python机器学习及实践-第一章
- 癌症预测问题代码详解
- 读取文件
import pandas as pd
#pandas库有一个read_csv的函数 可以读取.csv文件
df_train=pd.read_csv('../Desktop/python/Datasets/Breast-Cancer/breast-cancer-train.csv')
df_test=pd.read_csv('../Desktop/python/Datasets/Breast-Cancer/breast-cancer-test.csv')
#地址两个注意:1./不是\2.按照jupyter来 不可以按照本机来
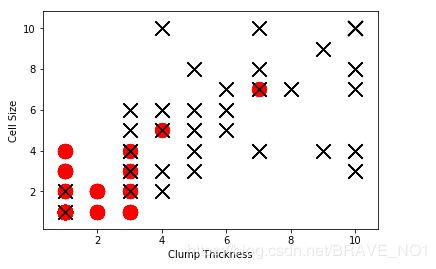
df_test_negtive=df_test.loc[df_test['Type']==0][['Clump Thickness','Cell Size']]
df_test_positive=df_test.loc[df_test['Type']==1][['Clump Thickness','Cell Size']]
#loc第一个参数可以使用布尔型作为下标,选择那些为True or False对应的值,第二个参数可以选择一些列
- 绘图
import matplotlib.pyplot as plt
plt.scatter(df_test_negtive['Clump Thickness'],df_test_negtive['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=200,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()
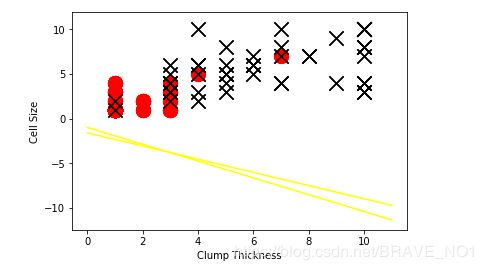
- 随机生成直线
intercept=np.random.random([1])#生成一个0-1之间的一维随机数
coef=np.random.random([2])#生成2个0-1之间的一维随机数
lx=np.arange(0,12)#lx是一个有0-12组成的元组
ly=(-intercept-lx*coef[0])/coef[1]#一个随机直线的表示
plt.plot(lx,ly,c='yellow')
plt.scatter(df_test_negtive['Clump Thickness'],df_test_negtive['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=200,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()
scatter与plot的区别:scatter绘制散点图,plot绘制经过点的直线。
- 逻辑回归分类(使用前10个小样本)
from sklearn.linear_model import LogisticRegression
lr=LogisticRegression()#使用sklearn线性回归模块的逻辑回归函数
lr.fit(df_train[['Clump Thickness','Cell Size']][:10],df_train['Type'][:10])
print('Testing accuracy(10 training samples):',lr.score(df_test[['Clump Thickness','Cell Size']],df_test['Type']))
intercept=lr.intercept_
coef=lr.coef_[0,:]
ly=(-intercept-lx*coef[0])/coef[1]
plt.plot(lx,ly,c='green')
plt.scatter(df_test_negtive['Clump Thickness'],df_test_negtive['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()
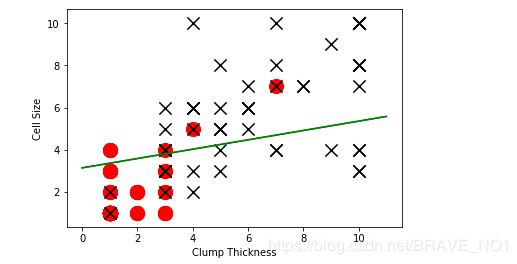
根据逻辑回归函数得到的截距,来调整分类直线。
- 逻辑回归分类(使用所有数据)
lr=LogisticRegression()
lr.fit(df_train[['Clump Thickness','Cell Size']],df_train['Type'])
print('Testing accuracy(all training samples):',lr.score(df_test[['Clump Thickness','Cell Size']],df_test['Type']))
intercept=lr.intercept_
coef=lr.coef_[0,:]
ly=(-intercept-lx*coef[0])/coef[1]
plt.plot(lx,ly,c='blue')#plot 和show的区别
plt.scatter(df_test_negtive['Clump Thickness'],df_test_negtive['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()
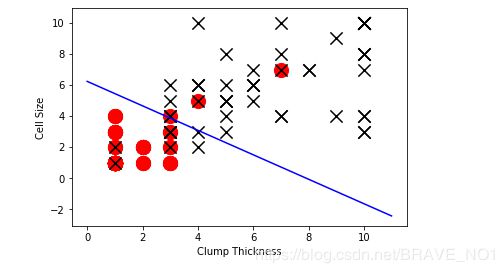
可以看出达到了较好的分类效果。
- python机器学习及实践的学习收获:
1.if代码块在命令行中,除了...之外,需要自己手动缩进。
2.python三大数据类型:元组,列表,字典。元组L=();列表L=[ ];字典L={key:value} 其中列表允许访问的时候进行修改,而元组一旦确定,无法修改。除此之外,in 针对元组,列表,字典中的key,不针对value。无论元组,列表,字典,下标访问都是用[]。
3.定义函数使用def。
4.sklearn库包含了回归、分类、聚类等函数。可以直接调用。