创新实训日记二:通过tensorflow利用cnn对视线数据集进行训练
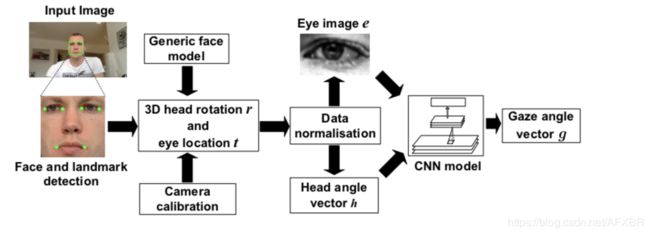
本周的主要任务是利用cnn完成视线追踪模型的初步训练,根据论文Appearance-Based Gaze Estimation in the Wild中的实现方法(如下图),我们本周在未进行图像处理的前提下,通过将眼部图像直接喂入cnn进行了初步的训练。
from scipy.io import loadmat
from math import *
import numpy as np
def getdata(filename):
m=loadmat(filename)
gaze=m['data'][0][0][0][0][0][0]
image=m['data'][0][0][0][0][0][1]
gaze2=[]
for i in range(len(gaze)):
theta=asin(-gaze[i][1])
phi=atan2(-gaze[i][0],-gaze[i][2])
gaze2.append([theta,phi])
return np.array(gaze2),image
训练使用的cnn代码如下,两层卷积和两层最大池化,全连接层为两层,第一层全连接层有1024个节点,损失函数为均方误差,学习率为1e-4
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
""" @author: vali """
# coding:utf8
import tensorflow as tf
import numpy as np
import readMat as rm
def weight_variable(shape):
''' 使用卷积神经网络会有很多权重和偏置需要创建,我们可以定义初始化函数便于重复使用 这里我们给权重制造一些随机噪声避免完全对称,使用截断的正态分布噪声,标准差为0.1 :param shape: 需要创建的权重Shape :return: 权重Tensor '''
initial = tf.random_normal(shape,stddev=0.01)
return tf.Variable(initial)
def bias_variable(shape):
''' 偏置生成函数,因为激活函数使用的是ReLU,我们给偏置增加一些小的正值(0.1)避免死亡节点(dead neurons) :param shape: :return: '''
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
''' 卷积层接下来要重复使用,tf.nn.conv2d是Tensorflow中的二维卷积函数, :param x: 输入 例如[5, 5, 1, 32]代表 卷积核尺寸为5x5,1个通道,32个不同卷积核 :param W: 卷积的参数 strides:代表卷积模板移动的步长,都是1代表不遗漏的划过图片的每一个点. padding:代表边界处理方式,SAME代表输入输出同尺寸 :return: '''
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME")
def max_pool_2x2(x):
''' tf.nn.max_pool是TensorFLow中最大池化函数.我们使用2x2最大池化 因为希望整体上缩小图片尺寸,因而池化层的strides设为横竖两个方向为2步长 :param x: :return: '''
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
def train(data,label,test_data,test_label):
# 使用占位符
x = tf.placeholder(tf.float32, [None, 36,60],'x')# x为特征
y_ = tf.placeholder(tf.float32, [None,2],'y')# y_为label
# 卷积中将1x2160转换为36x60x1 [-1,,,]代表样本数量不变 [,,,1]代表通道数
x_image = tf.reshape(x, [-1, 36, 60, 1])
# 第一个卷积层 [5, 5, 1, 32]代表 卷积核尺寸为5x5,1个通道,32个不同卷积核
# 创建滤波器权值-->加偏置-->卷积-->池化
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1)+b_conv1) #36x60x1 与32个5x5x1滤波器 --> 36x60x32
h_pool1 = max_pool_2x2(h_conv1) # 36x60x32 -->18x30x32
# 第二层卷积层 卷积核依旧是5x5 通道为32 有64个不同的卷积核
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) #18x30x32 与64个5x5x32滤波器 --> 18x30x64
h_pool2 = max_pool_2x2(h_conv2) #18x30x64 --> 9x15x64
# h_pool2的大小为7x7x64 转为1-D 然后做FC层
W_fc1 = weight_variable([9*15*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 9*15*64]) #9x15x64 --> 1x8640
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) #FC层传播 8640 --> 1024
# 使用Dropout层减轻过拟合,通过一个placeholder传入keep_prob比率控制
# 在训练中,我们随机丢弃一部分节点的数据来减轻过拟合,预测时则保留全部数据追求最佳性能
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 将Dropout层的输出连接到一个Softmax层,得到最后的概率输出
W_fc2 = weight_variable([1024, 2]) #2种输出可能
b_fc2 = bias_variable([2])
y_conv = (tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 定义损失函数,使用均方误差 同时定义优化器 learning rate = 1e-4
cross_entropy = tf.reduce_mean(tf.abs((y_conv-y_)))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 定义评测准确率
#accuracy = (1-tf.abs(tf.abs(y_conv[0][0]-y_[0])/y_[0]))*(1-tf.abs(tf.abs(y_conv[0][1]-y_[1])/y_[1]))
accuracy = y_conv
#开始训练
with tf.Session() as sess:
init_op = tf.global_variables_initializer() #初始化所有变量
sess.run(init_op)
STEPS = 100
for i in range(STEPS):
#batch = 5
batch_x = [data[i*5]]
batch_y = [label[i*5]]
for j in range(1,5):
batch_x = np.vstack((batch_x,[data[5*i+j]]))
batch_y = np.vstack((batch_y,[label[5*i+j]]))
if i % 2 == 0:
#train_accuracy = sess.run(accuracy, feed_dict={x:batch_x , y_:batch_y, keep_prob: 1.0})
train_cross_entropy= sess.run(cross_entropy,feed_dict={x:batch_x , y_:batch_y, keep_prob: 1.0})
print(i,train_cross_entropy)
sess.run(train_step, feed_dict={x: batch_x, y_: batch_y, keep_prob: 0.5})
#test
for i in range(10):
#batch = 5
batch_x = [test_data[5*i]]
batch_y = [test_label[5*i]]
for j in range(1,5):
batch_x = np.vstack((batch_x,[test_data[5*i+j]]))
batch_y = np.vstack((batch_y,[test_label[5*i+j]]))
#train_accuracy = sess.run(accuracy, feed_dict={x:batch_x , y_:batch_y, keep_prob: 1.0})
res= sess.run(y_conv,feed_dict={x:batch_x , y_:batch_y, keep_prob: 1.0})
loss = res - batch_y
count = 0
len = 0
for k in loss:
if(abs(k[0])<0.1 and abs(k[1])<0.1):
count+=1
len+=1
print(i,count/len)
if __name__=="__main__":
label,data = rm.getdata('day01.mat')
test_label,test_data=rm.getdata('day02.mat')
print(data.shape)
train(data,label,test_data,test_label)

效果并不是很好,原因猜测主要有以下几点:
- 只采用了一只眼睛进行训练
- 训练轮数太少只有100轮
- 损失函数需要改进
- 模型结构或参数需要调整