k近邻法(KNN)python 实现
有用请点赞,没用请差评。
欢迎分享本文,转载请保留出处。
KNN
关于knn的原理就不赘述了,算法原理可以参考李航博士的《统计学习方法》。
这次采用的是最简单的线性扫描方法来寻找k个最近邻点。但是这种方法面对很大的训练集时,计算会非常耗时,因此为了提高k近邻搜索的效率,可以考虑kd树方法。
距离度量采用的是欧式距离(euclidean distance)。
import numpy as np
import operator
def createDataset(trainfilename,testfilename):
"""
创建训练、测试数据集
"""
testdata,test_label=readfile(testfilename)
# print(testdata,"\n",test_label)
traindata,train_label=readfile(trainfilename)
# print(traindata)
return testdata,test_label,traindata,train_label
def readfile(filename):
"""
读取数据集
W:特征向量数组
label:标签(类别)列表
:param filename:
:return:特征向量数组和标签集合列表
"""
save_path="D:\\python3_anaconda3\\学习\机器学习\\机器学习数据集\\"
with open(save_path+filename,'r') as f:
#注意点A : f.readlines()
length=len(f.readlines())
print(filename,"length: %d"%length)
W = np.zeros((length,4))
label=[]
i=0
# 注意的是在A处用过一次f.readlines(),因此此时的文件读取指针已经到了文件的末尾,必须加上f.seek(0,0)将指针移到文件开头
f.seek(0,0)
for line in f.readlines():
linestr=line.strip()
linestrlist=line.split(',')
# print(linestrlist)
number_data=[float(j) for j in linestrlist[0:4]]
W[i,:]=np.array(number_data)
label.append(linestrlist[4].strip('\n'))
i+=1
return W,label
def knn_classify(trainfilename,testfilename,k):
testdata, test_label, traindata, train_label=createDataset(trainfilename,testfilename)
traindata_nums=traindata.shape[0]
testdata_nums=testdata.shape[0]
knn_classlabel=[]
for array in testdata: #循环每一个测试集
testdata_dup = np.tile(array, (traindata_nums, 1)) # tile(inX,(a,b))函数将inX重复a行,重复b列,用于对所有训练数据做矩阵运算
# print(testdata_dup)
# 计算欧式距离
distances=(testdata_dup-traindata)**2
euclidean_distance=(distances.sum(axis=1))**0.5 #sum(axis=1)每行所有元素相加
sortedDistIndicies= euclidean_distance.argsort() #argsort函数返回的是数组值从小到大的索引值
classCount = {}
for i in range(k):
voteIlabel = train_label[sortedDistIndicies[i]] # 取出前k个最小距离对应的标签
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 #Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
# print(classCount)
SortedclassCount= sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# reverse降序排列字典
# python2版本中的iteritems()换成python3的items()
# key=operator.itemgetter(1)按照字典的值(value)进行排序
# key=operator.itemgetter(0)按照字典的键(key)进行排序
print(SortedclassCount)
# 返回字典的第一条的key,也即是测试样本所属类别
knn_classlabel.append(SortedclassCount[0][0])
check(knn_classlabel,test_label,testdata_nums)
def check(knn_classlabel,test_label,testdata_nums):
"""
计算分类的准确度
"""
right_num=0
for i in range(testdata_nums):
if knn_classlabel[i]==test_label[i]:
right_num+=1
print("knn classify accuracy:%f"%(right_num/testdata_nums))
'''
函数功能: kNN(K近邻法)分类
采用UCI的数据集:鸢尾属植物数据库,Link:http://archive.ics.uci.edu/ml/machine-learning-databases/iris/
'''
if __name__ == '__main__':
trainfilename="iris.data" #训练集
testfilename="testiris.data" #测试集
# createDataset(trainfilename,testfilename)
#K值
k=10
knn_classify(trainfilename,testfilename,k)
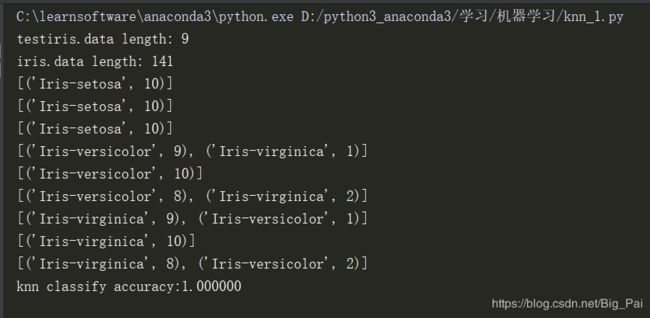
程序输出: