【作者】
王栋:携程技术保障中心数据库专家,对数据库疑难问题的排查和数据库自动化智能化运维工具的开发有强烈的兴趣。
【问题描述】
最近碰到有台MySQL实例出现了MySQL服务短暂hang死,表现为瞬间的并发线程上升,连接数暴增。
排查Error Log文件中有page_cleaner超时的信息,引起我们的关注:
2019-08-24T23:47:09.361836+08:00 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 24915ms. The settings might not be optimal. (flushed=182 and evicted=0, during the time.)
2019-08-24T23:47:16.211740+08:00 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 4849ms. The settings might not be optimal. (flushed=240 and evicted=0, during the time.)
2019-08-24T23:47:23.362286+08:00 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 6151ms. The settings might not be optimal. (flushed=215 and evicted=0, during the time.)
【问题分析】
1、 error log中page_cleaner信息是如何产生的
通过源码storage/innobase/buf/buf0flu.cc可以看出,当满足curr_time > next_loop_time + 3000条件(大于4秒)时,会打印上面信息到error log中。next_loop_time为1000ms,即1秒钟做一次刷新页的操作。
if (ret_sleep == OS_SYNC_TIME_EXCEEDED) {
ulint curr_time = ut_time_ms();
if (curr_time > next_loop_time + 3000) {
if (warn_count == 0) {
ib::info() << "page_cleaner: 1000ms"
" intended loop took "
<< 1000 + curr_time
- next_loop_time
<< "ms. The settings might not"
" be optimal. (flushed="
<< n_flushed_last
<< " and evicted="
<< n_evicted
<< ", during the time.)";
if (warn_interval > 300) {
warn_interval = 600;
} else {
warn_interval *= 2;
}
warn_count = warn_interval;
} else {
--warn_count;
}
} else {
/* reset counter */
warn_interval = 1;
warn_count = 0;
}
next_loop_time = curr_time + 1000;
n_flushed_last = n_evicted = 0;
}
后半部分(flushed=182 and evicted=0, during the time.)日志,对应n_flushed_last和n_evicted两个变量,这两个变量来自于下面2个变量。
n_evicted += n_flushed_lru;
n_flushed_last += n_flushed_list;从源码注释中可以看出,n_flushed_lru表示从LRU list尾部刷新的页数,也就是日志中如evicted=0指标的所表示的值。
n_flushed_list:这个是从flush_list刷新列表中刷新的页数,也就是脏页数,日志中flushed=182的值。
/**
Wait until all flush requests are finished.
@param n_flushed_lru number of pages flushed from the end of the LRU list.
@param n_flushed_list number of pages flushed from the end of the
flush_list.
@return true if all flush_list flushing batch were success. */
static
bool
pc_wait_finished(
ulint* n_flushed_lru,
ulint* n_flushed_list)
从pc_wait_finished函数可以看出page_cleaner线程包含了LRU list和flush_list两部分刷新,而且需要等待两部分都完成刷新。
2、MySQL5.7.4引入了多线程page cleaner,但由于LRU列表刷新和脏页列表刷新仍然耦合在一起,在遇到高负载,或是热数据的buffer pool instance时,仍存在性能问题。
1) LRU List刷脏在先,Flush list的刷脏在后,但是是互斥的。也就是说在进Flush list刷脏的时候,LRU list不能继续去刷脏,必须等到下一个循环周期才能进行。
2) 另外一个问题是,刷脏的时候,page cleaner coodinator会等待所有的page cleaner线程完成之后才会继续响应刷脏请求。这带来的问题就是如果某个buffer pool instance比较热的话,page cleaner就不能及时进行响应。
Percona版本对LRU list刷脏做了很多优化。
3、分析问题实例的binlog日志,可以看到从2019-08-24 23:46:15到2019-08-24 23:47:25之间没有记录任何日志,说明这段时间内mysql服务无法正常处理请求,短暂hang住了
mysqlbinlog -vvv binlog --start-datetime='2019-08-24 23:46:15' --stop-datetime='2019-08-24 23:47:25'|less
从计数器指标可以看出期间并发线程积压,QPS处理能力下降,稍后MySQL服务恢复,积压的请求集中释放,导致并发连接进一步上升
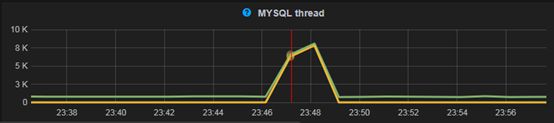
4、从Innodb_buffer_pool_pages_misc和Innodb_buffer_pool_pages_free指标来看,在问题时间段buffer pool在1分钟内集中释放了约16*(546893-310868)=3776400,3.7G可用内存。
可能期间LRU list的mutex资源锁定,导致page cleaner线程在LRU list刷新时阻塞,从而表现出page_cleaner线程执行时间过长。
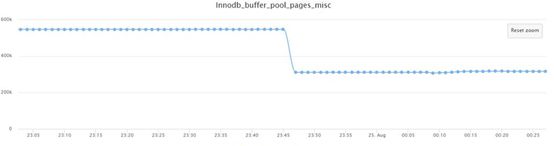
innodb_buffer_pool_pages_misc与adaptive hash index有关,下面是官网的描述
• Innodb_buffer_pool_pages_misc
The number of pages in the InnoDB buffer pool that are busy because they have been allocated for administrative overhead, such as row locks or the adaptive hash index. This value can also be calculated as Innodb_buffer_pool_pages_total − Innodb_buffer_pool_pages_free − Innodb_buffer_pool_pages_data. When using compressed tables, Innodb_buffer_pool_pages_misc may report an out-of-bounds value (Bug #59550).
5、为什么AHI短时间内会释放大量的内存呢,通过慢查询日志我们排查到期间有drop table的操作,但drop的表容量约50G,并不是很大,drop table为什么会导致MySQL服务短暂hang死,它对服务器性能会产生多大的影响,我们做了模拟测试。
【测试重现过程】
为了进一步验证,我们在测试环境下模拟测试了drop table对高并发MySQL性能的影响。
1、 使用sysbench工具做压测,首先在测试环境下创建了8张2亿条记录的表,单表容量48G
2、 开启innodb_adaptive_hash_index,用olap模板压测1个小时,填充目标8张表所对应的AHI内存
3、 再次开启压测线程只对sbtest1表做访问,观察MySQL的访问情况
4、 新建会话运行drop table test.sbtest2,看到drop一张48G的表消耗了64.84秒

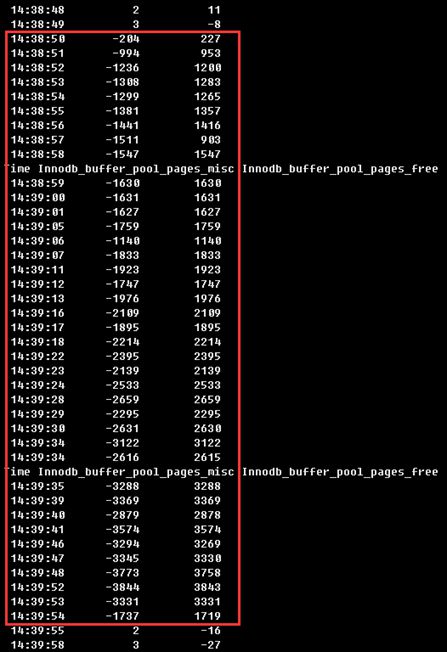
5、用自定义脚本检测每秒Innodb_buffer_pool_pages_misc和Innodb_buffer_pool_pages_free指标的变化情况,看到在drop table期间Innodb_buffer_pool_pages_misc大量释放,Innodb_buffer_pool_pages_free值同时增长,释放和增加的内容总量基本一致,如下图所示
6、drop table期间,MySQL处于hang死状态,QPS长时间跌0
7、errorlog中也重现了page_cleaner的日志信息
![]()
至此复现了问题现象。
【为什么MySQL会短暂hang死】
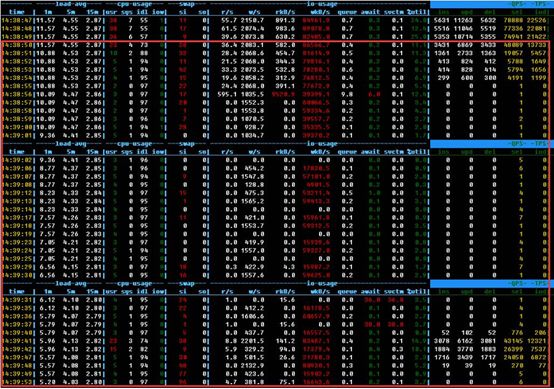
1、 压测期间,抓取了pstack,show engine innodb status,以及performance_schema下events_waits_summary_global_by_event_name表中相关mutex等现场信息
2、 在SEMAPHORES相关信息中,可以看到hang死期间大量Thread请求S-lock,被同一个线程140037411514112持有的锁所阻塞,时间持续了64秒
--Thread 140037475792640 has waited at row0purge.cc line 862 for 64.00 seconds the semaphore:
S-lock on RW-latch at 0x966f6e38 created in file dict0dict.cc line 1183
a writer (thread id 140037411514112) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0purge.cc line 862
Last time write locked in file /mysql-5.7.23/storage/innobase/row/row0mysql.cc line 4253
--Thread 140037563102976 has waited at srv0srv.cc line 1982 for 57.00 seconds the semaphore:
X-lock on RW-latch at 0x966f6e38 created in file dict0dict.cc line 1183
a writer (thread id 140037411514112) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0purge.cc line 862
Last time write locked in file /mysql-5.7.23/storage/innobase/row/row0mysql.cc line 4253
3、通过ROW OPERATIONS相关信息,可以看到MySQL的Main Thread也被同一个线程140037411514112阻塞,状态处于enforcing dict cache limit状态
3 queries inside InnoDB, 0 queries in queue
17 read views open inside InnoDB
Process ID=39257, Main thread ID=140037563102976, state: enforcing dict cache limit
Number of rows inserted 1870023456, updated 44052478, deleted 22022445, read 9301843315
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
4、可以看到线程140037411514112执行的SQL就是drop table test.sbtest2语句,说明drop table期间持有的锁,阻塞了Main Thread及其他线程
---TRANSACTION 44734025, ACTIVE 64 sec dropping table——
10 lock struct(s), heap size 1136, 7 row lock(s), undo log entries 1
MySQL thread id 440836, OS thread handle 140037411514112, query id 475074428 localhost root checking permissions
drop table test.sbtest25、下面是抓到的drop table 的简化后的调用栈信息,对比可以看出,64秒的时间,drop table 都在执行函数btr_search_drop_page_hash_index,清空对应的AHI记录信息
Thread 32 (Thread 0x7f5d002b2700 (LWP 8156)):
#0 ha_remove_all_nodes_to_page
#1 btr_search_drop_page_hash_index
#2 btr_search_drop_page_hash_when_freed
#3 fseg_free_extent
#4 fseg_free_step
#5 btr_free_but_not_root
#6 btr_free_if_exists
#7 dict_drop_index_tree
#8 row_upd_clust_step
#9 row_upd
#10 row_upd_step
#11 que_thr_step
#12 que_run_threads_low
#13 que_run_threads
#14 que_eval_sql
#15 row_drop_table_for_mysql
#16 ha_innobase::delete_table
#17 ha_delete_table
#18 mysql_rm_table_no_locks
#19 mysql_rm_table
#20 mysql_execute_command
#21 mysql_parse
#22 dispatch_command
#23 do_command
#24 handle_connection
#25 pfs_spawn_thread
#26 start_thread ()
#27 clone ()
6、通过代码我们可以看到drop table调用row_drop_table_for_mysql函数时,在row_mysql_lock_data_dictionary(trx);位置对元数据加了排它锁
row_drop_table_for_mysql(
const char* name,
trx_t* trx,
bool drop_db,
bool nonatomic,
dict_table_t* handler)
{
dberr_t err;
dict_foreign_t* foreign;
dict_table_t* table = NULL;
char* filepath = NULL;
char* tablename = NULL;
bool locked_dictionary = false;
pars_info_t* info = NULL;
mem_heap_t* heap = NULL;
bool is_intrinsic_temp_table = false;
DBUG_ENTER("row_drop_table_for_mysql");
DBUG_PRINT("row_drop_table_for_mysql", ("table: '%s'", name));
ut_a(name != NULL);
/* Serialize data dictionary operations with dictionary mutex:
no deadlocks can occur then in these operations /
trx->op_info = "dropping table";
if (handler != NULL && dict_table_is_intrinsic(handler)) {
table = handler;
is_intrinsic_temp_table = true;
}
if (table == NULL) {
if (trx->dict_operation_lock_mode != RW_X_LATCH) {
/ Prevent foreign key checks etc. while we are
dropping the table */
row_mysql_lock_data_dictionary(trx);
locked_dictionary = true;
nonatomic = true;
}7、以Main Thread为例,在调用srv_master_evict_from_table_cache函数获取X-lock on RW-latch时被阻塞
/********************************************************************//**
Make room in the table cache by evicting an unused table.
@return number of tables evicted. /
static
ulint
srv_master_evict_from_table_cache(
/==============================/
ulint pct_check) /!< in: max percent to check */
{
ulint n_tables_evicted = 0;
rw_lock_x_lock(dict_operation_lock);
dict_mutex_enter_for_mysql();
n_tables_evicted = dict_make_room_in_cache(
innobase_get_table_cache_size(), pct_check);
dict_mutex_exit_for_mysql();
rw_lock_x_unlock(dict_operation_lock);
return(n_tables_evicted);
}8、查看dict_operation_lock的注释,create drop table操作时需要X锁,而一些其他后台线程,比如Main Thread检查dict cache时,也需要获取dict_operation_lock的X锁,因此被阻塞
/** @brief the data dictionary rw-latch protecting dict_sys
table create, drop, etc. reserve this in X-mode; implicit or
backround operations purge, rollback, foreign key checks reserve this
in S-mode; we cannot trust that MySQL protects implicit or background
operations a table drop since MySQL does not know of them; therefore
we need this; NOTE: a transaction which reserves this must keep book
on the mode in trx_t::dict_operation_lock_mode /
rw_lock_t dict_operation_lock;
9、期间用户线程由于获取不到锁而处于挂起状态,当无法立刻获得锁时,会调用row_mysql_handle_errors将错误码传到上层进行处理
/****************************************************************//
Handles user errors and lock waits detected by the database engine.
@return true if it was a lock wait and we should continue running the
query thread and in that case the thr is ALREADY in the running state. /
bool
row_mysql_handle_errors下面是简化后的用户线程调用栈信息:
Thread 29 (Thread 0x7f5d001ef700 (LWP 8159)):
#0 pthread_cond_wait@@GLIBC_2.3.2
#1 wait
#2 os_event::wait_low
#3 os_event_wait_low
#4 lock_wait_suspend_thread
#5 row_mysql_handle_errors
#6 row_search_mvcc
#7 ha_innobase::index_read
#8 handler::ha_index_read_map
#9 handler::read_range_first
#10 handler::multi_range_read_next
#11 QUICK_RANGE_SELECT::get_next
#12 rr_quick
#13 mysql_update
#14 Sql_cmd_update::try_single_table_update
#15 Sql_cmd_update::execute
#16 mysql_execute_command
#17 mysql_parse
#18 dispatch_command
#19 do_command
#20 handle_connection
#21 pfs_spawn_thread
#22 start_thread
#23 clone10、page_cleaner后台线程没有抓到明显的阻塞关系,只看到如下正常的调用栈信息
Thread 55 (Thread 0x7f5c7fe15700 (LWP 39287)):
#0 pthread_cond_timedwait@@GLIBC_2.3.2 ()
#1 os_event::timed_wait
#2 os_event::wait_time_low
#3 os_event_wait_time_low
#4 pc_sleep_if_needed
#5 buf_flush_page_cleaner_coordinator
#6 start_thread
#7 clone
Thread 54 (Thread 0x7f5c7f614700 (LWP 39288)):
#0 pthread_cond_wait@@GLIBC_2.3.2 ()
#1 wait
#2 os_event::wait_low
#3 os_event_wait_low
#4 buf_flush_page_cleaner_worker
#5 start_thread
#6 clone【结论&解决思路】
drop table引起的MySQL 短暂hang死的问题,是由于drop 一张使用AHI空间较大的表时,调用执行AHI的清理动作,会消耗较长时间,执行期间长时间持有dict_operation_lock的X锁,阻塞了其他后台线程和用户线程;
drop table执行结束锁释放,MySQL积压的用户线程集中运行,出现了并发线程和连接数瞬间上升的现象。
规避问题的方法,可以考虑在drop table前关闭AHI。