空间深度学习——ConvLSTM原理及其TensorFlow实现
今天介绍一种很有名的网络结构——ConvLSTM,其不仅具有LSTM的时序建模能力,而且还能像CNN一样刻画局部特征,可以说是时空特性具备。
LSTM已经在语音识别、视频分析、序列建模等领域取得了非常精彩的进展,传统的LSTM网络由input gate, forget gate, cell, output gate, hidden五个模块组成,并且它们之间的关系可以由以下公式表示: 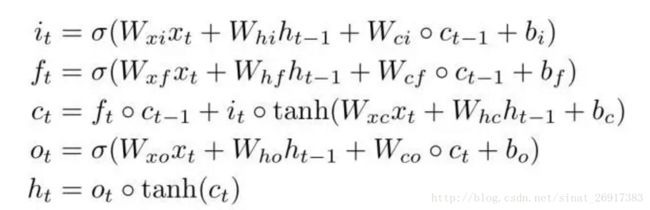
图中空心小圆圈表示矩阵对应元素相乘,又称为Hadamard乘积。这种LSTM结构我们也可以称之为FC-LSTM,因其内部门之间是依赖于类似前馈式神经网络来计算的,而这种FC-LSTM对于时序数据可以很好地处理,但是对于空间数据来说,将会带来冗余性,原因是空间数据具有很强的局部特征,但是FC-LSTM无法刻画此局部特征。本文提出的ConvLSTM尝试解决此问题,做法是将FC-LSTM中input-to-state和state-to-state部分由前馈式计算替换成卷积的形式,ConvLSTM的内部结构如下图所示: 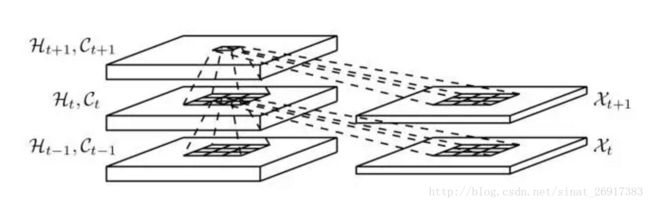
从图中可以看出,此时输入与各个门之间的连接由前馈式替换成了卷积,同时状态与状态之间也换成了卷积运算。新的ConvLSTM的工作原理可以由以下公式表示:
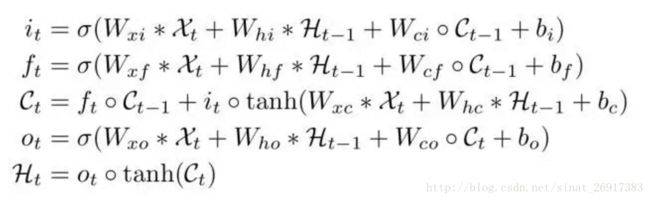
图中*表示卷积,值得注意的是,这里的X,C,H,i,f,o都是三维的tensor,它们的后两个维度代表行和列的空间信息,我们可以把ConvLSTM想象成是处理二维网格中的特征向量的模型,其可以根据网格中周围点的特征来预测中心网格的特征。原理部分就介绍这么多了,接下来我们动手来实现一个ConvLSTM。
不过在实现之前,让我们先来看一下TensorFlow中常见的RNNCell的代码设计,TensorFlow中常见的RNNCell有BasicRNNCell,GRUCell以及LSTMCell,它们都是继承自RNNCell,并且都需要实现一个共同的方法就是call(),call的作用就是指明每一步循环时候input, state, output分别是什么关系。
就BasicRNNCell而言,其call方法只需接受input和state,输出它们之间的乘积并经过一个激活函数即可,核心代码如下:
def __call__(self, inputs, state, scope=None):
with _checked_scope(self, scope or "basic_rnn_cell", reuse=self._reuse):
output = self._activation(
_linear([inputs, state], self._num_units, True))
return output, output- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
而相应的,GRUCell的核心代码如下:
def __call__(self, inputs, state, scope=None):
with _checked_scope(self, scope or "gru_cell", reuse=self._reuse):
with vs.variable_scope("gates"):
value = sigmoid(_linear(
[inputs, state], 2 * self._num_units, True, 1.0))
r, u = array_ops.split(
value=value,
num_or_size_splits=2,
axis=1)
with vs.variable_scope("candidate"):
c = self._activation(_linear([inputs, r * state],
self._num_units, True))
new_h = u * state + (1 - u) * c
return new_h, new_h- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
BaiscLSTMCell的核心代码稍微会麻烦一点,因为它增加了多个门,而这里的state也不单单是一个变量,而是一个状态组合,为了提高矩阵运算效率,这里采取的方法是把图1中的四个运算表达式拼接到了一起同时计算,计算过后再将它们分开即可,最后再计算出c和h即可,由于这里并没有增加偏置,以及像c和i之间、c和f之间、c和h之间、c和o之间都没有建立连接,因此这个LSTMCell是BasicLSTMCell,而TensorFlow中还提供了带有peephole连接的LSTMCell,感兴趣的朋友可以直接看TensorFlow源码。
def __call__(self, inputs, state, scope=None):
with _checked_scope(self, scope or "basic_lstm_cell", reuse=self._reuse):
if self._state_is_tuple:
c, h = state
else:
c, h = array_ops.split(value=state, num_or_size_splits=2, axis=1)
concat = _linear([inputs, h], 4 * self._num_units, True)
i, j, f, o = array_ops.split(value=concat, num_or_size_splits=4, axis=1)
new_c = (c * sigmoid(f + self._forget_bias) + sigmoid(i) *
self._activation(j))
new_h = self._activation(new_c) * sigmoid(o)
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat([new_c, new_h], 1)
return new_h, new_state- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在写ConvLSTMCell的时候,我们可以完全模仿BasicLSTMCell的写法,只不过这里的所有变量维度都要增加,同时,对比图1和图3可知,无论是乘积还是卷积,都可以先拼接再拆分的方法来提高运算效率。下面自己写了一段代码,仅供参考,亲测可以运行。
import tensorflow as tf
import numpy as np
class BasicConvLSTMCell(tf.contrib.rnn.RNNCell):
def __init__(self, shape, num_filters, kernel_size, forget_bias=1.0,
input_size=None, state_is_tuple=True, activation=tf.nn.tanh, reuse=None):
self._shape = shape
self._num_filters = num_filters
self._kernel_size = kernel_size
self._size = tf.TensorShape(shape+[self._num_filters])
self._forget_bias = forget_bias
self._state_is_tuple = state_is_tuple
self._activation = activation
self._reuse = reuse @property
def state_size(self):
return (tf.contrib.rnn.LSTMStateTuple(self._size, self._size)
if self._state_is_tuple else 2 * self._num_units)
@property
def output_size(self):
return self._size
def __call__(self, inputs, state, scope=None):
# we suppose inputs to be [time, batch_size, row, col, channel]
with tf.variable_scope(scope or "basic_convlstm_cell", reuse=self._reuse):
if self._state_is_tuple:
c, h = state
else:
c, h = array_ops.split(value=state, num_or_size_splits=2, axis=3)
inp_channel = inputs.get_shape().as_list()[-1]+self._num_filters
out_channel = self._num_filters * 4
concat = tf.concat([inputs, h], axis=3)
kernel = tf.get_variable('kernel', shape=self._kernel_size+[inp_channel, out_channel])
concat = tf.nn.conv2d(concat, filter=kernel, strides=(1,1,1,1), padding='SAME')
i, j, f, o = tf.split(value=concat, num_or_size_splits=4, axis=3)
new_c = (c * tf.sigmoid(f + self._forget_bias) + tf.sigmoid(i) *
self._activation(j))
new_h = self._activation(new_c) * tf.sigmoid(o)
if self._state_is_tuple:
new_state = tf.contrib.rnn.LSTMStateTuple(new_c, new_h)
else:
new_state = tf.concat([new_c, new_h], 3)
return new_h, new_state
if __name__ == '__main__':
inputs=tf.placeholder(tf.float32, [5,2,3,3,3])
cell = BasicConvLSTMCell([3,3], 6, [3,3])
outputs, state = tf.nn.dynamic_rnn(cell, inputs, dtype=inputs.dtype, time_major=True)
with tf.Session() as sess:
inp = np.random.normal(size=(5,2,3,3,3))
sess.run(tf.global_variables_initializer())
o, s = sess.run([outputs, state], feed_dict={inputs:inp})
print o.shape #(5,2,3,3,6)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
.
相关github项目:
https://github.com/viorik/ConvLSTM
https://github.com/carlthome/tensorflow-convlstm-cell