【详解】Python写爬虫脚本的教程
【2015-12-11更新】本文是无聊以及不成熟时候的记录,都是最最基础的东西,很多都是废话,可以不看!
【2015-12-16更新】研究出了模拟登录b站的方法,该篇虽然废话,但都是基础,看过该篇可继续看下一篇---《Python模拟登录b站并抓取信息》
因为过去了一段时间,有好多点都可以直接写,反而不知道从哪儿开始写。所以写一个从零开始的Python爬虫教程,也是自己从头再学习和复习的一个过程。
1.Python的安装
我们这里安装Python2.7,虽然据说Python3有好些地方进步了不少(比如比较让人头疼的编码问题)
具体安装过程就不赘述了,百度很好找到。
2.PyCharm的安装
这个是比较好的一个Python编程工具,强烈推荐使用。安装过程自行百度!
3.第三方模块的安装使用
Python如同Java一样,也有很多包,包里面有很多方法函数。除了自带的各种,我们可以通过安装第三方的模块来简化我们的开发过程。
在我的学习过程中,只用到了两种安装方法:
1. 针对个别模块,可以找到安装文件,点击打开后如同普通软件一样有安装向导,比如pygame就是这样的
2. 最常见的,就是解压之后一个文件夹,文件夹中有setup.py的文件。通过命令行来安装,cmd-->cd \--->f:--->cd f:/a/b/c
定位到setup.py这个文件所在的文件夹下,然后,加上setup.py install 完成安装
以上这些算是准备工作,接下来开始正式介绍如何写Python爬虫脚本。
顺序由上至下依次写:
1.顶端的声明
#!/usr/bin/python
# -*- coding: utf-8 -*-第二行:是用来指定文件编码为utf-8。推荐使用utf-8这样可以在脚本文件中添加中文注释,比较方便的。
2.版本标识
__author__ = "$Author: Python$"
__version__ = "$Revision: 1.0 $"
__date__ = "$Date: 2015-10-22 15:35$"3.
############################################################### # 功能:模拟登录哔哩哔哩并抓取个人主页关注动态的视频信息 ###############################################################表名功能
4.模拟登录
首先讲模拟登录。我们从网站上抓取数据,很多时候都需要先登录,然后进入网页。
说模拟登录,有句话是这么说的,代码其实很好写,只是分析登录的过程比较麻烦!
其实写过一次之后真的是这样的,代码的写法其实比较死,关键是每个网站的登录过程都不同。分析清楚这个过程就算是完成了大半的模拟登录工作了!
我们这里做一个功能,模拟登录bilibili并抓取当前时间正在观看的前十名,显示视频名称并显示点击数。
首先贴一个之前做的模拟登录某数据后台的代码,作为记录对照以及参考。
这个是我最初做模拟登录的第一版代码,也是最为基础的代码。
#!/usr/bin/python # -*- coding: utf-8 -*- import re import cookielib import urllib import urllib2 import optparse def login(): #输入用户名密码的数据 # parse input parameters parser = optparse.OptionParser() parser.add_option("-u","--channelId",action="store",type="string",default='',dest="channelId",help="Your ChannelId"); parser.add_option("-p","--password",action="store",type="string",default='',dest="password",help="Your Password"); (options, args) = parser.parse_args() #导出所有的选项变量,方便之后使用 # export all options variables, then later variables can be used for i in dir(options): exec(i + " = options." + i) #处理cookie cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener) downjoyMainUrl = "http://money.downjoy.com/connectchannel/login.jsp" resp = urllib2.urlopen(downjoyMainUrl) #开始模拟登录 downjoyMainLoginUrl = "http://money.downjoy.com/connectchannel/login.html" postDict = { 'channelId' : "1039", 'password' : "xxx", } # here will automatically encode values of parameters postData = urllib.urlencode(postDict) req = urllib2.Request(downjoyMainLoginUrl, postData) #编码 req.add_header('Content-Type', "application/x-www-form-urlencoded") resp = urllib2.urlopen(req) #加上.decode('utf-8').encode('gb2312')就能够解决中文乱码的问题 html = resp.read().decode('utf-8').encode('gb2312') #返回了网页 print html if __name__=="__main__": login()
接下来分析bilibili的登录流程,我用的是火狐浏览器,点击F12然后分析具体流程!
1. 手动登录
看一下正常通过浏览器登录需要输入什么信息。
我们发现,登录bilibili需要输入用户名、密码,以及,验证码
2.先到达登录页面
#!/usr/bin/python # -*- coding: utf-8 -*- import cookielib import urllib import urllib2 import optparse def login(): #输入用户名密码的数据 parser = optparse.OptionParser() parser.add_option("-u","--channelId",action="store",type="string",default='',dest="channelId",help="Your ChannelId"); parser.add_option("-p","--password",action="store",type="string",default='',dest="password",help="Your Password"); (options, args) = parser.parse_args() for i in dir(options): exec(i + " = options." + i) #处理cookie cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener) downjoyMainUrl = "https://account.bilibili.com/login" resp = urllib2.urlopen(downjoyMainUrl) html = resp.read().decode('utf-8') print html这里出现的第一个链接,就是bilibili登录网址,我们打印出网页,发现的确是登录页面的HTML显示
3.分析如何登录
我们打开F12,手动输入用户名密码以及验证码,登录!
我们分析时,在F12的控制台中最需要找的是,
我们输入的用户名、密码、验证码分别在哪里!
找到了这些登录网站所需要的信息,就可以模拟登录了,因为正常登录只需要这三个信息!
####怎么找我们输入的三个信息呢?
我们要记得,明确一点,登录是具有加密性的操作,所以肯定是通过post方式来提交参数的。
所以我们只需要在POST方式中寻找就可以了!
我们首先到登录页面,打开F12,清除一下现有信息,重新载入,发现除了最初的两个GET,剩下的所有POST都是一样的,而且随着时间推移不断增加,推测应该是网站以一定的频率向网站后台请求着什么。。。
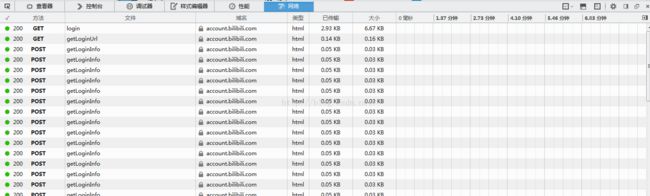
这种发起请求的url肯定是有用的,我们先留个心,待会肯定会回到这条url找寻一些信息。
然后登录,我们需要在这一堆一样的POSTurl下找寻新的POST,在里面找到我们输入的信息。

我们发现,登录过程中,接了一个GET,一个POST,我们要找的信息肯定就在这两个之中!

果不其然,我们在post请求下的参数这里发现了我们刚刚输入的userid,还有pwd,即用户名和密码。
再回忆一下我们刚刚输入的验证码,发现是vdcode对应的参数。
至此,登录需要的三个信息我们都找到了,当然,确应我们刚刚所说,都在POST请求里。
####分析除了输入信息外其他的信息?
我们手动登录输入的信息都找到了,但有了这些还不一定能够登录。因为还有别的参数,我们用浏览器登录时,这些参数的获取和提交,浏览器替我们做了。
而用Python代码手动模拟登录时,这些工作需要我们自己做。
首先,act、gourl这两个肯定是不变的。
剩下的keeptime我们读一下名字,不知道它是干嘛的,但我们要分析它是可变的还是不可变的!
如果可变,我们要分析它从哪儿来;
如果不可变,我们就以分析到的值为准就可以了。
多登录几次,观察一下这个keeptime的变化。
最终我们发现,几次登录这个keeptime是不变化的。所以不用管它了!记住它是604800就可以了!
####验证码如何获取?
接下来分析验证码的问题。