R语言presentation——超市销售数据分析
- 我们需要用到的包有:arules、arulesViz、chron、dplyr、ggplot2、gplots、reshape2、wordcloud2、plyr。
> library("arules", lib.loc="~/R/win-library/3.5")
> library("arulesViz", lib.loc="~/R/win-library/3.5")
> library("chron", lib.loc="~/R/win-library/3.5")
> library("dplyr", lib.loc="~/R/win-library/3.5")
> library("ggplot2", lib.loc="~/R/win-library/3.5")
> library("gplots", lib.loc="~/R/win-library/3.5")
> library("chron", lib.loc="~/R/win-library/3.5")
> library("reshape2", lib.loc="~/R/win-library/3.5")
> library("wordcloud2", lib.loc="~/R/win-library/3.5")
> library("plyr", lib.loc="~/R/win-library/3.5")
- 查看数据并进行数据预处理
读入数据
> data<-read.csv("c:\\超市销售数据.csv",header = T)
#三种不同的查看数据的方式
> head(data)
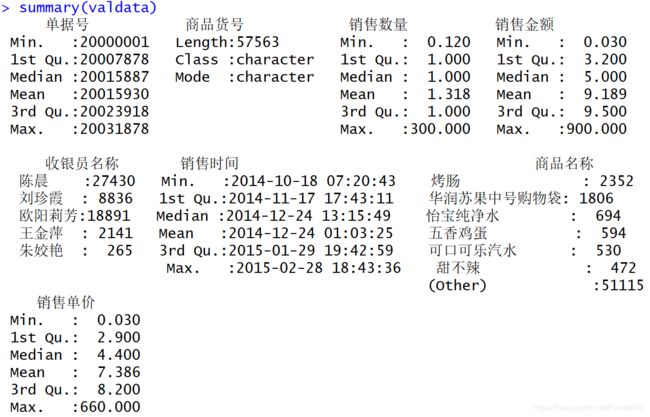
> summary(data)
> str(data)
发现销售时间、商品名称、销售数量、销售金额中有不规范信息,需要进行清理和改正。对数据进行以下操作:
> sum(is.na(data))
[1] 0
> time1<-as.character(data$销售时间)
> data$销售时间<-strptime(time1,"%Y %m %d %H %M %S")
> data$商品货号<-sub("\\s","",data$商品货号,fixed = F)
> invdata1<-subset(data,data$商品名称=="合计分舍去")
> nrow(invdata1)
[1] 618
> invdata2<-subset(data,data$商品名称=="积点印花")
> nrow(invdata2)
[1] 265
> data<-subset(data,data$商品名称!="合计分舍去"&data$商品名称!="积点印花")
> summary(data)

> valdata<-data %>%
+ select(c(销售数量,销售金额)) %>%
+ aggregate(by=list(单据号=data$单据号,商品货号=data$商品货号),FUN=sum) %>%
+ arrange(单据号) %>%
+ merge(unique(data[,1:5]),by=c("单据号","商品货号"),all=FALSE)%>%
+ mutate(销售单价=销售金额/销售数量)
> nrow(subset(valdata,valdata$销售金额<0))
> valdata<-subset(valdata,valdata$销售金额>0)
> summary(valdata)
> valdata[,1]<-as.factor(valdata[,1])
> valdata[,2]<-as.factor(valdata[,2])
> valdata[,5]<-as.factor(valdata[,5])
> valdata[,7]<-as.factor(valdata[,7])
- 分析销售数量前十的商品
snbp<-valdata%>%
group_by(商品名称)%>%
summarise(销售量=n())%>%
arrange(desc(销售量))
head(snbp,10)
str(snbp)

- 分析一定时间段内的热销商品
一年内的热销商品
valdata<-mutate(valdata,byday=days(销售时间),byweek=weekdays(销售时间),bymonths=months(销售时间),byhours=hours(销售时间))
valdata[,9]<-as.factor(valdata[,9])
valdata[,10]<-factor(valdata[,10],order=TRUE,levels = c("星期一","星期二","星期三","星期四","星期五","星期六","星期日"))#
valdata[,11]<-factor(valdata[,11],order=TRUE,levels = c("十月","十一月","十二月","一月","二月"))
valdata[,12]<-as.factor(valdata[,12])
valdata$销售时间<-as.Date(valdata$销售时间)
b1<-tapply(valdata$销售金额,valdata$销售时间,sum)
b2<-tapply(valdata$单据号,valdata$销售时间,length)
b3<-rbind(b1,b2)%>%t()%>%as.data.frame()
names(b3)<-c("销售金额","商品数按种类")
b3$时间<-rownames(b3)
rownames(b3)<-NULL
b3$时间<-strptime(b3$时间,"%Y-%m-%d")
b4<-valdata%>%
group_by(销售时间)%>%
summarise(订单数=n_distinct(单据号))
names(b4)<-c("时间","顾客数")
b3<-cbind(b3,b4[,2])
str(b3)
head(b3,15)
b3[,c(1,2,4)]<-scale(b3[,c(1,2,4)])
b3$时间<-as.Date(b3$时间)
b5<-melt(b3,id.vars=c("时间"),
measure.vars=c("销售金额", "商品数按种类", "顾客数"),
variable.name="项目类型", value.name="值")
x<-b5$时间
y<-b5$值
z<-b5$项目类型
ggplot(b5,aes(x=x,y=y,color=z,group=z))+
geom_line(size=1)+
geom_point(size=2,shape=21,fill="white")+
labs(y="标准化后值",x="时间",color="项目类型")+
theme(legend.position=c(0.5,1),legentification=c(0.5,1))+
ggtitle("按时间销售情况汇总图")
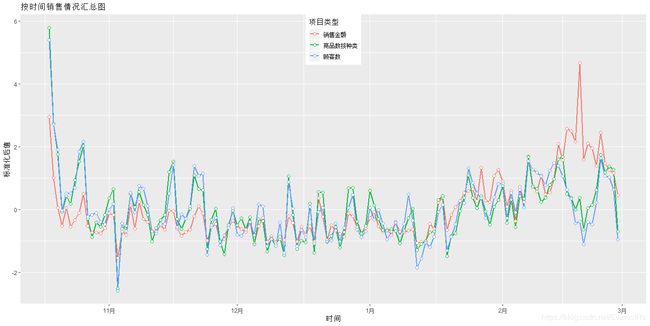
从这张图我们可以看出:
1.二月中旬的销售额和顾客数有很大差距,可以猜测,这一天是节日,从而导致客单价提高
2.每天销售有波浪形周期,周期为一天
3.十一月初销售有明显下滑,可以猜测本天为活动日,购买量显著下降
4.十二月至二月销售量较低,推测和季节有关
- 对商品名称和销售数量进行关联规则挖掘
library(arules)
library(arulesViz)
tdata<-as.split(valdata$商品名称,valdata$销售数量),"transactions")
summary(tdata)
inspect(tdata)
rules0<-apriori(tdata,parameter=list(support=0.048,confidence=0.5))
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen maxlen target ext
0.5 0.1 1 none FALSE TRUE 5 0.048 1 10 rules FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 9
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[2115 item(s), 191 transaction(s)] done [0.00s].
sorting and recoding items ... [8 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 done [0.00s].
writing ... [20 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].
> plot(rules0,method = "graph")

- 词云
wordcloud2(snbp, color = "random-light", backgroundColor = "grey",minRotation = -pi/6, maxRotation = -pi/6, minSize = 10,rotateRatio = 1)
