在满足条件的情况下用最少的时间完成任务就需要用到图论。
- 社交网络(小世界理论):在使用社交网站时,个人就是一个顶点,你和你的朋友建立的关系则是边,分析社交网络的性质,通过广度优先搜索算法,来实现好友推荐,给用户推荐二度或者三度好友。
0.2为什么用图
Q:为什么要有图?
A:数据结构有线性表和树等,存在即可合理,为什么仍要引入图?不妨考虑下线性表等和图的局限性及优势。线性表仅局限于一个直接前驱和一个直接后继的关系。树也仅有一个直接前驱也就是父节点。那多对多的关系怎么处理? 这里就用到了图。图由一组顶点和一组将两个顶点相连的边组成,顶点表示对象或事物,顶点间的边表示对象间或事物间的关联关系,图本质是为了研究事物间的联系。
1.图论概述
1.1图论起源:七桥问题(欧拉路径、一笔画问题)
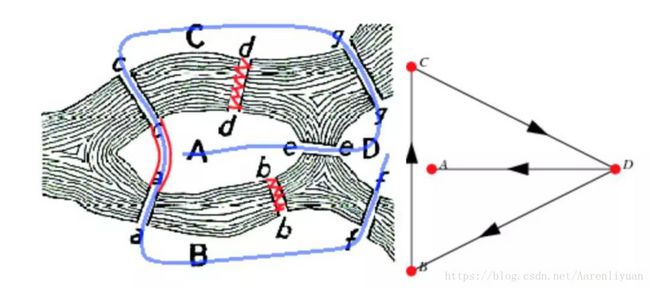
Q:如何在一场散步中走过全城各地区,七座桥中的每一座都必须恰好走过一次?
A:1735年8月26日,欧拉向圣彼得堡科学院提交了一篇论文,发表了对该问题的看法。为了抓住问题本质,他按照经典的数学思想,只把必要的信息提取出来,从而解决了问题,该问题无解!同时也开辟出了一个新的数学分支—图论(graph theory)。
- 首先,欧拉抛开问题的具体背景,将城镇、河流、桥梁抽象出来,分别用大写字母A、B、C、D表示4个区域,
- 再用小写字母a~g表示七座桥,
- 把路线视为字符串,而不是行人的实际散步路线,A、B、C、D 4个区域的面积与论证完全无关,把它们都抽象成一点,而把a到g的桥梁抽象成连接两点的线,从而把题目形象化,画成一张更简单的图,如图2所示。
- 所以,用11个字母可描述城里的任何一条路线,比如一条路线可以描述为:从A地经过c桥到达C地,再从C地经过g桥到达D地,从D地经过f桥到达B地,最后从B地经过b桥回到A地。这条路线也可以简记为AcCgDfBbA。
1.2图论知识点总览
- 图论知识丰富,按基础知识和引申知识分类如下:
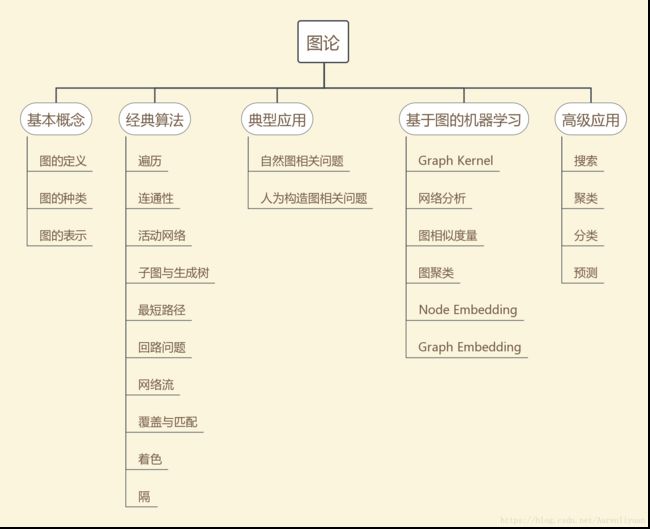
补充说明:
- 图可以是自然而成的图,如"城市交通网络"、互联网"、社交网络"、“社会关系”、"蛋白子分子结构"等
- 也可以人为构造图来解决问题,将相关问题抽象成图论的问题,使用图论相关方法去解决,如使用相似度度量对象之间是否相似来构造对象之间的边,如商品名称归一,"立白洗衣粉"与"洗衣粉"相似,"雕牌洗衣粉"也与"洗衣粉"相似(基于字符串相似度量,如字串、最长公共子序列、最长公共子字符串)
- 案例:“立白洗衣粉”、“雕牌洗衣粉”、"洗衣粉"作为点,它们之间是否相似作为它们之间是否存在边,"立白洗衣粉"与"洗衣粉"之间有边连接,"雕牌洗衣粉"与"洗衣粉"之间也有边连接,“立白洗衣粉"归集到"洗衣粉”,“雕牌洗衣粉"也归集到"洗衣粉”。这样同类的商品可以归集到一个粒度较为适中的粒度上(字符相似),可以大幅度降低商品个数,从而在某些任务上降低计算量,优化效率。
2.图基本概念
2.1图的定义
- 图G是由点与边构成,为一个二元组(V(G),E(G)),
- V(G)={v1,v2,…,vi,…,vj,…vn}是图G的顶点集合,它是一个非空集合。
- E(G)={(vi,vj)}是图G的边集合,每条边
- |V(G)|表示图G的顶点个数,即图的阶,|E(G)|表示图G的边的个数。
2.2图的种类
- 边是否有方向
- 有向图:边的两个端点是关系对称的,如QQ中的好友关系,A与B是好友,则A与B之间有边连接,并且A与B关于好友这个关系是对称的,或者说关系是无序的,A是B的好友,B也是A的好友,又如城市间的铁路网,一般A城市到B城市有直达列车,那么B也有到A的直达列车。
- 无向图:边的二元对是有序二元对,即关系是有序的,往往表示该条边上两顶点在该边的关系上不对称。如微博中的关注,显然也是一个有向图,你关注大V,大V不一定关注你。
- 混合图:不仅存在有向边,又存在无向边的图

-
边是否带权值
- 无权图,边没有权重,如城市之间,如果只关注是否存在直达交通;
- 有权图,边带有权重,关注直达交通的时间、花费、路径长度。
-
图是否连通
- 连通图,任意2个顶点之间都存在路径
- 非连通图 ,存在顶点之间无路径,如图2.2,存在连通子图,{0,1,2,3,4} 为最大连通子图(节点数最多),也称连通分量
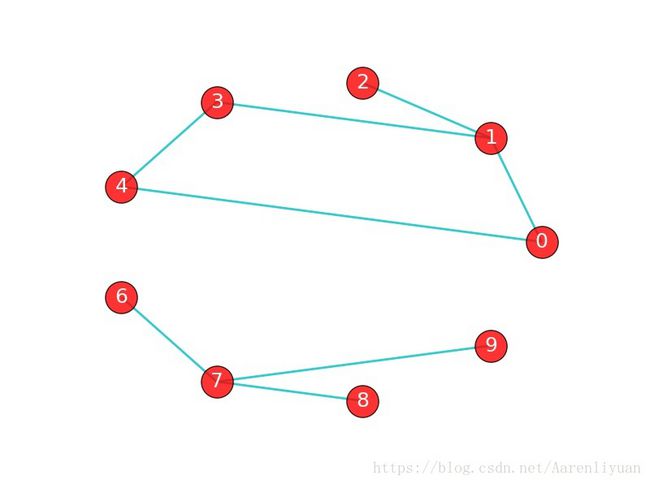
图2.2 非连通图 -
图是否存在自环和平行边
- 简单图,不存在自环和平行边
- 多重图 ,存在自环和平行边
2.3图的基本术语
- 顶点的度
- 无向图,顶点的度d(v)入度等于出度,是其邻接点的数目,即与之相连的边的数目;
- 有向图,每个顶点有入度d_in(v)与出度d_out(v)之分,入度便是以其为终点的边的数目,就是到达该点的边的数目(引入的),出度便是以其为起点的边的数目,该点出去的边的数目(引出的)。
- 点的度之和为边的2倍,无向图:sum(d(vi))=2*|E(G)|;有向图:sum(d_in(vi)+d_out(vi))=2*|E(G)|
- 一个图中度(有向图为入度与出度之和)为奇数的点的个数是偶数,因为2*|E(G)|是偶数,那么不存在奇数个奇数与偶数之和为偶数。
2.4图的表示
- 邻接矩阵: 使用一个V * V的布尔矩阵。当顶点v和顶点w之间有相连接的边时,将v行w列的元素设为true,否则为false。当图的顶点非常多时,邻接矩阵所需的空间将会非常大。且它无法表示平行边。

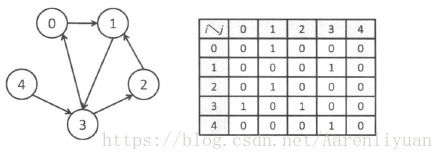
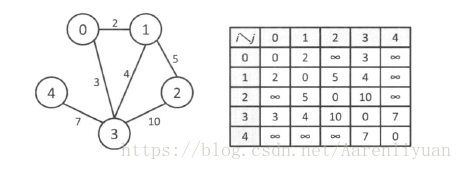
- 边的数组:使用一个Edge类,它含有两个int成员变量来表示所依附的顶点。这种方法简单直接,但无法实现查询邻接点的函数需要检查图中的所有边。
- 邻接表数组:使用一个顶点为索引的链表数组,其中的每个元素都是和该顶点相邻的顶点列表(邻接点)
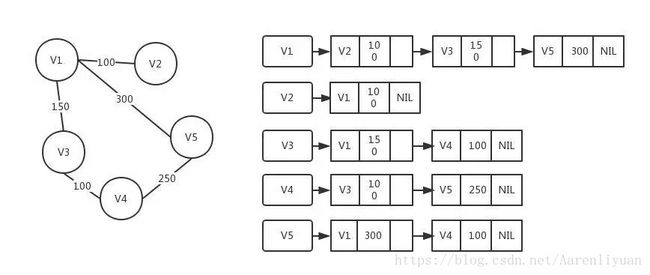
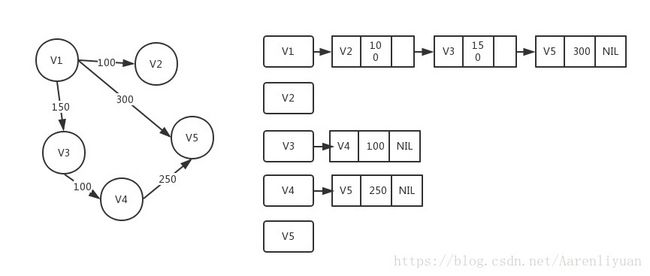
邻接表实现如下:
问题:随机生成一个图(可以是有向图或是无向图),图的顶点大概100个左右,若是有向图则边大概2000条左右,若是无向图则边大概1000条左右!并计算出边的入度和出度
代码:
1、Graph类
public class GraphRandom {
VertexRandom[] vertexArray=new VertexRandom[200];
int verNum=0;
int edgeNum=0;
}
2、Vertexl类
public class VertexRandom {
int verName;
int inRadius,outRadius;
VertexRandom nextNode;
}
3、随机图实现类
public class CreateGraph2 {
/**
* 由顶点名称返回顶点集合中的该顶点
* @param graph 图
* @param name 顶点名称
* @return返回顶点对象
*/
public VertexRandom getVertex(GraphRandom graph,int name){
for(int i=0;i"+current.verName);
current=current.nextNode;
}
System.out.println();
}
}
/**
* 输出图的入度和出度
* @param graph 图
*/
public void IORadius(GraphRandom graph){
for(int i=0;i 每种图实现的性能复杂度如下表:
| DS | 空间 | 添加边 | 检查两节点是否相邻 | 遍历所有节点 |
|---|---|---|---|---|
| 边数组 | E | 1 | E | E |
| 邻接矩阵 | V^2 | 1 | 1 | V |
| 邻接表 | E+V | 1 | deg(V) | deg(V) |
- 分析空间复杂度
- 邻接矩阵显然需要 O(|V|^2),邻接表需要 O(|V| + |E|)。
- 当T = 1,000,000时,即使邻接矩阵的每一个单元格仅占1字节,那么也需要1TB才能将数组存下。
- 考虑极限情况,当图的边变密到极限的时候有: ∣ V ∣ ( ∣ V ∣ − 1 ) / 2 = ∣ E |V|(|V|-1)/2=|E ∣V∣(∣V∣−1)/2=∣E,此时邻接表的空间开销与邻接矩阵相当,均为 O(|V|^2)。满足此种情况下的图被称为完全图,而当上述关系大致成立时,图被称为致密图,空间复杂度也大致相当。当|E|远不能达到致密状态时,我们称之为稀疏图。
- 分析时间开销
-
确认某两个顶点是否有边相连;
- 对于邻接表,我们需要访问目标节点下的整个链表来确认它们是否相连,时间复杂度O(|V|);
- 对于邻接矩阵,则直接询问二维数组即可,时间开销为常数O(1);
-
访问一个顶点的所有边(搜索);
- 对于邻接表,只需访问链表的长度;
- 而对于邻接矩阵,需要完全访问某一行/某一列才可以。
- 做一次广搜遍历,邻接表的复杂度为O(|V| + |E|),
- 而邻接矩阵为O(|V|^2)。
-
从上述计算我们可以看出,邻接表和邻接矩阵只有在特定条件下才有高低之分。大家一定要结合实际情况选择表达方式。
总结:
- 如果你的图是一张庞大的图,并且是稀疏的(|E(G)|<<|V(G)|*|V(G)|),如微博的关注网络,毕竟大v只是少数,大部分人的关注量很少(长尾)。这样邻接矩阵对于很多不存在边的顶点之间也使用了存储空间,邻接矩阵有大量的0元素,即邻接矩阵M是稀疏矩阵,这样会浪费很大的空间,甚至造成爆内存问题。而使用邻接表只需要存储节点与存在的边,存储空间降低了很多。
- 如果你需要快速访问两个顶点之间是否存在边,则邻接矩阵更好,如需要判断上图中v1与v3之间是否存在边,则邻接矩阵直接取第1行第3列的元素M13是否为0进行判断。而对于邻接表,则需要遍历v1的邻居链表来进行判断。其实,为了便于边存在判断,对邻接表进行改造也可以加快速度,那便是基于Hash表,每个节点的邻居链表使用Hash来存储,Hash表访问的理论时间复杂度是O(1)。
- 如果你的问如果你的问题是对图进行遍历(遍历需求),那么邻接表则更好,因为它不会存储无用的信息,存储方式符合遍历的需求。
- 在平时使用中,如果你的图很小(顶点个数少),或者很稠密,甚至是完全图,那么可以优先考虑邻接矩阵。但是大部分真实场景下,优先使用邻接表或者改造的邻接表。
3.图遍历
3.1深度优先遍历(DFS)
它从图中某个结点v出发,访问此顶点,然后从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到。若图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中的所有顶点都被访问到为止。
基本实现思想:
(1)访问顶点v;
(2)从v的未被访问的邻接点中选取一个顶点w,从w出发进行深度优先遍历;
(3)重复上述两步,直至图中所有和v有路径相通的顶点都被访问到。
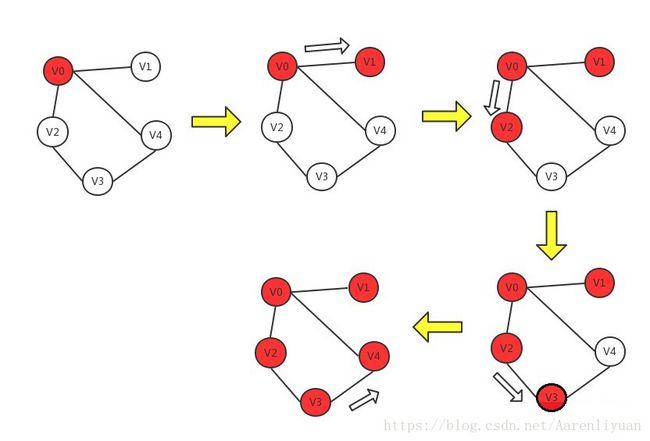
一个点往下试,记录是否遍历过(因为存在环)。
访问顺序:v0-v1-v2-v3-v4
递归实现
(1)访问顶点v;visited[v]=1;//算法执行前visited[n]=0
(2)w=顶点v的第一个邻接点;
(3)while(w存在)
if(w未被访问)
从顶点w出发递归执行该算法;
w=顶点v的下一个邻接点;
非递归实现
(1)栈S初始化;visited[n]=0;
(2)访问顶点v;visited[v]=1;顶点v入栈S
(3)while(栈S非空)
x=栈S的顶元素(不出栈);
if(存在并找到未被访问的x的邻接点w)
访问w;visited[w]=1;
w进栈;
else
x出栈;
3.2广度优先遍历(BFS)
它是一个分层搜索的过程和二叉树的层次遍历十分相似,它也需要一个队列以保持遍历过的顶点顺序,以便按出队的顺序再去访问这些顶点的邻接顶点。
基本实现思想:
(1)顶点v入队列。
(2)当队列非空时则继续执行,否则算法结束。
(3)出队列取得队头顶点v;访问顶点v并标记顶点v已被访问。
(4)查找顶点v的第一个邻接顶点col。
(5)若v的邻接顶点col未被访问过的,则col入队列。
(6)继续查找顶点v的另一个新的邻接顶点col,转到步骤(5), 直到顶点v的所有未被访问过的邻接点都处理完。则转到步骤(2)。
另:广度优先遍历图是以顶点v为起始点,由近至远,依次访问和v有路径相通而且路径长度为1,2,……的顶点。为了使“先被访问顶点的邻接点”先于“后被访问顶点的邻接点”被访问,需设置队列存储访问的顶点。
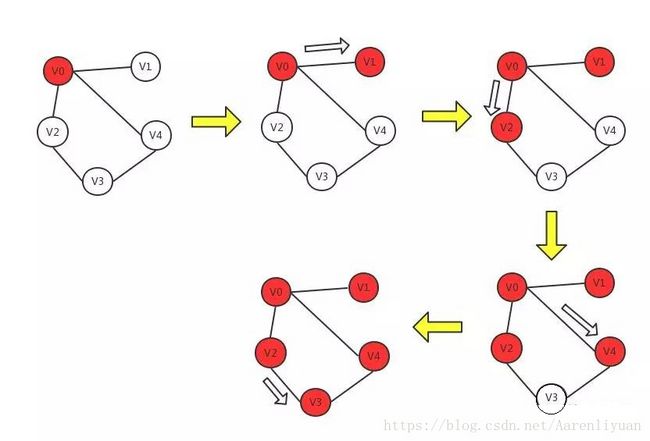
访问顺序:v0-v1-v2-v4-v3
伪代码如下:
(1)初始化队列Q;visited[n]=0;
(2)访问顶点v;visited[v]=1;顶点v入队列Q;
(3) while(队列Q非空)
v=队列Q的对头元素出队;
w=顶点v的第一个邻接点;
while(w存在)
如果w未访问,则访问顶点w;
visited[w]=1;
顶点w入队列Q;
w=顶点v的下一个邻接点。
代码实现:
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class Graph {
private int number = 9;
private boolean[] flag;
private String[] vertexs = { "A", "B", "C", "D", "E", "F", "G", "H", "I" };
private int[][] edges = {
{ 0, 1, 0, 0, 0, 1, 1, 0, 0 },
{ 1, 0, 1, 0, 0, 0, 1, 0, 1 },
{ 0, 1, 0, 1, 0, 0, 0, 0, 1 },
{ 0, 0, 1, 0, 1, 0, 1, 1, 1 },
{ 0, 0, 0, 1, 0, 1, 0, 1, 0 },
{ 1, 0, 0, 0, 1, 0, 1, 0, 0 },
{ 0, 1, 0, 1, 0, 1, 0, 1, 0 },
{ 0, 0, 0, 1, 1, 0, 1, 0, 0 },
{ 0, 1, 1, 1, 0, 0, 0, 0, 0 }
};
void DFSTraverse() {
flag = new boolean[number];
for (int i = 0; i < number; i++) {
if (flag[i] == false) {// 当前顶点没有被访问
DFS(i);
}
}
}
void DFS(int i) {
flag[i] = true;// 第i个顶点被访问
System.out.print(vertexs[i] + " ");
for (int j = 0; j < number; j++) {
if (flag[j] == false && edges[i][j] == 1) {
DFS(j);
}
}
}
void DFS_Map(){
flag = new boolean[number];
Stack stack =new Stack();
for(int i=0;i queue = new LinkedList();
for(int i=0;i 总结:BFS与DFS都是对图进行遍历,只是遍历的点的优先次序不一样,如何选择呢?
- BFS是优先访问完源点的所有距离为1(1-阶邻居)的节点(邻接点),然后再访问完所有距离为2的节点(2-阶邻居),以此类推。这样每访问完一个节点时,便可以知道其离源点的最短路径和最短路径的长度,以及哪些节点离源点的最短路径比其最短路径长度短。也就是,如果你的问题里面需要计算最短距离,那么BFS可以满足,并且如果离源点近的点,则可以较快速被发现。
- BFS可用于网络中寻找所有邻居(如BitTorrent对等网络的邻居),又如离给定节点的K阶距离内的所有节点(如附近的移动基站,社交网络中某人的K阶邻居人员,如六阶理论,任何人都可以通过六个人认识世界上任何一个人等)。
- DFS是一直往深入地进行访问,直到无可访问节点时,回退到上一节点继续深入访问。就如在进行一系列决策时,首先选择某个策略,选择该策略之后,会导致进一步的选择,不断递归,从而导致一个不断向下深入的决策树。如果发现某个决策不对,则马上回退到上一个决策,切换到上一个决策后得到的继续决策集中的另一个决策。
- DFS常用于游戏,例如,在围棋、国际象棋等棋类游戏中,当你决定要采取何种动作时,你会首先选择其中一个动作,然后想象你的对手可能采取的动作,然后你继续选择动作,这样下去。您可以通过查看哪个动作导致最佳结果来选择。游戏动作树中只有一些路径会导致你的胜利。有些选择会导致对手获胜,当你需要保证取胜对手时,你必须回溯到前一节点并尝试不同的路径。通过这种方式,你可以探索这棵树,直到你找到一条成功的结论。然后你沿这条路走了第一步,对手走一步,你根据对手走的一步,继续选择你可能会赢的下一步,一直这样下去。
- 总的来说,如何选择很大程度上取决于你所面对的问题、图的结构、以及需要搜索寻找的目标节点(问题解)的数目与位置(离源点的距离),一般来说:
- 如果您寻找的目标节点离源点不远,那么优先BFS。
- 如果您的图是非常深的,即图中存在很多节点离源点很远,并且需要寻找的目标节点不多(即解的数据不多),从而DFS可能需要消耗的时间比较多,那么优先BFS。
- 如果,您不确定“解”离源点的距离,或者“解”的数目,那么优先使用BFS,因为DFS可能会造成大部分的进行了很深的搜索却是无效的。
- 如果您的图是一个宽图,即距离源节点每一层的节点数目都不少,图的深度较浅,如果使用BFS,则每一层需要访问的节点较多,并且内存消耗较大,那么优先DFS。
- 如果问题的解较多,并且离源点较远,那么优先DFS。BFS比DFS的空间复杂度更高,但是DFS可能会陷入无用的深度搜索。
- 最后,无论何种搜索,最好结合剪枝技术,即去掉明显找不到解的搜索,来优化搜索效率。
4.最小生成树
4.1定义

为了解决公路铺电缆问题,使得代价最小,设想要包含图中所有的顶点n,同时代价最少,第一个想到的自然是减少边的数量,而要连接所有n个顶点,显然至少需要n-1条边。而我们知道一颗树(tree)就是n个顶点,n-1条边,我们把构造连通网的最小代价生成树称为最小生成树,本质是组合优化问题,最小生成树一定包含最短边。
4.2经典算法
普里姆算法和克鲁斯卡尔算
4.3Prim算法
工作步骤
(1) 构建全部顶点集V,选取初始顶点,加入顶点集U。
(2) 找U中顶点与V-U中顶点的所有边。
(3) 选取所有边中的最短边加入最小生成树。
(4) 将最短边另一头的顶点,加入顶点集合U。
(5) 继续找U中顶点与V-U中顶点的所有边
(6) 继续选取最短边,将最短边加入最小生成树,并将最短边另一头顶点加入U。
(7) 如此循环反复,直至U=V

总结:
Q:为什么不会构成环?
A:在寻找边时,只是找U与V-U中顶点所构成的边,而U中内部顶点的边是不会找的。找到最短边后,直接将另一头顶点加入U了,也就是说这两个顶点都在U中了,即使这2个顶点还有其他路径,后面都不会再找,也就不会构成回路了。
4.4Kruskal 算法(最短边)
- 基本过程:先对图中的所有边按照权重值从小到大进行排序,然后着手选取边构建最小生成树。新边加入不能有环。
- 环判断依据:加入一条边构成环的话,则该边的两个顶点除了这条边外,还有另一条路径,即这两个顶点在加入这个边之前,就是连通的,或者在一个连通子图上。

总结:
在G=(V,E)中,我们令最小生成树的初始状态为只有n个顶点,0条边的非连通图T=(V,{}),图中每个顶点都是一个连通子图,即有n个连通子图。依次从E中按顺序从小到大选择边,若该边的两个顶点落在T中不同的连通子图上,则将次变加入到T中,否则舍去此边,依次类推,直到T中所有顶点都在同一个连通子图上为止。时间复杂度为O(eloge)
Prim和Kruskal对比分析:
- Prim算法的时间复杂度在于初始化与嵌套的两个for循环(第一层循环下面有两个循环),因此其时间复杂度为 O ( ∣ V ∣ ) + O ( 2 ∗ ∣ V ∣ ∗ ∣ V ∣ ) = O ( ∣ V ∣ ∗ ∣ V ∣ ) O(|V|)+O(2*|V|*|V|)=O(|V|*|V|) O(∣V∣)+O(2∗∣V∣∗∣V∣)=O(∣V∣∗∣V∣)
- Kruskal算法主要在于:初始化、对边进行排序、遍历边并求端点所在的连通分量,初始化的时间复杂度为 O ( ∣ V ∣ ) O(|V|) O(∣V∣)、边排序时间复杂度为 O ( ∣ E ∣ l o g ∣ E ∣ ) O(|E|log|E|) O(∣E∣log∣E∣)(最快的排序算法时间复杂度 O ( n l o g n ) O(nlogn) O(nlogn))、遍历边并求端点所在连通分量的时间复杂度为 O ( ∣ E ∣ l o g ∣ V ∣ O(|E|log|V| O(∣E∣log∣V∣)(遍历边时间复杂度为 O ( ∣ E ∣ ) O(|E|) O(∣E∣),并查集的平均时间复杂度为 O ( l o g ∣ V ∣ O(log|V| O(log∣V∣),因此Kruskal算法的时间复杂度为 O ( ∣ V ∣ ) + O ( ∣ E ∣ l o g ( ∣ E ∣ ) ) + O ( 2 ∗ ∣ E ∣ l o g ∣ V ∣ ) = O ( ∣ E ∣ l o g ( ∣ E ∣ ) ) + O ( ∣ E ∣ l o g ∣ V ∣ ) O(|V|)+ O(|E|log(|E|))+ O(2*|E| log|V|)= O(|E|log(|E|))+ O(|E| log|V|) O(∣V∣)+O(∣E∣log(∣E∣))+O(2∗∣E∣log∣V∣)=O(∣E∣log(∣E∣))+O(∣E∣log∣V∣),当图为稠密图时,即边的数量比点的数量多得多,那么时间复杂度可以表示为 O ( ∣ E ∣ l o g ( ∣ E ∣ ) ) O(|E|log(|E|)) O(∣E∣log(∣E∣));当图为稀疏图时,即 ∣ E ∣ < < ∣ V ∣ ∗ ∣ V ∣ |E|<<|V|*|V| ∣E∣<<∣V∣∗∣V∣,时间复杂度可以表示为 O ( ∣ E ∣ l o g ∣ V ∣ ) O(|E| log|V|) O(∣E∣log∣V∣)。
- 从时间复杂度上来看,当图为稀疏图时,Kruskal算法比Prim算法更优,越稀疏,越优,最极端情况下,图本身就是 ∣ V ∣ − 1 |V|-1 ∣V∣−1条边组成的连通图(其最小生成树是自身);当图为稠密图时,Prim算法性能优于Kruskal算法。
- 对于空间复杂度:Prim算法需要索引每个点的边,通常使用邻接矩阵进行存储,为了节省空间也可以使用HashMap改造的邻接表。而Kruskal算法只需要遍历边,不需要进行索引,通常使用邻接表。邻接矩阵的空间复杂度为 O ( ∣ V ∣ ∗ ∣ V ∣ ) O(|V|*|V|) O(∣V∣∗∣V∣),邻接表的空间复杂度为 O ( ∣ V ∣ + ∣ E ∣ ) O(|V|+|E|) O(∣V∣+∣E∣),因此它们的空间复杂度取决于它们图的存储方式。
- 从Prim算法与Kruskal算法的思想可知,Prim算一种直接思想,将图点集分成两个集合,不断扩充一个集合而缩减另一个集合,直到成为一个集合,其实也是一种动态规划的思想。而Kruskal算法便是一种贪心思想,不断选择符合要求的最小权值边,直到所有的点构成一个连通图( ∣ V ∣ − 1 |V|-1 ∣V∣−1条边)。
4.5应用
- 城市高速公路问题:n个城市之间建立高速公路,两个城市之间修建一条,城市之间造价不同。如何修建高速使得这n个城市之间连通,且使得总造价最小。
- 还有路由器之间的连接、站点通信网络、输油管道等问题。
5.最短路径
5.1 定义
最短路径:从某顶点出发,沿图的边到达另一顶点所经过的路径中,各边上权值之和最小的一条路径。
5.2 经典算法
Dijkstra算法,Floyd算法,A*算法
5.3 Dijkstra算法
(1)迪杰斯特拉(Dijkstra)算法按路径长度递增次序产生最短路径。先把V分成两组:S:已求出最短路径的顶 点的集合;V-S=T:尚未确定最短路径的顶点集合
(2)将T中顶点按最短路径递增的次序加入到S中
(3)初使,令 S={V0},T={其余顶点},T中顶点对应的距离值, 若存在
(4)从T中选取一个其距离值为最小的顶点W,加入S,对T中顶点的距离值进行修改:若加进W作中间顶点,从V0到Vi的距离值比不加W的路径要短,则修改此距离值
(5)重复上述步骤,直到S中包含所有顶点,即S=V为止。
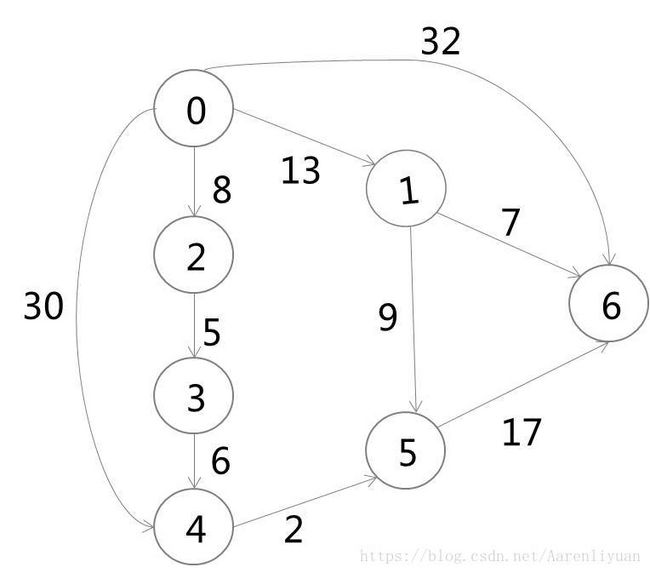
| 终点 | V0到各点最短路径及长度 | ||||
|---|---|---|---|---|---|
| v1 | 13 |
13 |
– | – | – |
| v2 | 8 |
– | – | – | – |
| v3 | inf | 13 |
13 |
– | – |
| v4 | 30 |
30 |
30 |
19 |
– |
| v5 | inf | inf | 22 |
22 |
21 |
| v6 | 32 |
32 |
20 |
20 |
20 |
| vj |
代码如下:
public class Graph {
/*
* 顶点
*/
private List vertexs;
/*
* 边
*/
private int[][] edges;
/*
* 没有访问的顶点
*/
private Queue unVisited;
public Graph(List vertexs, int[][] edges) {
this.vertexs = vertexs;
this.edges = edges;
initUnVisited();
}
/*
* 搜索各顶点最短路径
*/
public void search(){
while(!unVisited.isEmpty()){
Vertex vertex = unVisited.element();
//顶点已经计算出最短路径,设置为"已访问"
vertex.setMarked(true);
//获取所有"未访问"的邻居
List neighbors = getNeighbors(vertex);
//更新邻居的最短路径
updatesDistance(vertex, neighbors);
pop();
}
System.out.println("search over");
}
/*
* 更新所有邻居的最短路径
*/
private void updatesDistance(Vertex vertex, List neighbors){
for(Vertex neighbor: neighbors){
updateDistance(vertex, neighbor);
}
}
/*
* 更新邻居的最短路径
*/
private void updateDistance(Vertex vertex, Vertex neighbor){
int distance = getDistance(vertex, neighbor) + vertex.getPath();
if(distance < neighbor.getPath()){
neighbor.setPath(distance);
}
}
/*
* 初始化未访问顶点集合
*/
private void initUnVisited() {
unVisited = new PriorityQueue();
for (Vertex v : vertexs) {
unVisited.add(v);
}
}
/*
* 从未访问顶点集合中删除已找到最短路径的节点
*/
private void pop() {
unVisited.poll();
}
/*
* 获取顶点到目标顶点的距离
*/
private int getDistance(Vertex source, Vertex destination) {
int sourceIndex = vertexs.indexOf(source);
int destIndex = vertexs.indexOf(destination);
return edges[sourceIndex][destIndex];
}
/*
* 获取顶点所有(未访问的)邻居
*/
private List getNeighbors(Vertex v) {
List neighbors = new ArrayList();
int position = vertexs.indexOf(v);
Vertex neighbor = null;
int distance;
for (int i = 0; i < vertexs.size(); i++) {
if (i == position) {
//顶点本身,跳过
continue;
}
distance = edges[position][i]; //到所有顶点的距离
if (distance < Integer.MAX_VALUE) {
//是邻居(有路径可达)
neighbor = getVertex(i);
if (!neighbor.isMarked()) {
//如果邻居没有访问过,则加入list;
neighbors.add(neighbor);
}
}
}
return neighbors;
}
/*
* 根据顶点位置获取顶点
*/
private Vertex getVertex(int index) {
return vertexs.get(index);
}
/*
* 打印图
*/
public void printGraph() {
int verNums = vertexs.size();
for (int row = 0; row < verNums; row++) {
for (int col = 0; col < verNums; col++) {
if(Integer.MAX_VALUE == edges[row][col]){
System.out.print("X");
System.out.print(" ");
continue;
}
System.out.print(edges[row][col]);
System.out.print(" ");
}
System.out.println();
}
}
}
5.4 Floyd算法
Floyd算法的基本思想如下:从任意节点A到任意节点B的最短路径不外乎2种可能,1是直接从A到B,2是从A经过若干个节点到B,所以,我们假设dist(AB)为节点A到节点B的最短路径的距离,对于每一个节点K,我们检查dist(AK) + dist(KB) < dist(AB)是否成立,如果成立,证明从A到K再到B的路径比A直接到B的路径短,我们便设置 dist(AB) = dist(AK) + dist(KB),这样一来,当我们遍历完所有节点K,dist(AB)中记录的便是A到B的最短路径的距离
void floyd() {
for(int i=1; i<=n ; i++){
for(int j=1; j<= n; j++){
if(map[i][j]==Inf){
path[i][j] = -1;//表示 i -> j 不通
}else{
path[i][j] = i;// 表示 i -> j 前驱为 i
}
}
}
for(int k=1; k<=n; k++) {
for(int i=1; i<=n; i++) {
for(int j=1; j<=n; j++) {
/*
实际中为防止溢出,往往需要选判断 dist[i][k]和dist[k][j]都不是Inf ,只要一个是Inf,就不必更新
*/
if(!(dist[i][k]==Inf||dist[k][j]==Inf)&&dist[i][j] > dist[i][k] + dist[k][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
//path[i][k] = i;//删掉
path[i][j] = path[k][j];
}
}
}
}
}
void printPath(int from, int to) {
/*
* 这是倒序输出,若想正序可放入栈中,然后输出
*/
while(path[from][to]!=from) {
System.out.print(path[from][to] +"");
to = path[from][to];
}
}
- Floyd算法另一种理解为动态规划,
- 设图G中n 个顶点的编号为1到n。令 c [ i , j , k ] c [i, j, k] c[i,j,k]表示从i 到j 的最短路径的长度,其中k 表示该路径中的最大顶点, c [ i , j , k ] c[i,j,k] c[i,j,k]这条最短路径所通过的中间顶点最大不超过k。
- 如果G中包含边
- 如果G中不包含边
- 对于任意的k>0,中间顶点不超过k 的i 到j 的最短路径有两种可能:该路径含或不含中间顶点k。若不含,该路径长度应为 c [ i , j , k − 1 ] c[i, j, k-1] c[i,j,k−1],否则长度为$ c[i, k, k-1] +c [k, j, k-1] 。 。 。c[i, j, k]$可取两者中的最小值。
- 状态转移方程: c [ i , j , k ] = m i n c [ i , j , k − 1 ] , c [ i , k , k − 1 ] + c [ k , j , k − 1 ] c[i, j, k]=min{c[i, j, k-1], c [i, k, k-1]+c [k, j, k-1]} c[i,j,k]=minc[i,j,k−1],c[i,k,k−1]+c[k,j,k−1],k>0。这样,问题便具有了最优子结构性质,可以用动态规划方法来求解。
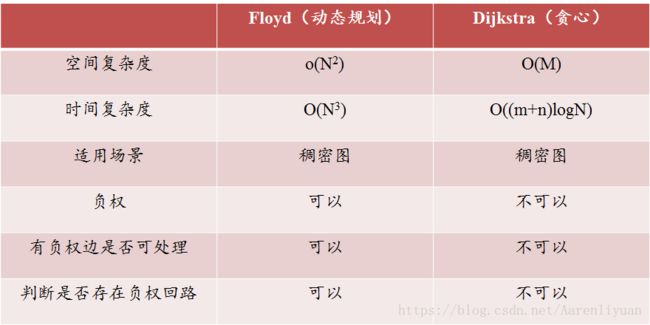
总结: