本文在个人技术博客不同步发布,详情可用力戳
亦可扫描屏幕右侧二维码关注个人公众号,公众号内有个人联系方式,等你来撩...
前两天发了工资,第一反应是想着要给远方的女朋友一点惊喜!于是打开了平安银行的APP给女朋友转点钱!填写上对方招商银行卡的卡号、开户名,一键转账!搞定!在我点击的那瞬间,就收到了app的账户变动的提醒,并且出现了图一所示的提示界面:“处理中,正在等待对方银行返回结果…”。嗯!毕竟是跨行转账嘛,等个几秒也正常!脑海开始浮现出女朋友收到转账后惊喜与感动的画面!
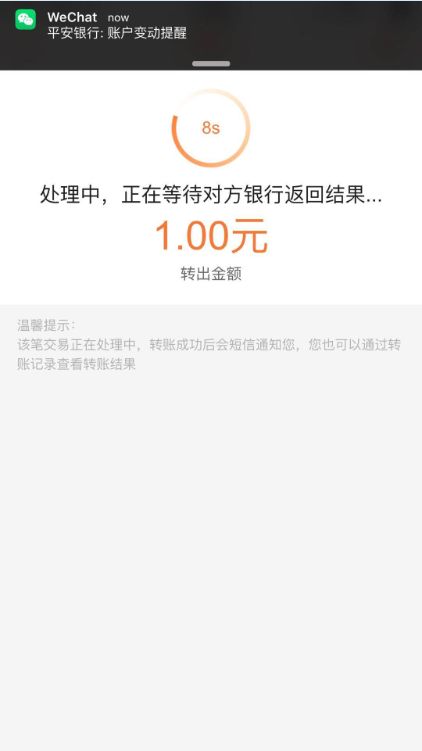
然而,一切并没有那么顺利,刚过一会儿,app却如图二所示的提示我“由于收款人户名不符”导致转账失败!!!
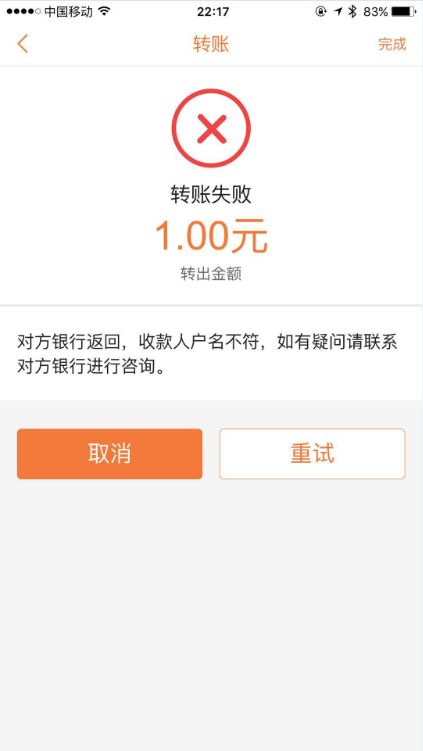
刚刚都已经从我卡里扣过钱了,现在却提示我转账失败,银行会不会把我的钱给吞了?转账失败的钱还能退换给我吗?正在我紧张、焦虑、坐立不安之时又收到一条app冲正的消息,刚刚转账失败的钱已经退还给我了,看来我多虑了……这也证明咱平安银行的app还是比较安全靠谱的!
为啥从我卡里扣钱那么迅速,而对方却要几秒才能到账?并且转账失败后,扣除的钱还能及时的返还到我的卡里?万一钱返还失败怎么办?又或者我转一次钱,对方却收到了两次转账的申请又该如何?带着这些问题,我脑海中浮现出“事务”二字!
在我们还在“牙牙学语”的时候,老师经常会通过转账的栗子来跟我们讲解事务,但跟这里场景不一样的是,老师讲的是本地事务,而这里面对的是分布式事务!我们先来简单回顾一下本地事务!
本地事务
谈到本地事务,大家可能都很熟悉,因为这个数据库引擎层面能支持的!所以也称数据库事务,数据库事务四大特征:原子性(A),一致性(C),隔离性(I)和持久性(D),而在这四大特性中,我认为一致性是最基本的特性,其它的三个特性都为了保证一致性而存在的!
回到学生时代老师给我们举的经典栗子,A账户给B账户转账100元(A、B处于同一个库中),如果A的账户发生扣款,B的账户却没有到账,这就出现了数据的不一致!为了保证数据的一致性,数据库的事务机制会让A账户扣款和B在账户到账的两个操作要么同时成功,如果有一个操作失败,则多个操作同时回滚,这就是事务的原子性,为了保证事务操作的原子性,就必须实现基于日志的REDO/UNDO机制!但是,仅有原子性还不够,因为我们的系统是运行在多线程环境下,如果多个事务并行,即使保证了每一个事务的原子性,仍然会出现数据不一致的情况。例如A账户原来有200元的余额, A账户给B账户转账100元,先读取A账户的余额,然后在这个值上减去100元,但是在这两个操作之间,A账户又给C账户转账100元,那么最后的结果应该是A减去了200元。但事实上,A账户给B账户最终完成转账后,A账户只减掉了100元,因为A账户向C账户转账减掉的100元被覆盖了!所以为了保证并发情况下的一致性,又引入的隔离性,即多个事务并发执行后的状态,和它们串行执行后的状态是等价的!隔离性又有多种隔离级别,为了实现隔离性(最终都是为了保证一致性)数据库又引入了悲观锁、乐观锁等等……本文的主题是分布式事务,所以本地事务就只是简单回顾一下,需要记住的一点是,事务是为了保证数据的一致性!
分布式理论
还记得刚毕业那年,带着满腔的热血就去到了一家互联网公司,领导给我的第一个任务就是在列表上增加一个修改数据的功能。这能难倒我?我分分钟给你搞出来!不就是在列表上增加了一个“修改”按钮,点击按钮弹出框修改后保存就好了么。然而一切不像我想象的那么顺利,点击保存并刷新列表后,页面上的数据还是显示的修改之前的内容,像没有修改成功一样!过一会儿再刷新列表,数据就能正常显示了!测试多次之后都是这样!没见过什么大场面的我开始有点慌了,是我哪里写得不对么?最终,我不得不求助组内经验比较丰富的前辈!他深吸了一口气告诉我说:“毕竟是刚毕业的小伙子啊!我来跟你讲讲原因吧!我们的数据库是做了读写分离的,部分读库与写库在不同的网络分区。你的数据更新到了写库,而读数据的时候是从读库读取的。更新到写库的数据同步到读库是有一定的延迟的,也就是说读库与写库会有短暂的数据不一致”! “这样不会体验不好么?为什么不能做到写入的数据立马能读出来?那我这个功能该怎么实现呢?” 面对我的一堆问题,同事有些不耐烦的说:“听说过CAP理论吗?你先自己去了解一下吧”!是我开始查阅各种资料去了解这个陌生的词背后的秘密!
CAP理论是由加州大学Eric Brewer教授提出来的,这个理论告诉我们,一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)这三个基本需求,最多只能同时满足其中两项。
一致性:这里的一致性是指数据的强一致,也称为线性一致性。是指在分布式环境中,数据在多个副本之间是否能够保持一致的特性。也就是说对某个数据进行写操作后立马执行读操作,必须能读取到刚刚写入的值。(any read operation that begins after a write operation completes must return that value, or the result of a later write operation)
可用性:任意被无故障节点接收到的请求,必须能够在有限的时间内响应结果。(every request received by a non-failing node in the system must result in a response)
分区容错性:如果集群中的机器被分成了两部分,这两部分不能互相通信,系统是否能继续正常工作。(the network will be allowed to lose arbitrarily many messages sent from one node to another)
在分布式系统中,分区容错性是基本要保证的。也就是说只能在一致性和可用性之间进行取舍。一致性和可用性,为什么不可能同时成立?回到之前修改列表的例子,由于数据会分布在不同的网络分区,必然会存在数据同步的问题,而同步会存在网络延迟、异常等问题,所以会出现数据的不一致!如果要保证数据的一致性,那么就必须在对写库进行操作时,锁定其他读库的操作。只有写入成功且完成数据同步后,才能重新放开读写,而这样在锁定期间,系统丧失了可用性。更详细关于CAP理论可以参考这篇文章,该文章讲得比较通俗易懂!
分布式事务
分布式事务就是在分布式的场景下,需要满足事务的需求!上篇文章我们聊过了消息中间件,那这篇文章我们要聊的是分布式事务,把两者一结合,便有了基于消息中间件的分布式事务解决方案!不管是本地事务,还是分布式事务,都是为了解决数据的一致性问题!一致性这个词咱们前面多次提及!与本地事务不同的是,分布式事务需要保证的是分布式环境下,不同数据库表中的数据的一致性问题。分布式事务的解决方案有多种,如XA协议、TCC三阶段提交、基于消息队列等等,本文只会涉及基于消息队列的解决方案!
本地事务讲到了一致性,分布式事务不可避免的面临着一致性的问题!回到最开始跨行转账的例子,如果A银行用户向B银行用户转账,正常流程应该是:
1、A银行对转出账户执行检查校验,进行金额扣减。
2、A银行同步调用B银行转账接口。
3、B银行对转入账户进行检查校验,进行金额增加。
4、B银行返回处理结果给A银行。

在正常情况对一致性要求不高的场景,这样的设计是可以满足需求的。但是像银行这样的系统,如果这样实现大概早就破产了吧。我们先看看这样的设计最主要的问题:
1、同步调用远程接口,如果接口比较耗时,会导致主线程阻塞时间较长。
2、流量不能很好控制,A银行系统的流量高峰可能压垮B银行系统(当然B银行肯定会有自己的限流机制)。
3、如果“第1步”刚执行完,系统由于某种原因宕机了,那会导致A银行账户扣款了,但是B银行没有收到接口的调用,这就出现了两个系统数据的不一致。
4、如果在执行“第3步”后,B银行由于某种原因宕机了而无法正确回应请求(实际上转账操作在B银行系统已经执行且入库),这时候A银行等待接口响应会异常,误以为转账失败而回滚“第1步”操作,这也会出现了两个系统数据的不一致。
对于问题的1、2都很好解决,如果对消息队列熟悉的朋友应该很快能想到可以引入消息中间件进行异步和削峰处理,于是又重新设计了一个方案,流程如下:
1、A银行对账户进行检查校验,进行金额扣减。
2、将对B银行的请求异步写入队列,主线程返回。
3、启动后台程序从队列获取待处理数据。
4、后台程序对B银行接口进行远程调用。
5、B银行对转入账户进行检查校验,进行金额增加。
6、B银行处理完成回调A银行接口通知处理结果。
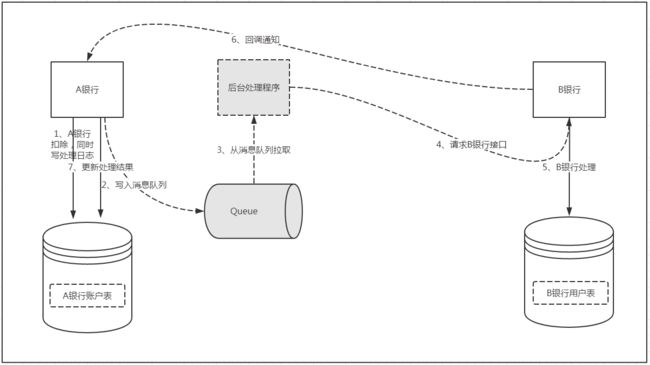
通过上面的图我们能看到,引入消息队列后,系统的复杂性瞬间提升了,虽然弥补了我们第一种方案的几个不足点,但也带来了更多的问题,比如消息队列系统本身的可用性、消息队列的延迟等等!并且,这样的设计依然没有解决我们面临的核心问题-数据的一致性!
1、如果“第1步”刚执行完,系统由于某种原因宕机了,那会导致A银行账户扣款了,但是写入消息队列失败,无法进行B银行接口调用,从而导致数据不一致。
2、如果B银行在执行“第5步”时由于校验失败而未能成功转账,在回调A银行接口通知回滚时网络异常或者宕机,会导致A银行转账无法完成回滚,从而导致数据不一致。
面对上述问题,我们不得不对系统再次进行升级改造。为了解决“A银行账户扣款了,但是写入消息队列失败”的问题,我们需要借助一个转账日志表,或者叫转账流水表,该表简单的设计如下:
| 字段名称 | 字段描述 |
|---|---|
| tId | 交易流水id |
| accountNo | 转出账户卡号 |
| targetBankNo | 目标银行编码 |
| targetAccountNo | 目标银行卡号 |
| amount | 交易金额 |
| status | 交易状态(待处理、处理成功、处理失败) |
| lastUpdateTime | 最后更新时间 |
这个流水表需要怎么用呢?我们在“第1步”进行扣款时,同时往流水表写入一条操作流水,状态为“待处理”,并且这两个操作必须是原子的,也就是说必须通过本地事务保证这两个操作要么同时成功,要么同时失败!这就保证了只要转账扣款成功,必定会记录一条状态为“待处理”的转账流水。如果在这一步失败了,那自然就是转账失败,没有后续操作了。如果这步操作后系统宕机了导致没有将消息成功写入消息队列(也就是“第2步”)也没关系,因为我们的流水数据已经持久化了!这时候我们只需要加入一个后台线程进行补偿,定期的从转账流水表中读取状态为“待处理”且最后更新的时间距当前时间大于某个阈值的数据,重新放入消息队列进行补偿。这样,就保证了消息即使丢失,也会有补偿机制!B银行在处理完转账请求后会回调A银行的接口通知转账的状态,从而更新A银行流水表中的状态字段!这样就完美解决了上一个方案中的两个不足点。系统设计图如下:
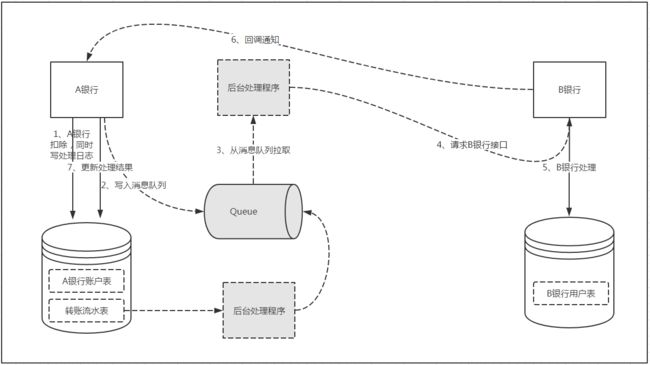
到目前为止,我们很好的解决了消息丢失的问题,保证了只要A银行转账操作成功,转账的请求就一定能发送到B银行!但是该方案又引入了一个问题,通过后台线程轮询将消息放入消息队列处理,同一次转账请求可能会出现多次放入消息队列而多次消费的情况,这样B银行会对同一转账多次处理导致数据出现不一致!那怎么保证B银行转账接口的幂等性呢?
同样的,我们可以在B银行系统中需要增加一个转账日志表,或者叫转账流水表,B银行每次接收到转账请求,在对账户进行操作的时候同时往转账日志表中插入一条转账日志记录,同样这两个操作也必须是原子的!在接收到转账请求后,首先根据唯一转账流水Id在日志表中查找判断该转账是否已经处理过,如果未处理过则进行处理,否则直接回调返回! 最终的架构图如下:
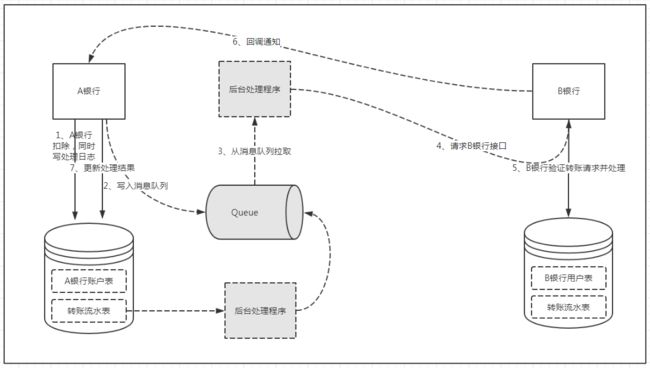
所以,我们这里最核心的就是A银行通过本地事务保证日志记录+后台线程轮询保证消息不丢失。B银行通过本地事务保证日志记录从而保证消息不重复消费!B银行在回调A银行的接口时会通知处理结果,如果转账失败,A银行会根据处理结果进行回滚。
当然,分布式事务最好的解决方案是尽量避免出现分布式事务!
最后,推荐极客时间上的一门不错的架构师课程,走向架构师必备!
