【论文学习】零样本学习:Zero-Shot learning(2018CVPR)
1、简介
见过和没见过的类别都要提供类别描述信息(比如用户定义的属性标注、类别的文本描述、类别名的词向量等);某些描述信息是各个类别共有的。这些描述信息通常被称为辅助信息或语义表征。
典型 ZSL 方法的一个通用假设是:存在一个共有的嵌入空间,其中有一个映射函数:
![]()
定义这个函数的目的是对于见过或没见过的类别,衡量图像特征 φ(x) 和语义表征 ψ(y) 之间的相容性(compatibility)。W 是所要学习的视觉-语义映射矩阵。

2、以往工作的缺陷
到目前为止,映射矩阵 W 的学习(尽管对 ZSL 很重要)的主要推动力是视觉空间和语义空间之间对齐损失的最小化。但是,ZSL 的最终目标是分类未见过的类别。因此,视觉特征 φ(x) 和语义表征 ψ(y) 应该可以被区分开以识别不同的目标。不幸的是,这个问题在 ZSL 领域一直都被忽视了,几乎所有方法都遵循着同一范式:1)通过人工设计或使用预训练的 CNN 模型来提取图像特征;2)使用人类设计的属性作为语义表征。这种范式存在一些缺陷:
第一,图像特征 φ(x) 要么是人工设计的,要么就是来自预训练的 CNN 模型,所以对零样本识别任务而言可能不具有足够的表征能力。尽管来自预训练 CNN 模型的特征是学习到的,然而却受限于一个固定的图像集(比如 ImageNet),这对于特定 ZSL 任务而言并不是最优的。
第二,用户定义的属性 ψ(y) 是语义描述型的,但却并不详尽,因此限制了其在分类上的鉴别作用。也许在 ZSL 数据集中存在一些预定义属性没有反映出来的鉴别性的视觉线索,比如河马的大嘴巴。另一方面,如图 1 所示,「大」、「强壮」和「大地」等被标注的属性是很多目标类别都共有的。这是不同类别之间的知识迁移所需的,尤其是从见过的类别迁移到没见过的类别时。但是,如果两个类别(比如豹和虎)之间共有的(用户定义的)属性太多,它们在属性向量空间中将难以区分。
第三,现有 ZSL 方法中的低层面特征提取和嵌入空间构建是分开处理的,并且通常是独立进行的。因此,现有研究中很少在统一框架中考虑这两个组分。
3、我们的方法
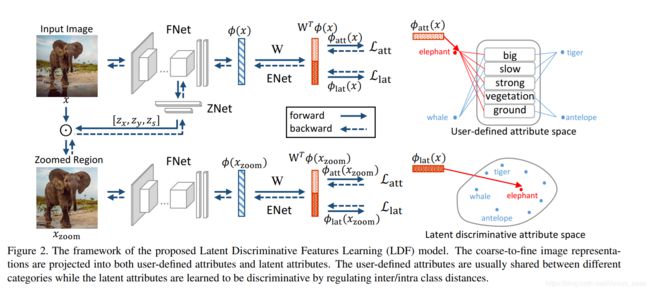
原则上该框架包含多个图像尺度,但为描述清楚,这里仅给出了有 2 个图像尺度的情况作为示例。在每个图像尺度中,网络都由三个不同组分构成:
1)图像特征网络(FNet),用于提取图像表征;是和网络的其他部分一起训练的(其他工作是分开训练)。
- 结构:VGG19, the FNet starts from conv1 to fc7; for GoogLeNet, it starts from conv1 to pool5
- pre-trained on ImageNet
2)缩放网络(ZNet),用于定位最具鉴别性(鉴别性指图片中的目标对象+背景,尤其是用户定义的属性)的区域,然后将其放大。
- 输入:FNet的最后conv层,(e.g., conv5 4 in VGG19),输出:目标正方形区域中心的x,y坐标和边长Zs

- 结构:two-stacked fully-connected layers (1024-3) followed by the sigmoid activation function。之后再用双线性插值将裁减图片恢复为原图大小
3)嵌入网络(ENet),用于构建视觉信息和语义信息关联在一起的嵌入空间。亮点在,本文将特征映射到两个空间:user-defined attributes (UA) and latent discriminative attributes (LA).

Waug ∈ R^d×2k。we let the first k-dim embedded feature φatt(x) correspond to the UA and the second k-dim being associated with the LA。φ(x) is the d-dim image representation obtained by the FNet。
- loss:(xi,xk是同一类,j是另外一类。第二个loss为意思是triplet loss,可以固定差异度,便于细粒度分类)

![]()
总loss:(s1代表图中第一行,即scale 1)

4、预测
1)用UA预测:用输入的投影φatt(x)和提供的标签a^c(c∈YU)
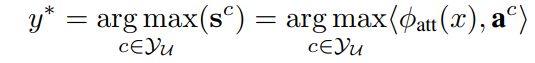
2)用LA预测:
首先,得到一个LA模型(all samples xi from the seen class s are projected to their LA features and the mean of features are utilized as the LA prototype of class s);![]()
![]()
接着,对一个未知类u,计算和其他类S之间的关系

得到类u的LA模型:

得到类u的预测结果:
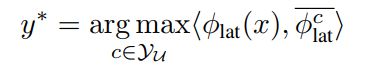
最后两者取大:argmax(UA,LA)
5、训练策略
1)用ImageNet初始化FNet,然后再取用某些层
2)用初始化的FNet找最后conv层中activation最高的一个正方形区域(设为原图的一半),再用这个区域去预训练ZNet
3)固定ZNet,训练FNet和ENet
6、Dataset
1)Animals with Attributes (AwA)
30,475 images, 50 common animals categories
standard 40/10 zero-shot split
85 class-level attributes
2)Caltech-UCSD Birds 200-2011 (CUB)
11,788 images, 200 different birds
a split of 150/50 for zero-shot learning
312 class-level attributes
论文参考:Discriminative Learning of Latent Features for Zero-Shot Recognition