Hadoop本地模式、伪分布模式的安装
注:本例已经事先在root目录创建tools和training文件夹(分别用来存放工具安装包和工具安装目录)。另外也已经装好jdk环境。
1.将Hadoop安装包hadoop-2.7.3.tar.gz上传到 /root/training/tools 目录
2.将安装包解压到 /root/training/ 目录
tar -zxvf hadoop-2.7.3.tar.gz -C /root/training/

3.在 .bash_profile配置环境变量
①编辑vim /root/.bash_profile
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
②生效source /root/.bash_profile
4.配置Hadoop依赖
说明:
本地模式 一台Linux
特点:没有HDFS,只能测试MapReduce程序
伪分布模式 一台Linux
特点:在单机上模拟一个分布式环境,具备Hadoop所有功能
分布模式 三台Linux
特点:真正的分布式,用于生产
各模式需要配置的文件如下:

/*****************配置伪分布模式 start ****************/
步骤如下:
① vim etc/hadoop/hadoop-env.sh (注:本地模式仅需配置这个文件)

export JAVA_HOME=/root/training/jdk1.8.0_144
到此步骤,本地模式即可使用
② 测试mapreduce程序中的wordcount方法:
进入MapReduce的jar目录
cd /root/training/hadoop-2.7.3/share/hadoop/mapreduce
执行MapReduce程序的例子
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ~/temp/shenma2.txt ~/temp/myfn/wordcount
结果如下则执行成功
![]()
③ vim etc/hadoop/hdfs-site.xml

④ vim etc/hadoop/core-site.xml

⑤ vim etc/hadoop/mapred-site.xml

⑥vim etc/hadoop/yarn-site.xml
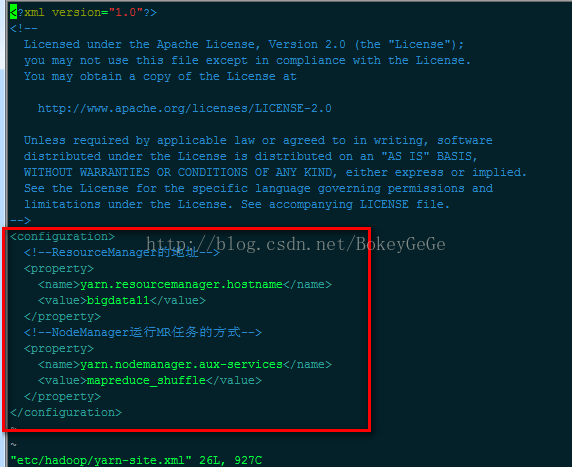
⑦ 对NameNode进行格式化: hdfs namenode -format
打印以下日志说明格式化成功:
Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted.
启动:
start-all.sh 启动集群
start-dfs.sh 启动HDFS
start-yarn.sh 启动Yarn
stop-all.sh 关闭
查看进程

/*****************配置伪分布模式 end ****************/
常见问题:启动集群后没有DataNode进程。
原因:多次格式化NameNode可能没看提示,输入Y,导致id重置,进而导致name和node的版本不一致。
解决:方案1,删除配置HDFS存放数据的tmp目录,重新格式化NameNode。
方案2,手动将版本修改一致。