Caffe源码解读(九):Caffe可视化工具
从网络结构可视化、caffemodel的可视化、特征图可视化、可视化loss和accurary曲线等四个方面讲可视化
网络结构可视化
有两种办法:draw_net.py工具和在线可视化工具,推荐后者,灵活简便。
1、使用draw_net.py工具
需要安装numpy、gfortran、graphviz、pydot等工具之后,才能执行draw_net.py。
sudo apt-get update
sudo apt-get install python-pip python-dev python-numpy
sudo apt-get install gfortran graphviz
sudo pip install -r ${CAFFE_ROOT}/python/erquirements.txt
sudo pip install pydot执行无参数的draw_net.py可以看到他支持的参数选项:
usage: draw_net.py [-h] [--rankdir RANKDIR] [--phase PHASE]
input_net_proto_file output_image_file–rankdir:表示图的方向,从上往下或者从左往右,默认从左往右
执行命令:
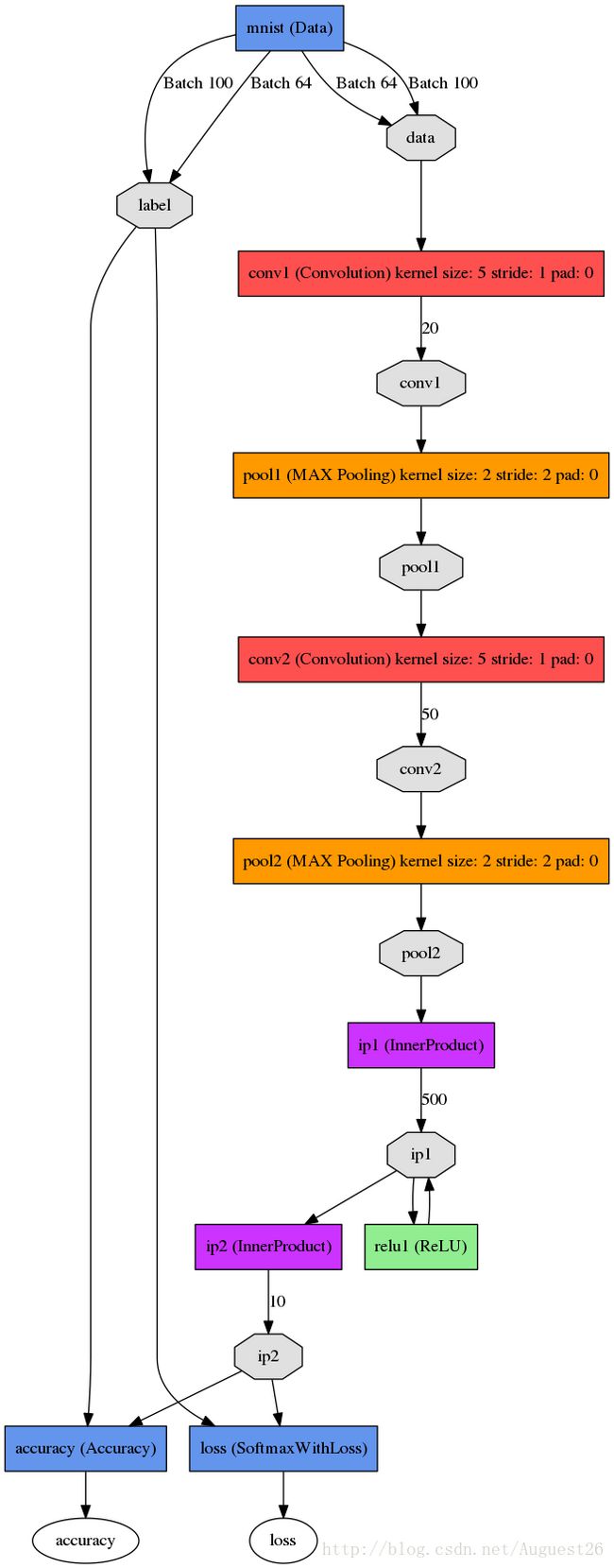
./draw_net.py --rankdir TB ./lenet_train_test.prototxt mnist.pngTB:是top和bottom的缩写,表示从上往下
执行结果保存在mnist.png,如图:
2、在线可视化工具
地址:http://ethereon.github.io/netscope/#/editor
操作简单,不赘述
caffemodel的可视化
对卷积层而言如果能够可视化,就能预先判断模型的好坏。卷积层的权值可视化代码如下:
# -*- coding: utf-8 -*-
# file:test_extract_weights.py
import numpy as np
import matplotlib.pyplot as plt
import os
import sys
import caffe
deploy_file = "./mnist_deploy.prototxt"
model_file = "./lenet_iter_10000.caffemodel"
#编写一个函数,用于显示各层的参数,padsize用于设置图片间隔空隙,padval用于调整亮度
def show_weight(data, padsize=1, padval=0):
#归一化
data -= data.min()
data /= data.max()
#根据data中图片数量data.shape[0],计算最后输出时每行每列图片数n
n = int(np.ceil(np.sqrt(data.shape[0])))
print "The number of pic in one line or collum:",n
# padding = ((图片个数维度的padding),(图片高的padding), (图片宽的padding), ....)
print "data.ndim:", data.ndim
padding = ((0, n ** 2 - data.shape[0]), (0, padsize), (0, padsize)) + ((0, 0),) * (data.ndim - 3)
print "padding:", padding
data = np.pad(data, padding, mode='constant', constant_values=(padval, padval))
print "data:", data
# 先将padding后的data分成n*n张图像
print "data.shape[1:]:", data.shape[1:]
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
print "data.shape:", data.shape
print "data.shape[4:]:", data.shape[4:]
# 再将(n, W, n, H)变换成(n*w, n*H)
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
print "data.shape:", data.shape
plt.set_cmap('gray')
plt.imshow(data)
plt.imsave("conv2.jpg",data)
plt.axis('off')
if __name__ == '__main__':
print "Print the caffe.Net:"
#初始化caffe
net = caffe.Net(deploy_file,model_file,caffe.TEST)
print "Print net.params.items:"
print [(k, v[0].data.shape) for k, v in net.params.items()]
#第一个卷积层,参数规模为(50,20,5,5),即50个5*5的1通道filter
weight = net.params["conv2"][0].data
print "Print weight.shape:"
print weight.shape
show_weight(weight.reshape(50*20,5,5)) # [!!!]参数取决于weight.shape特征图可视化
输入一张图片,能够看到它在每一层的效果:
# -*- coding: utf-8 -*-
# file:test_extract_weights.py
import numpy as np
import matplotlib.pyplot as plt
import os
import sys
import caffe
deploy_file = "./mnist_deploy.prototxt"
model_file = "./lenet_iter_10000.caffemodel"
test_data = "./5.jpg"
#编写一个函数,用于显示各层的参数,padsize用于设置图片间隔空隙,padval用于调整亮度
def show_data(data, padsize=1, padval=0):
#归一化
data -= data.min()
data /= data.max()
#根据data中图片数量data.shape[0],计算最后输出时每行每列图片数n
n = int(np.ceil(np.sqrt(data.shape[0])))
# padding = ((图片个数维度的padding),(图片高的padding), (图片宽的padding), ....)
padding = ((0, n ** 2 - data.shape[0]), (0, padsize), (0, padsize)) + ((0, 0),) * (data.ndim - 3)
data = np.pad(data, padding, mode='constant', constant_values=(padval, padval))
# 先将padding后的data分成n*n张图像
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
# 再将(n, W, n, H)变换成(n*w, n*H)
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
plt.set_cmap('gray')
plt.imshow(data)
plt.imsave("conv1_data.jpg",data)
plt.axis('off')
if __name__ == '__main__':
#如果是用了GPU
#caffe.set_mode_gpu()
#初始化caffe
net = caffe.Net(deploy_file, model_file, caffe.TEST)
#数据输入预处理
# 'data'对应于deploy文件:
# input: "data"
# input_dim: 1
# input_dim: 1
# input_dim: 28
# input_dim: 28
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
# python读取的图片文件格式为H×W×K,需转化为K×H×W
transformer.set_transpose('data', (2, 0, 1))
# python中将图片存储为[0, 1]
# 如果模型输入用的是0~255的原始格式,则需要做以下转换
# transformer.set_raw_scale('data', 255)
# caffe中图片是BGR格式,而原始格式是RGB,所以要转化
transformer.set_channel_swap('data', (2, 1, 0))
# 将输入图片格式转化为合适格式(与deploy文件相同)
net.blobs['data'].reshape(1, 3, 227, 227)
#读取图片
#参数color: True(default)是彩色图,False是灰度图
img = caffe.io.load_image(test_data)
# 数据输入、预处理
net.blobs['data'].data[...] = transformer.preprocess('data', img)
# 前向迭代,即分类
out = net.forward()
# 输出结果为各个可能分类的概率分布
predicts = out['prob']
print "Prob:"
print predicts
# 上述'prob'来源于deploy文件:
# layer {
# name: "prob"
# type: "Softmax"
# bottom: "ip2"
# top: "prob"
# }
#最可能分类
predict = predicts.argmax()
print "Result:"
print predict
#---------------------------- 显示特征图 -------------------------------
feature = net.blobs['conv1'].data
show_data(feature.reshape(96*3,217,217))可视化loss和accurary曲线
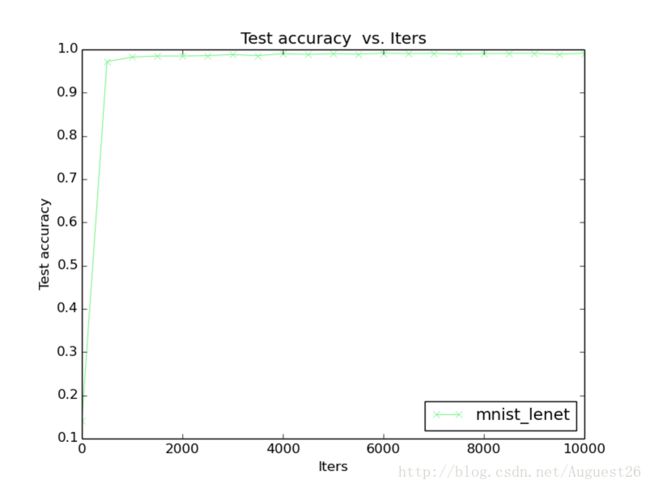
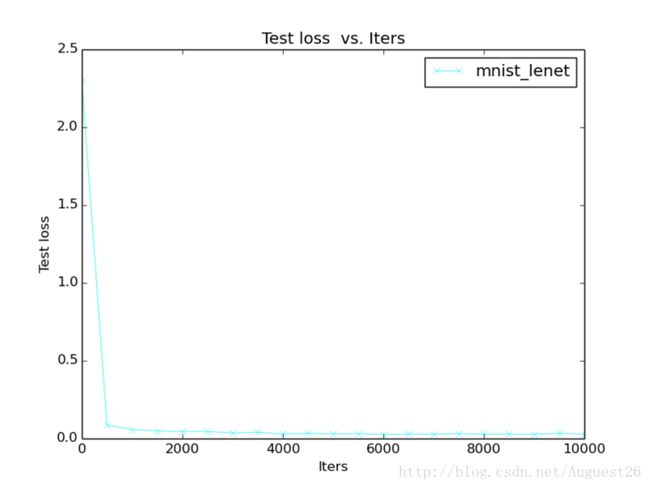
caffe提供了{caffe_root}/tools/extra/plot_training_log.py工具可视化loss和accurary曲线。plot_training_log.py的用法:
Usage:
./plot_training_log.py chart_type[0-7] /where/to/save.png /path/to/first.log ...
Notes:
1. Supporting multiple logs.
2. Log file name must end with the lower-cased ".log".
Supported chart types:
0: Test accuracy vs. Iters
1: Test accuracy vs. Seconds
2: Test loss vs. Iters
3: Test loss vs. Seconds
4: Train learning rate vs. Iters
5: Train learning rate vs. Seconds
6: Train loss vs. Iters
7: Train loss vs. Seconds/path/to/first.log:这里的log就是训练时打印在屏幕上的日志文件,保存在.log文件中。
效果图: