MapReduce/Hadoop的二次排序解决方案
目前正在学习《数据算法 Hadoop/Spark大树据处理技巧一书》,准备将书中代码理解一遍。
一、目的
输入:
格式:
示例:
sample_input.txt
2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,30
2000,11,24,-40
2012,12,21,30
2012,12,22,-20
2012,12,23,60
2012,12,24,70
2012,12,25,10
2013,01,22,80
2013,01,23,70
2013,01,20,-10格式:
其中temperature1 >= temperature2 >= ....
示例:
201301 80,70,-10,
201212 70,60,30,10,-20,
200012 10,-20,
200011 30,20,-40,二、为什么要进行二次排序?
使用hadoop的map reduce将原始数据按照以年份-月份为key,温度为value进行操作,hadoop默认会将key进行排序,即按照年份-月份进行排序
例如如下代码:
package ercipaixu;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Step1 {
/***
* input:
* 2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,30
2000,11,24,-40
2012,12,21,30
2012,12,22,-20
2012,12,23,60
2012,12,24,70
2012,12,25,10
2013,01,22,80
2013,01,23,70
2013,01,20,-10
output:
(2000-11,20)
(2000-11,-40)
(2000-11,30)
。。。
*
*
*
* @author chenjie
*
*/
public static class Mapper1 extends Mapper
{
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
String year = value.toString().split(",")[0];
String mounth = value.toString().split(",")[1];
//String day = value.toString().split(",")[2];
String temperature = value.toString().split(",")[3];
outKey.set(year + "-" + mounth);
outValue.set(temperature);
context.write(outKey, outValue);
}
}
/****
* input:
* (2000-11,[20,-40,30])
* ....
*
* output:
* 2000-11 20,-40,30
2000-12 10,-20
2012-12 -20,10,70,60,30
2013-01 80,70,-10
*
* @author chenjie
*
*/
public static class Reducer1 extends Reducer
{
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for(Text text : values)
{
sb.append(text + ",");
}
//注意这里末尾有个逗号
String line = "";
if(sb.toString().endsWith(","))
{
line = sb.substring(0,sb.length()-1);
}
//去掉逗号
outKey.set(key);
outValue.set(line);
context.write(outKey, outValue);
}
}
private static final String INPATH = "input/sample_input.txt";// 输入文件路径
private static final String OUTPATH = "output/sample_output";// 输出文件路径
@SuppressWarnings("deprecation")
public void run() throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = {INPATH,OUTPATH};
//这里需要配置参数即输入和输出的HDFS的文件路径
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "step1");//Job(Configuration conf, String jobName) 设置job名称和
job.setJarByClass(Step1.class);
job.setMapperClass(Mapper1.class); //为job设置Mapper类
job.setReducerClass(Reducer1.class); //为job设置Reduce类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class); //设置输出key的类型
job.setOutputValueClass(Text.class);// 设置输出value的类型
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为map-reduce任务设置InputFormat实现类 设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为map-reduce任务设置OutputFormat实现类 设置输出路径
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path(OUTPATH);
if(fs.exists(outPath))
{
fs.delete(outPath, true);
}
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args)
{
try {
new Step1().run();
} catch (ClassNotFoundException | IOException | InterruptedException e) {
e.printStackTrace();
}
}
} 对于给定的输入:
2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,30
2000,11,24,-40
2012,12,21,30
2012,12,22,-20
2012,12,23,60
2012,12,24,70
2012,12,25,10
2013,01,22,80
2013,01,23,70
2013,01,20,-10其输出为:
2000-11 20,-40,30
2000-12 10,-20
2012-12 -20,10,70,60,30
2013-01 80,70,-10
可以发现其key为有序的,而每个key中的value,也就是我们想要排序的温度值却无能为力。
因此我们需要进行二次排序,即在根据key值排序的基础上再对value值进行排序。
三、如何进行二次排序?
方案1:对于每一个key的所有value值,在(二)代码的reduce函数中先将其读取和缓存到一个集合中,然后再对这个集合应用排序算法。
问题:如果value值过多,会导致耗尽内存。
方案2:使用MapReduce框架对Reduce值排序,为自然键增加部分或整个值来创建一个组合键以实现排序目标。
理解:
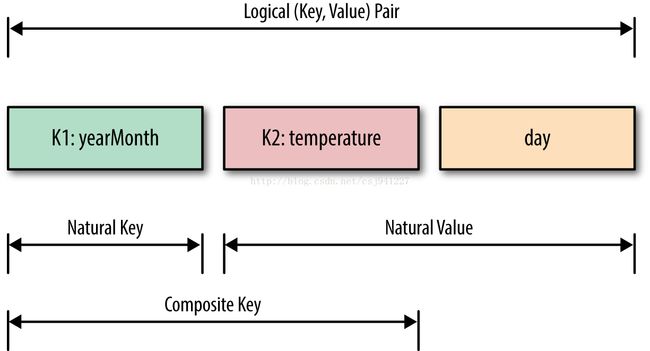
逻辑键值对:年月日温度
自然键:年月 自然值:温度
组合键:年月,温度
将【要排序的自然值】加入到自然键键中构成组合键,这样原本对于自然键进行排序的情况下还能对于要排序的自然值进行排序。
例如:
2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,302000,11,01,202000,11,07,302000,12,04,102000,12,02,-202000-11 20,30
2000-12 10,-20
显然没有关心值
而如果使用组合键
2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,30那么我们只需要定义一个保存组合键的数据结构(类),以及定义组合键间的比较策略(先按年月,年月相同的再按温度),就可以实现
四、代码
4.1 组合键数据结构
由于组合键后期需要判断大小,因此需要重写equals、hashcode方法,这是java语法规定的
定义组合键的数据结构,Hadoop中键要实现Writable(可写的)和WritableComparable(可写的可比较的)接口,其中的要实现的compareTo方法决定了键进行排序时的方式。我们的逻辑是先按年-月进行比较,如果不相等,则按年-月从小到大排序,如果年月相等,再按温度从高到低排序
package ercipaixu;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/***
* 定义组合键的数据结构,Hadoop中键要实现Writable(可写的)和WritableComparable(可写的可比较的)
* @author chenjie
*
*/
public class DateTemperaturePair
implements Writable, WritableComparable {
/**
* 年月
*/
private final Text yearMonth = new Text();
/**
* 日
*/
private final Text day = new Text();
/**
* 温度
*/
private final IntWritable temperature = new IntWritable();
public DateTemperaturePair() {
}
public DateTemperaturePair(String yearMonth, String day, int temperature) {
this.yearMonth.set(yearMonth);
this.day.set(day);
this.temperature.set(temperature);
}
public static DateTemperaturePair read(DataInput in) throws IOException {
DateTemperaturePair pair = new DateTemperaturePair();
pair.readFields(in);
return pair;
}
@Override
public void write(DataOutput out) throws IOException {
yearMonth.write(out);
day.write(out);
temperature.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
yearMonth.readFields(in);
day.readFields(in);
temperature.readFields(in);
}
@Override
public int compareTo(DateTemperaturePair pair) {
int compareValue = this.yearMonth.compareTo(pair.getYearMonth());
if (compareValue == 0) {//如果年月相等,再比较温度
compareValue = temperature.compareTo(pair.getTemperature());
}
//return compareValue; // to sort ascending
return -1*compareValue; // to sort descending
}
public Text getYearMonthDay() {
return new Text(yearMonth.toString()+day.toString());
}
public Text getYearMonth() {
return yearMonth;
}
public Text getDay() {
return day;
}
public IntWritable getTemperature() {
return temperature;
}
public void setYearMonth(String yearMonthAsString) {
yearMonth.set(yearMonthAsString);
}
public void setDay(String dayAsString) {
day.set(dayAsString);
}
public void setTemperature(int temp) {
temperature.set(temp);
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
DateTemperaturePair that = (DateTemperaturePair) o;
if (temperature != null ? !temperature.equals(that.temperature) : that.temperature != null) {
return false;
}
if (yearMonth != null ? !yearMonth.equals(that.yearMonth) : that.yearMonth != null) {
return false;
}
return true;
}
@Override
public int hashCode() {
int result = yearMonth != null ? yearMonth.hashCode() : 0;
result = 31 * result + (temperature != null ? temperature.hashCode() : 0);
return result;
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("DateTemperaturePair{yearMonth=");
builder.append(yearMonth);
builder.append(", day=");
builder.append(day);
builder.append(", temperature=");
builder.append(temperature);
builder.append("}");
return builder.toString();
}
}
4.2 映射器类
映射器类将文件中的每一行,映射为组合键和温度值的键值对
package ercipaixu;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SecondarySortMapper extends Mapper {
private final Text theTemperature = new Text();
private final DateTemperaturePair pair = new DateTemperaturePair();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] tokens = line.split(",");
// YYYY = tokens[0]
// MM = tokens[1]
// DD = tokens[2]
// temperature = tokens[3]
String yearMonth = tokens[0] + tokens[1];
String day = tokens[2];
int temperature = Integer.parseInt(tokens[3]);
pair.setYearMonth(yearMonth);
pair.setDay(day);
pair.setTemperature(temperature);
theTemperature.set(tokens[3]);
context.write(pair, theTemperature);
}
}
4.3 定制分区器
定制分区器
* 分区器会根据映射器的输出键来决定哪个映射器的输出发送到哪个规约器。为此我们需要定义两个插件类
* 首先需要一个定制分区器控制哪个规约器处理哪些键,另外还要定义一个定制比较器对规约器值排序。
* 这个定制分区器可以确保具有相同键(自然键,而不是包含温度值的组合键)的所有数据都发送给同一个规约器。
理解:必须保证同年同月的数据放到一个规约器上进行规约,因此这里要根据自然键进行分区
如果根据组合键进行分区,那么(2000-11@20,20)的组合键是2000-11@20,(2000-12@30,30)的组合键是2000-12@30,两者显然不相等,那么不会放到同一个规约器上。
package ercipaixu;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/***
* 定制分区器
* 分区器会根据映射器的输出键来决定哪个映射器的输出发送到哪个规约器。为此我们需要定义两个插件类
* 首先需要一个定制分区器控制哪个规约器处理哪些键,另外还要定义一个定制比较器对规约器值排序。
* 这个定制分区器可以确保具有相同键(自然键,而不是包含温度值的组合键)的所有数据都发送给同一个规约器。
* 定制比较器会完成排序,保证一旦数据到达规约器,就会按自然键对数据分组。
* @author chenjie
*
*/
public class DateTemperaturePartitioner
extends Partitioner {
@Override
public int getPartition(DateTemperaturePair pair,
Text text,
int numberOfPartitions) {
// make sure that partitions are non-negative
return Math.abs(pair.getYearMonth().hashCode() % numberOfPartitions);
}
}
4.4 分组比较器
分区器会根据映射器的输出键来决定哪个映射器的输出发送到哪个规约器。为此我们需要定义两个插件类
* 首先需要一个定制分区器控制哪个规约器处理哪些键,另外还要定义一个定制比较器对规约器值排序。
* 这个定制比较器对规约器值排序,它会控制哪些键要分组到一个Reducer.reduce()函数调用
package ercipaixu;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class DateTemperatureGroupingComparator
extends WritableComparator {
public DateTemperatureGroupingComparator() {
super(DateTemperaturePair.class, true);
}
@Override
public int compare(WritableComparable wc1, WritableComparable wc2) {
DateTemperaturePair pair = (DateTemperaturePair) wc1;
DateTemperaturePair pair2 = (DateTemperaturePair) wc2;
return pair.getYearMonth().compareTo(pair2.getYearMonth());
}
}
4.5 规约器
对于已经按年-月分区,分区内按温度排好序的键和值集合,进行规约,即按顺序写成一行
package ercipaixu;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SecondarySortReducer
extends Reducer {
@Override
protected void reduce(DateTemperaturePair key, Iterable values, Context context)
throws IOException, InterruptedException {
StringBuilder builder = new StringBuilder();
for (Text value : values) {
builder.append(value.toString());
builder.append(",");
}
context.write(key.getYearMonth(), new Text(builder.toString()));
}
}
4.5 驱动类
package ercipaixu;
import org.apache.log4j.Logger;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
public class SecondarySortDriver extends Configured implements Tool {
private static final String INPATH = "input/sample_input.txt";// 输入文件路径
private static final String OUTPATH = "output/sample_output";// 输出文件路径
private static Logger theLogger = Logger
.getLogger(SecondarySortDriver.class);
@SuppressWarnings("deprecation")
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = new Job(conf);
job.setJarByClass(SecondarySortDriver.class);
job.setJobName("SecondarySortDriver");
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(DateTemperaturePair.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(SecondarySortMapper.class);
job.setReducerClass(SecondarySortReducer.class);
job.setPartitionerClass(DateTemperaturePartitioner.class);
job.setGroupingComparatorClass(DateTemperatureGroupingComparator.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 为map-reduce任务设置OutputFormat实现类
// 设置输出路径
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path(OUTPATH);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
boolean status = job.waitForCompletion(true);
theLogger.info("run(): status=" + status);
return status ? 0 : 1;
}
public static void main(String[] args) throws Exception {
args = new String[2];
args[0] = INPATH;
args[1] = OUTPATH;
// Make sure there are exactly 2 parameters
if (args.length != 2) {
theLogger.warn("SecondarySortDriver ");
throw new IllegalArgumentException(
"SecondarySortDriver ");
}
int returnStatus = submitJob(args);
theLogger.info("returnStatus=" + returnStatus);
System.exit(returnStatus);
}
public static int submitJob(String[] args) throws Exception {
int returnStatus = ToolRunner.run(new SecondarySortDriver(), args);
return returnStatus;
}
}
输出结果为预期结果