【机器学习--实战篇】足球运动员身价估计---XGBoost
完整代码
练习入口
补充一个画图工具
xgboost与lightgbm比较, 我也要测一次
据说stacking得分会更高
https://blog.csdn.net/zhouwenyuan1015/article/details/77372863
首先说下总的mae:19.7
但是gridSearch的best_csore_并不高,是个负数,这一点我还没搞懂,希望网友帮解惑。
我敢提交是因为测试结果mae是20.XXX,觉得结果还不错。
-------------------------------------------------------------分割线-------------------------------------------------------
首先看下所有的特征介绍
| 特征 | 解释 | 类型 |
|---|---|---|
| id | 行编号 | 没有实际意义 |
| club | 该球员所属的俱乐部 | 该信息已经被编码 |
| league | 该球员所在的联赛 | 已被编码 |
| birth_date | 生日 | 格式为月/日/年 |
| height_cm | 身高(厘米) | 数值变量 |
| weight_kg | 体重(公斤) | 数值变量 |
| nationality | 国籍 | 已被编码 |
| potential | 球员的潜力 | 数值变量 |
| pac | 球员速度 | 数值变量 |
| sho | 射门(能力值) | 数值变量 |
| pas | 传球(能力值) | 数值变量 |
| dri | 带球(能力值) | 数值变量 |
| def | 防守(能力值) | 数值变量 |
| phy | 身体对抗(能力值) | 数值变量 |
| international_reputation | 国际知名度 | 数值变量 |
| skill_moves | 技巧动作 | 数值变量 |
| weak_foot | 非惯用脚的能力值 | 数值变量 |
| work_rate_att | 球员进攻的倾向 | 分类变量,Low,Medium,High |
| work_rate_def | 球员防守的倾向 | 分类变量,Low,Medium,High |
| preferred_foot | 惯用脚 | 1表示右脚、2表示左脚 |
| crossing | 传中(能力值) | 数值变量 |
| finishing | 完成射门(能力值) | 数值变量 |
| heading_accuracy | 头球精度(能力值) | 数值变量 |
| short_passing | 短传(能力值) | 数值变量 |
| volleys | 凌空球(能力值) | 数值变量 |
| dribbling | 盘带(能力值) | 数值变量 |
| curve | 弧线(能力值) | 数值变量 |
| free_kick_accuracy | 定位球精度(能力值) | 数值变量 |
| long_passing | 长传(能力值) | 数值变量 |
| ball_control | 控球(能力值) | 数值变量 |
| acceleration | 加速度(能力值) | 数值变量 |
| sprint_speed | 冲刺速度(能力值) | 数值变量 |
| agility | 灵活性(能力值) | 数值变量 |
| reactions | 反应(能力值) | 数值变量 |
| balance | 身体协调(能力值) | 数值变量 |
| shot_power | 射门力量(能力值) | 数值变量 |
| jumping | 弹跳(能力值) | 数值变量 |
| stamina | 体能(能力值) | 数值变量 |
| strength | 力量(能力值) | 数值变量 |
| long_shots | 远射(能力值) | 数值变量 |
| aggression | 侵略性(能力值) | 数值变量 |
| interceptions | 拦截(能力值) | 数值变量 |
| positioning | 位置感(能力值) | 数值变量 |
| vision | 视野(能力值) | 数值变量 |
| penalties | 罚点球(能力值) | 数值变量 |
| marking | 卡位(能力值) | 数值变量 |
| standing_tackle | 断球(能力值) | 数值变量 |
| sliding_tackle | 铲球(能力值) | 数值变量 |
| gk_diving | 门将扑救(能力值) | 数值变量 |
| gk_handling | 门将控球(能力值) | 数值变量 |
| gk_kicking | 门将开球(能力值) | 数值变量 |
| gk_positioning | 门将位置感(能力值) | 数值变量 |
| gk_reflexes | 门将反应(能力值) | 数值变量 |
| rw | 球员在右边锋位置的能力值 | 数值变量 |
| rb | 球员在右后卫位置的能力值 | 数值变量 |
| st | 球员在射手位置的能力值 | 数值变量 |
| lw | 球员在左边锋位置的能力值 | 数值变量 |
| cf | 球员在锋线位置的能力值 | 数值变量 |
| cam | 球员在前腰位置的能力值 | 数值变量 |
| cm | 球员在中场位置的能力值 | 数值变量 |
| cdm | 球员在后腰位置的能力值 | 数值变量 |
| cb | 球员在中后卫的能力值 | 数值变量 |
| lb | 球员在左后卫置的能力值 | 数值变量 |
| gk | 球员在守门员的能力值 | 数值变量 |
| y | 该球员的市场价值(单位为万欧元) | 这是要被预测的数值 |
1、预处理
| 函数 | 功能 |
|---|---|
| full_birthDate | 原表中的年份数据是2位,比如格式是这样的,09/10/89,因为计算年龄,所以补为完整的09/10/1989 |
| trans | 把csv中的非数值字符换为数值 |
| judge | csv中有一些数据是空的,需要去除空数据 |
def full_birthDate(x):
if(x[-2:] == '00'):
return x[:-2]+'20'+x[-2:]
else:
return x[:-2]+'19'+x[-2:]
def trans(x):
if(x == 'Medium'):
return 1
elif(x == 'High'):
return 2
else:
return 0
def judge(x):
if(x > 0):
return 1
else:
return 0
2、读取数据,并新增初步的特征
增加的特征有:age、BMI、is_gk
这部分是看网站的标杆做的,自己本身没研究更多的特征工程
# 读取数据
def getData():
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/test.csv')
train['birth_date_'] = train['birth_date'].apply(lambda x: full_birthDate(x))
test['birth_date_'] = test['birth_date'].apply(lambda x: full_birthDate(x))
train['birth_date'] = pd.to_datetime(train['birth_date_'])
train['age'] = ((pd.Timestamp.now() - train['birth_date']).apply(lambda x: x.days) / 365).apply(lambda t: int(t))
test['birth_date'] = pd.to_datetime(test['birth_date_'],format='%m/%d/%Y', errors='coerce')
test['age'] = ((pd.Timestamp.now() - test['birth_date']).apply(lambda x: x.days) / 365).apply(lambda t: int(t))
train['work_rate_att_'] = train['work_rate_att'].apply(lambda x: trans(x)).apply(lambda t: int(t))
train['work_rate_def_'] = train['work_rate_def'].apply(lambda x: trans(x)).apply(lambda t: int(t))
test['work_rate_att_'] = test['work_rate_att'].apply(lambda x: trans(x)).apply(lambda t: int(t))
test['work_rate_def_'] = test['work_rate_def'].apply(lambda x: trans(x)).apply(lambda t: int(t))
train = train.drop('id',axis=1)
train = train.drop('birth_date',axis=1)
train = train.drop('birth_date_',axis=1)
train = train.drop('work_rate_att',axis=1)
train = train.drop('work_rate_def',axis=1)
test = test.drop('id',axis=1)
test = test.drop('birth_date',axis=1)
test = test.drop('birth_date_',axis=1)
test = test.drop('work_rate_att',axis=1)
test = test.drop('work_rate_def',axis=1)
return train,test
3、数据分析
新增一个特征:best_pos(最佳位置)是通过对[‘rw’, ‘rb’, ‘st’, ‘lw’, ‘cf’, ‘cam’, ‘cm’, ‘cdm’, ‘cb’, ‘lb’, ‘gk’]这11个特征的汇总。
| 特征 | 解释 | 类型 |
|---|---|---|
| rw | 球员在右边锋位置的能力值 | 数值变量 |
| rb | 球员在右后卫位置的能力值 | 数值变量 |
| st | 球员在射手位置的能力值 | 数值变量 |
| lw | 球员在左边锋位置的能力值 | 数值变量 |
| cf | 球员在锋线位置的能力值 | 数值变量 |
| cam | 球员在前腰位置的能力值 | 数值变量 |
| cm | 球员在中场位置的能力值 | 数值变量 |
| cdm | 球员在后腰位置的能力值 | 数值变量 |
| cb | 球员在中后卫的能力值 | 数值变量 |
| lb | 球员在左后卫置的能力值 | 数值变量 |
| gk | 球员在守门员的能力值 | 数值变量 |
盒图是用来观测离群点的,目前还没用到,等下一步用到在更新…
def data_ana(train, test):
# 获得球员最擅长位置上的评分
positions = ['rw', 'rb', 'st', 'lw', 'cf', 'cam', 'cm', 'cdm', 'cb', 'lb', 'gk']
train['best_pos'] = train[positions].max(axis=1)
test['best_pos'] = test[positions].max(axis=1)
# 计算球员的身体质量指数(BMI)
train['BMI'] = 10000. * train['weight_kg'] / (train['height_cm'] ** 2)
test['BMI'] = 10000. * test['weight_kg'] / (test['height_cm'] ** 2)
# 判断一个球员是否是守门员
train['is_gk'] = train['gk'].apply(lambda x: judge(x))
test['is_gk'] = test['gk'].apply(lambda x: judge(x))
return train,test
def view_filter(train):
# 可视化盒图
# # 统计输出信息
percentile_result = np.percentile(train['y'], [25, 50, 75])
num = 0
for i in list(train['y']):
if(i > percentile_result[2] * 1.5):
num+=1
print(i)
# print('离群点个数:',num,'\n四分位数Q3:',percentile_result[2])
# print(num/len(list(train['y'])))
# 显示图例
plt.boxplot(x=train['y'],showmeans=True,meanline=True,whis=1.5)
plt.legend()
savefig('盒图.jpg')
# 显示图形
plt.show()
plt.close()
4、训练
4.1 特征选择
注意n_estimators一定初始化大一点,因为会自动在收敛的地方自己停 选择特征,顺便确定n_estimators
def xgboost_select_feature(data_, labels_,cols,target):# # 特征选择
xgb1 = XGBRegressor(learning_rate =0.1,max_depth=5,min_child_weight=1,n_estimators=1000,
gamma=0,subsample=0.8,colsample_bytree=0.8,objective= 'reg:logistic',
nthread=4,scale_pos_weight=1,seed=27)
feature_ = list(modelfit(xgb1, data_.values,labels_.values,cols,target)) # 特征选择
return feature_
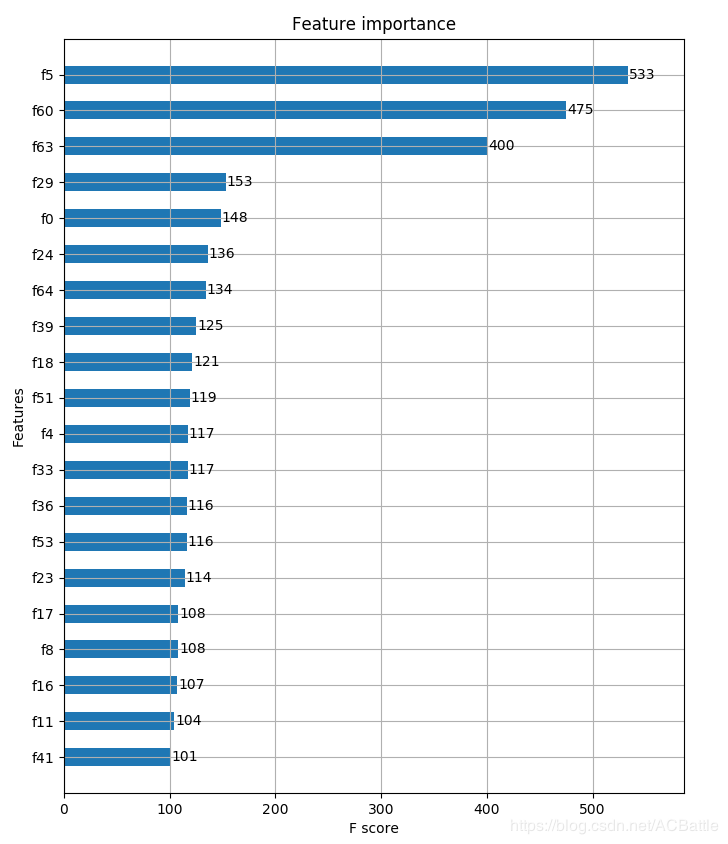
def modelfit(alg, data, labels_, cols, target, useTrainCV=True, cv_folds=7, early_stopping_rounds=50):
# 可以返回n_estimates的最佳数目,为什么呢, 哪里返回?
if useTrainCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(data, label=labels_)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
metrics='mae', early_stopping_rounds=early_stopping_rounds)
alg.set_params(n_estimators=cvresult.shape[0])
#Fit the algorithm on the data
seed = 20
# seed=20从0.97升为了0.98
# Model Report
# r2_score : 0.9845
# MAE: 0.4723899992310908 %
test_size = 0.3
x_train,x_test,y_train,y_test = train_test_split(data, labels_, test_size=test_size,random_state=seed)
print(x_train.shape[1],y_train.shape[1])
eval_set = [(x_test,y_test)]
alg.fit(x_train, y_train, early_stopping_rounds=early_stopping_rounds, eval_metric='mae',eval_set=eval_set,verbose=True)
#Predict training set:
dtrain_predictions = alg.predict(x_test)
# print(type(dtrain_predictions),type(labels_))
y_true = list(y_test)
y_pred = list(dtrain_predictions)
print(type(y_pred),type(y_true))
#Print model report:
print("\nModel Report")
print("r2_score : %.4g" % metrics.r2_score(y_true, y_pred))
mae_y = 0.00
for i in range(len(y_true)):
mae_y += np.abs(np.float(y_true[i])-y_pred[i])
print("MAE: ", (mae_y*4799+6)/len(y_true))
# Model Report
# r2_score : 0.9673
# MAE: 0.636517748270864 %
feat_imp = pd.Series(alg.get_booster().get_fscore()).sort_values(ascending=False)
# feat_imp.plot(kind='bar', title='Feature Importances')
# plt.ylabel('Feature Importance Score')
fig, ax = plt.subplots(1, 1, figsize=(8, 13))
plot_importance(alg, max_num_features=25, height=0.5, ax=ax)
plt.show()
# 重要性筛选
feat_sel = list(feat_imp.index)
feat_val = list(feat_imp.values)
featur = []
for i in range(len(feat_sel)):
featur.append([cols[int(feat_sel[i][1:])],feat_val[i]])
print('所有特征的score:\n',featur)
feat_sel2 = list(feat_imp[feat_imp.values > target].index)
featur2 = []
for i in range(len(feat_sel2)):
featur2.append(cols[int(feat_sel2[i][1:])])
return featur2
def MAE_(xgb1,train_x,train_y):
y_pre = list(xgb1.predict(train_x))
train_y = train_y.as_matrix()
num = 0
for i in range(len(y_pre)):
num += np.abs(y_pre[i] - train_y[i])
print((num*4799+6)/len(y_pre))
4.2训练
根据上一步获得特征排序,选择前11个作为训练的特征,选择好特征,就可以进行训练了。
def xgboost_train(train_x, train_y):
# # 半手动调参-------------------是个过程------调参成功需要注释掉---------------------------------------------------
# param_test1 = {
# 'max_depth':range(22,27)
# }
# gsearch1 = GridSearchCV(estimator = XGBRegressor(learning_rate=0.1, n_estimators=366, min_child_weight=1,subsample=0.85,colsample_bytree=0.8,
# gamma=0,objective= 'reg:logistic', nthread=4, seed=27),
# param_grid = param_test1,scoring='neg_median_absolute_error',n_jobs=4, iid=False, cv=5)
#gsearch1.fit(train_x,train_y)
# print(gsearch1.best_params_,gsearch1.best_score_)
# 半手动调参---结果太差了-----------------------------------------------------------------------------------------
# 20个特征,mae=19
# {'max_depth': 19} -0.000962098801735801
# {'max_depth': 20} -0.0009953797204438424
# {'max_depth': 24} -0.0009504750202941337
# 15个特征
# {'max_depth': 25} -0.0010135409208229943
# 24个特征
# {'max_depth': 18} -0.0009839476411412358
# 22个特征 结果不如19,mae=20
# {'max_depth': 23} -0.0009574992929236896
# 虽然是负数,最后的mae还是可以的19
train_x = train_x.as_matrix()
xgb1 = XGBRegressor(learning_rate=0.1, n_estimators=366, max_depth=23, min_child_weight=1,subsample=0.8,colsample_bytree=0.8,
gamma=0,objective= 'reg:logistic', nthread=4, scale_pos_weight=1, seed=27)
xgb1.fit(train_x,train_y)
MAE_(xgb1,train_x,train_y)
return xgb1