零基础使用深度学习进行目标检测
实验目的
下面这张图像存在9处瑕疵划痕(使用微软画图工具乱画的),就是要检测的目标。经过深度学习的训练,可以预测新图像上是否有瑕疵和这些瑕疵的位置(以下这张图是未参加训练的测试图)。

实验效果
经过深度学习训练后得出一个模型,利用该模型对测试图片进行预测,其预测效果如下图
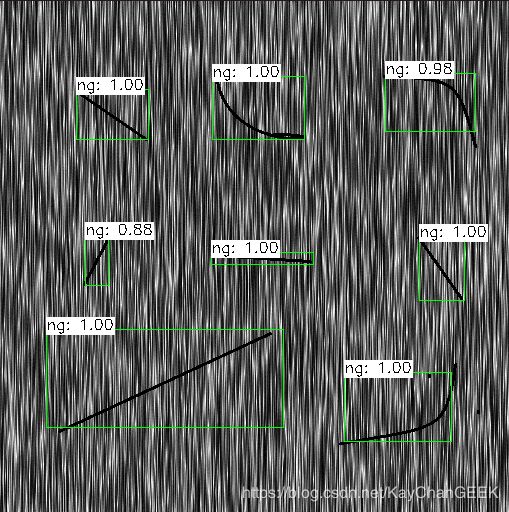
实验过程
准备训练预测工具
这是一个在Windows下本人基于darknet+qt+opencv制作的一个深度学习快速目标检测平台,可以利用该平台快速进行您自己数据集的标注/训练/预测,下载地址(戳这里)。下载后解压其目录结构如下:
准备数据集
数据集包含训练集和验证集,本实验数据集下载地址(戳这里),也可以使用其他的数据集。
建立工程
a.在darknet_train_tool下进入example目录下,拷贝工程__template_project_not_edit_just_copy__并改名为你的工程名,这里为defect。(e.g. __template_project_not_edit_just_copy__ --> defect)
b.进入defect目录下:
1.修改class.names文件,目标检测的类别写在这里面一行一类,比如本工程只预测瑕疵划痕,命名为ng。(e.g. ng)
2.进入defect/images目录下,将训练图片和验证图片对应放入train和valid目录下(图片名字不要有中文)
3.进入defect/net目录下,选择一个你需要训练的网络模型进行对应的配置修改(这里以YoloV3.cfg为例子,详细配置过程见下面的《网络配置》)
c.到此,你的工程已经建立完毕,接下来就可以开始训练了
网络配置(以YoloV3.cfg为例)
a.进入defect/net目录下,打开YoloV3.cfg(建议使用notepad++打开)
b.按下Ctrl+F搜索关键字符串"kaychan",会看到以下信息(修改所有带kaychan字段的下一行的filters和classes)
[convolutional]
size=1
stride=1
pad=1
# {kaychan}filters = 3 * (4 + 1 + classes)(这里只有一类ng类,所以classes=1,filters=18,将filters改为18即可)
filters=18
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
# {kaychan}classes = your class number(这里只有一类ng类,所以classes=1,将classes改为1即可)
classes=1
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=0 # random字段在显存或者内存够大的情况可以置为1,开启多尺度,否则会溢出
c.修改以下这些参数以适应你自己的工程
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=48 # 网络积累多少个样本后进行一次BP
subdivisions=16 # 将一个batch的图片分subdivisions次完成网络的前向传播
width=416 # 网络输入的宽(320/416/608可选)
height=416 # 网络输入的高(320/416/608可选)
channels=3 # 图像的通道数
momentum=0.9 # 动量 DeepLearning中最优化方法中的动量参数 这个值影响着梯度下降到最优值得速度
decay=0.0005 # 权重衰减正则项,防止过拟合
angle=0 # 数据增强参数,通过旋转角度来生成更多训练样本
saturation = 1.5 # 数据增强参数,通过调整饱和度来生成更多训练样本
exposure = 1.5 # 数据增强参数,通过调整曝光量来生成更多训练样本
hue=.1 # 数据增强参数,通过调整色调来生成更多训练样本
learning_rate=0.001 # 学习率
burn_in=1000 # 在迭代次数小于burn_in时,其学习率的更新有一种方式,大于burn_in时,才采用policy的更新方式
max_batches = 50000 # 最大迭代次数
policy=steps
steps=40000,45000 # steps和scale是设置学习率的变化
scales=.1,.1 # 迭代到40000次时,学习率衰减十倍,45000次迭代时,学习率又会在前一个学习率的基础上衰减十倍
开始训练
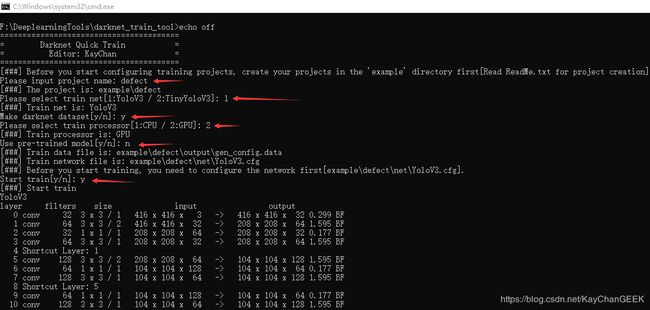
a.在darknet_train_tool目录下双击quick_train.bat文件开始训练(按照提示进行操作)
b.Please input project name: 输入你的工程名(这里就是defect)
c.Please select train net: 选择你的训练网络(1:YoloV3 / 2:TinyYoloV3,选择对应的编号即可,这里选择1:YoloV3)
d.Make darknet dataset[y/n]: 是否标注数据集(第一次训练肯定是要制作数据集的或者添加新的图片或者删除不要的图片都需要选y制作标注),标注方法可以参考《Darknet Yolo目标快速标注工具》,很简单的就是标注你的目标。
e.Please select train processor[1:CPU / 2:GPU]: 选择cpu或者gpu进行训练(如果没有nvidia-gpu就选择cpu,否则运行会报错)
f.Use pre-trained model[y/n]: 是否使用预训练模型(就是可以基于别的权重模型继续训练或者从新开始训练)
g.Start train[y/n]: 是否开始训练(按下'y'则开始训练,前提是前面的配置正确了,每迭代5000次会在example/defect/model目录下输出权重模型,每100次更新last模型)
整个操作过程如下图所示:
到此已经开始训练了,此时会有一个训练的loss图,如下图:
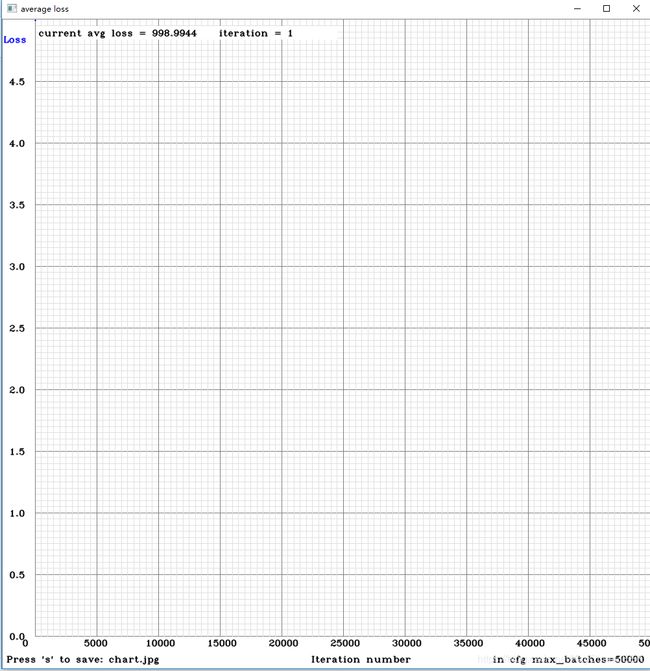
刚开始的loss值很高1000左右,经过漫长的训练迭代,这边迭代了30000次(元旦整整跑了3天3夜···,本PC的配置为:I78700+1050TI4G),loss值降到0.01左右(0.1以内效果都很不错了),已经拟合了,可以拿模型去预测了,如下图
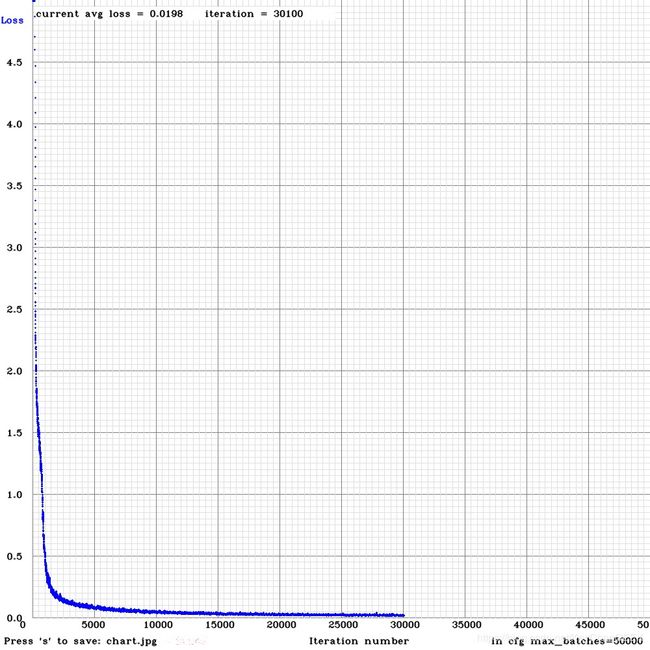
开始预测
a.在darknet_train_tool目录下双击quick_predict.bat文件开始预测(按照提示进行操作)
b.Please input project name: 输入你的工程名(这里就是defect)
c.Please select predict net[1:YoloV3 / 2:TinyYoloV3]: 选择你的预测网络(本实验选1:YoloV3)
d.Start predict[y/n]: 是否开始预测(按下'y'则弹出预测GUI,在GUI界面中选择你的待预测图片路径便开始预测)
整个操作过程如下图所示:

此时会弹出预测窗口,选择你本地的待预测图片文件夹,便开始轮询预测文件夹里面的所有图片。
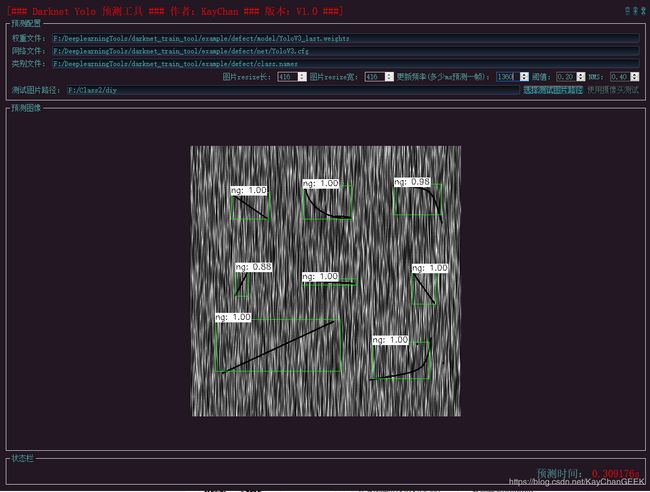
直到预测结果符合您的需求,就可以将模型导出去使用了。
注意事项
a.将本工具darknet_train_tool放在没有中文的路径下
b.训练和测试的图片名字不要有中文和其它不规则符号
c.训练时出现内存溢出(out of memory)时可以将random置为0和改小batch
d.如果要使用GPU训练必须有nvidia的显卡并且装了相应的cuda和cudnn
e.如果想单独使用图像标注工具请阅读tools/darknet_dataset_maker/ReadMe.txt
f.使用GPU训练建议安装CUDA8.0+CUDNNv5.1
技术交流
图像处理-深度学习技术交流群:qq群:247270428
如果文章对您有帮助,打赏一包辣条吧,DaLao们。

友情链接
darknet官网:https://pjreddie.com/darknet/yolo/
Windows配置darknet:https://blog.csdn.net/KayChanGEEK/article/details/84979441
cuda下载地址:https://developer.nvidia.com/cuda-toolkit-archive
cudnn下载地址:https://developer.nvidia.com/rdp/cudnn-archive