《机器学习》周志华西瓜书学习笔记(九):聚类
【机器学习】《机器学习》周志华西瓜书 笔记/习题答案 总目录
- https://blog.csdn.net/TeFuirnever/article/details/96178919
——————————————————————————————————————————————————————
聚类
在 无监督学习(unsupervised learning) 中,常见的无监督学习任务还有 密度估计(densityestimation)、异常检测(anomaly detection) 等,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。这类学习任务中研究最多、应用最广的是 聚类(clustering)。
这一章的内容大致如下:
-
聚类任务:聚类过程是怎样的?聚类有什么用途?聚类的两个基本问题是什么?
-
性能度量:聚类的目标是什么?聚类性能度量的两大类指什么?各包含哪些度量指标?
-
距离计算:距离度量需要满足哪些基本性质?怎样度量有序属性?怎样度量无序属性?相似度度量和距离度量有什么区别?
-
原型聚类:什么是原型聚类?k均值算法是怎样的?学习向量量化算法是怎样的?高斯混合聚类是怎样的?
-
密度聚类:什么是密度聚类?DBSCAN算法是怎样的?
-
层次聚类:什么是层次聚类?AGNES算法是怎样的?
聚类任务
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个 簇(cluster)。通过这样的划分,每个簇可能对应于一些潜在的概念(类别) ,所以对聚类算法而言,样本簇亦称 类。通常来说每个簇可能对应一些特征,比方说音乐可以聚类成古典音乐、摇滚乐、流行乐等等,西瓜就是如"浅色瓜"、“深色瓜”,“有籽瓜”、“无籽瓜”,甚至"本地瓜"、"外地瓜"等。需说明的是,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名。
形式化地说,假定样本集 D = { x 1 , x 2 , . . . , x m } D = \{x_1,x_2,...,x_m \} D={x1,x2,...,xm} 包含 m m m 个无标记样本,每个样本 x i = ( x i 1 ; x i 2 ; . . . ; x i n ) x_i = (x_{i1}; x_{i2};... ; x_{in}) xi=(xi1;xi2;...;xin) 是一个 n n n 维特征向量,则聚类算法将样本集 D D D 划分为 k k k 个不相交的簇 { C ∣ l = 1 , 2 , . . . , k } \{C | l= 1, 2, ..., k\} {C∣l=1,2,...,k},其中
![]()
![]()
相应地,我们用
![]()
表示样本 x j x_j xj 的 簇标记(cluster label) ,即
![]()
于是,聚类的结果可用包含 m m m 个元素的簇标记向量 λ = ( λ 1 ; λ 2 ; . . . ; λ m ) λ=(λ_1; λ_2; ... ; λ_m) λ=(λ1;λ2;...;λm) 表示。
基于不同的学习策略,人们设计出多种类型的聚类算法。简单来说,聚类可以分为两种用途:
- 作为一个单独过程,用于寻找数据内在的分布结构;
- 作为其他学习任务的前驱过程,比方说根据聚类结果定义类标记,然后再进行分类学习;
聚类算法的两大基本问题是 性能度量 和 距离计算。
性能度量
聚类性能度量 亦称 聚类有效性指标(validity index)。与监督学习中的性能度量作用相似,对聚类结果,需通过某种性能度量来评估其好坏;另一方面,若明确了最终将要使用的性能度量,则可直接将其作为聚类过程的优化目标,从而更好地得到符合要求的聚类结果。
聚类是将样本集 D D D 划分为若干互不相交的子集,即 样本簇。那么,什么样的聚类结果比较好呢?
直观上看,借用古成语,我们希望"物以类聚",即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的 簇内相似度(intra-cluster similarity) 高且 簇间相似度(inter-cluster similarity) 低。
聚类性能度量大致有两类:
- 一类是将聚类结果与某个 参考模型(reference model) 进行比较(例如将领域专家给出的划分结果作为参考模型),称为 外部指标(external index);
- 另一类是直接考察聚类结果而不利用任何参考模型,称为 内部指标(internal index)。
对数据集 D = { x 1 , x 2 , . . . , x m } D = \{x_1,x_2,...,x_m\} D={x1,x2,...,xm},假定通过聚类给出的簇划分为 C = { C 1 , C 2 , . . . , C k } C = \{C_1,C_2,...,C_k\} C={C1,C2,...,Ck};参考模型给出的簇划分为 C ∗ = { C 1 ∗ , C 2 ∗ , . . . , C s ∗ } C^* = \{C_1^*,C_2^*,...,C_s^*\} C∗={C1∗,C2∗,...,Cs∗}。相应地,令 λ λ λ 与 λ ∗ λ^* λ∗ 分别表示与 C C C 和 C ∗ C^* C∗ 对应的簇标记向量。把样本两两配对考虑,定义:

其中集合 S S SS SS 包含了在 C C C 中隶属于相同簇且在 C ∗ C^* C∗ 中也隶属于相同簇的样本对,集合 S D SD SD 包含了在 C 中隶属于相同簇但在 C ∗ C^* C∗ 中隶属于不同簇的样本对,…由于每个样本对 ( x i , x j ) ( i < j ) (x_i,x_j) (i < j) (xi,xj)(i<j) 仅能出现在一个集合中,因此有 α + b + c + d = m ( m − 1 ) / 2 α + b + c + d = m(m-1)/2 α+b+c+d=m(m−1)/2 成立。
基于式 (9.1 ) ~ (9.4),可导出下面这些常用的聚类性能度量外部指标:
- Jaccard 系数(Jaccard Coefficient ,简称JC)

解析:
南瓜书——https://datawhalechina.github.io/pumpkin-book/#/


- FM 指数(Fowlkes and Mallows lndex,简称FMI)
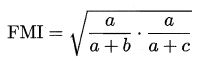
解析:
南瓜书——https://datawhalechina.github.io/pumpkin-book/#/

- Rand 指数(Rand Index,简称RI)
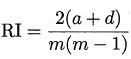
解析:
南瓜书——https://datawhalechina.github.io/pumpkin-book/#/

显然,上述性能度量的结果值均在 [0,1] 区间,值越大越好。
考虑聚类结果的簇划分 C = { C 1 , C 2 , … , C k } C=\{C_1,C_2,…,C_k\} C={C1,C2,…,Ck},定义:
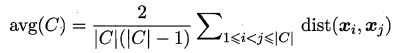
![]()
![]()
![]()
其中, d i s t ( ⋅ , ⋅ ) dist (·,·) dist(⋅,⋅) 用于计算两个样本之间的距离; μ μ μ 代表簇 C C C 的中心点:
![]()
![]()
显然, a v g ( C ) avg(C) avg(C) 对应于簇 C C C 内样本间的平均距离, d i a m ( C ) diam(C) diam(C) 对应于簇 C C C 内样本间的最远距离, d m i n ( C i , C j ) d_{min}(C_i, C_j) dmin(Ci,Cj) 对应于簇 C i C_i Ci 与簇 C j C_j Cj 最近样本间的距离, d c e n ( C i , C j ) d_{cen}(C_i,C_j) dcen(Ci,Cj) 对应于簇 C i C_i Ci 与簇 C j C_j Cj 中心点间的距离。
基于这四个式子,可导出下面这些常用的聚类性能度量内部指标:
- DB 指数(Davies-Bouldin Index,简称DBI)
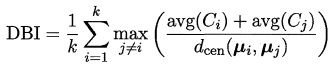
- Dunn 指数(Dunn Index,简称DI)
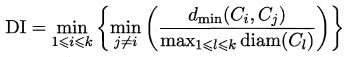
显然, DBI 的值越小越好,而 DI 则相反,值越大越好。
距离计算
对函数 d i s t ( ⋅ , ⋅ ) dist(·,·) dist(⋅,⋅),若它是一个 距离度量(distance measure),则需满足一些基本性质:
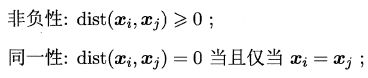

直递性常被直接称为"三角不等式"
给定样本 x i = ( x i 1 ; x i 2 ; . . . ; x i n ) x_i = (x_{i1}; x_{i2};... ;x_{in}) xi=(xi1;xi2;...;xin) 与 x j = ( x j 1 ; x j 2 ; . . . ; x j n ) x_j = (x_{j1}; x_{j2};... ;x_{jn}) xj=(xj1;xj2;...;xjn) , 最常用的是 闵可夫斯基距离(Minkowski distance)。

对 p >= 1,上式显然满足。
当 p = 2 时,闵可夫斯基距离 即 欧氏距离(Euclidean distance)。

p -> ∞ 时则得到 切比雪夫距离。

p = 1 时,闵可夫斯基距离 即 曼哈顿距离(Manhattan distance),亦称 街区距离(city block distance)
属性经常划分为 连续属性(continuous attribute),亦称 数值属性(numerical att巾ute);和 离散属性(categorical attribute),亦称 列名属性(nominal attribute)。前者在定义域上有无穷多个可能的取值,后者在定义域上是有限个取值。
然而,在讨论距离计算时,属性上是否定了"序"关系更为重要。例如定义域为 {1 , 2 , 3} 的离散属性与连续属性的性质更接近一些,能直接在属性值上计算距离 “1” 与 “2” 比较接近、与"3" 比较远,这样的属性称为 有序属性(ordinal attribute); 而定义域为 {飞机,火车,轮船} 这样的离散属性则不能直接在属性值上计算距离,称为 无序属性(non-ordinal attribute)。显然,闵可夫斯基距离可用于有序属性。
对无序属性可采用 VDM (Value Difference Metric)。令 m u , a m_{u,a} mu,a 表示在属性 u u u 上取值为 a a a 的样本数, m u , a , i m_{u, a, i} mu,a,i 表示在第 i i i 个样本簇中在属性 u u u 上取值为 a a a 的样本数, k k k 为样本簇数(样本类别已知时 k k k 通常设置为类别数),则属性 u u u 上两个离散值 a a a 与 b b b 之间的 VDM 距离为
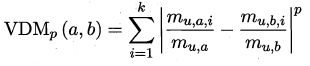
于是,将闵可夫斯基距离和 VDM 结合即可处理混合属性。假定有 n c n_c nc 个有序属性、 n − n c n - n_c n−nc 个无序属性,不失一般性,令有序属性排列在无序属性之前,则

当样本空间中不同属性的重要性不同时,可使用 加权距离(weighted distance)。以加权闵可夫斯基距离为例:
![]()
其中权重 w i w_i wi 表征不同属性的重要性, 通常
![]()
原型聚类
原型聚类 亦称 基于原型的聚类(prototype~ based clustering),原型 是指样本空间中具有代表性的点。此类算法假设聚类结构能通过一组原型刻画,在现实聚类任务中极为常用。通常情形下,算法先对原型进行初始化,然后对原型进行迭代更新求解。采用不同的原型表示、不同的求解方式,将产生不同的算法,下面介绍几种著名的原型聚类算法。
k 均值算法
给定样本集 D = { x 1 , x 2 , . . . , x m } D = \{x_1, x_2, ... ,x_m\} D={x1,x2,...,xm},k 均值(k-means ) 算法针对聚类所得簇划分 C = { C 1 , C 2 , . . . , C k } C = \{C_1, C_2,..., C_k\} C={C1,C2,...,Ck} 最小化平方误差
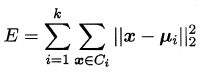
其中簇 C i C_i Ci 的均值向量如下:
![]()
直观来看,上式在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度, E E E 值越小,则簇内样本相似度越高。
最小化式 E E E 并不容易,找到它的最优解需考察样本集 D 所有可能的簇划分,这是一个 NP 难问题。因此,k 均值算法采用了贪心策略,通过迭代优化来近似求解式 E E E。算法流程如下:

其中第 1 行对均值向量进行初始化,在第 4-8 行与第 9一16 行依次对当前簇划分及均值向量选代更新,若迭代更新后聚类结果保持不变,则在第 18 行将当前簇划分结果返回。

学习向量量化
与 k 均值算法类似,学习向量量化(Learning Vector Quantization,简称LVQ) 也是试图找到一组原型向量来刻画聚类结构, 但与一般聚类算法不同的是, LVQ 假设数据样本带有类别标记,学习过程利用样本的这些监督信息来辅助聚类。
给定样本集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D = \{(x_1, y_1), (x_2,y_2),..., (x_m, y_m)\} D={(x1,y1),(x2,y2),...,(xm,ym)},每个样本 x j x_j xj 是由 n n n 个属性描述的特征向量 ( x j 1 ; x j 2 ; . . . ; x j n ) (x_{j1}; x_{j2}; ...; x_{jn}) (xj1;xj2;...;xjn)。
样本 x j x_j xj 的类别标记如下
![]()
LVQ 的目标是学得一组 n n n 维原型向量 { p 1 , p 2 , . . . , p q } \{p_1, p_2, . . .,p_q\} {p1,p2,...,pq},每个原型向量代表一个聚类簇,簇标记
![]()
LVQ 算法描述如下图所示:

算法第 1 行先对原型向量进行初始化,例如对第 q q q 个簇可从类别标记为 t q t_q tq 的样本中随机选取一个作为原型向量。算法第 2 - 12 行对原型向量进行迭代优化。在每一轮选代中,算法随机选取一个有标记训练样本,找出与其距离最近的原型向量,井根据两者的类别标记是否一致来对原型向量进行相应的更新。第5 行是竞争学习的"胜者为王"策略。SOM 是基于元标记样本的聚类算法,而 LVQ 可看作 SOM 基于监督信息的扩展。在第 12 行中,若算法的停止条件已满足(例如己达到最大迭代轮数,或原型向量更新很小甚至不再更新),则将当前原型向量作为最终结果返回。
显然, LVQ 的关键是第 6-10 行,即如何更新原型向量。直观上看,对样本 x j x_j xj,若最近的原型向量 p p p 与 x j x_j xj 的类别标记相同,则令 p i ∗ p_i^* pi∗ 向 x j x_j xj 的方向靠拢,如第7 行所示,此时新原型向量为
![]()
p ′ p' p′ 与 x j x_j xj 之间的距离为

令学习率 η η η 的区间为 ( 0 , 1 ) (0,1) (0,1) ,则原型向量 p ∗ p^* p∗ 在更新为 p ′ p' p′ 之后将更接近 x j x_j xj。
类似的,若 p ∗ p^* p∗ 与 x j x_j xj 的类别标记不同,则更新后的原型向量与 x j x_j xj 之间的距离将增大为
![]()
从而更远离 x j x_j xj。
在学得一组原型向量 { p 1 , p 2 , . . . , p q } \{p_1, p_2, ..., p_q\} {p1,p2,...,pq} 后,即可实现对样本空间 X X X 的簇划分。对任意样本 x x x,它将被划入与其距离最近的原型向量所代表的簇中;换言之,每个原型向量 p i p_i pi 定义了与之相关的一个区域 R i R_i Ri,该区域中每个样本与 p i p_i pi 的距离不大于它与其他原型向量
![]()
的距离,即
![]()
由此形成了对样本空间 X X X 的簇划分 { R 1 , R 2 , … , R q } \{R_1, R_2, …, R_q\} {R1,R2,…,Rq}, 该划分通常称为 Voronoi剖分(Voronoi tessellation)。

高斯混合聚类
高斯混合聚类与 k 均值、LVQ 用原型向量来刻画聚类结构不同,高斯混合(Mixture-of-Gaussian)聚类 采用概率模型来表达聚类原型。
先简单回顾一下(多元)高斯分布的定义。对 n n n 维样本空间 X X X 中的随机向量 x x x , 若 x x x 服从高斯分布,其橄率密度函数为
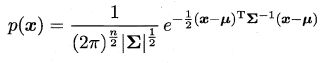

其中 μ μ μ 是 n n n 维均值向量,![]() 是 n ∗ n n * n n∗n 的协方差矩阵。由这个式子可以看出,高斯分布完全由均值向量和协方差矩阵这两个参数确定。为了明确显示高斯分布与相应参数的依赖关系,将概率密度函数记为
是 n ∗ n n * n n∗n 的协方差矩阵。由这个式子可以看出,高斯分布完全由均值向量和协方差矩阵这两个参数确定。为了明确显示高斯分布与相应参数的依赖关系,将概率密度函数记为
![]()
定义高斯混合分布:


该分布共由k 个混合成分组成, 每个混合成分对应一个高斯分布。相应的 混合系数(mixture coefficient) 如下:
![]()
![]()
假设样本 D = { x 1 , x 2 , … , x m } D = \{x_1,x_2,…,x_m\} D={x1,x2,…,xm} 的生成过程由高斯混合分布给出,令随机变量 z j z_j zj, j = { 1 , 2 , . . . , k } j = \{1,2, ..., k\} j={1,2,...,k} 表示生成样本 x j x_j xj 的高斯混合成分,其取值未知。显然, z j z_j zj 的先验概率 P ( z j = i ) P(z_j = i) P(zj=i) 对应于 α i ( i = 1 , 2 , … , k ) α_i(i=1,2, …, k) αi(i=1,2,…,k)。根据贝叶斯定理, z j z_j zj 的后验分布对应于:
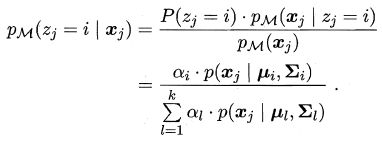
换言之,上式子给出了样本 x j x_j xj 由第 i i i 个高斯混合成分生成的后验概率。为方便叙述,将其简记为
![]()
当高斯混合分布己知时,高斯混合聚类将把样本集 D D D 划分为 k k k 个簇 C k C_k Ck,每个样本 x j x_j xj 的簇标记 λ j \lambda_j λj 如下确定:
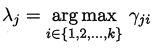
因此,从原型聚类的角度来看,高斯混合聚类是采用概率模型(高斯分布)对原型进行刻画,簇划分则由原型对应后验概率确定。那么模型参数如何求解呢?
可采用极大似然估计,即最大化(对数)似然:
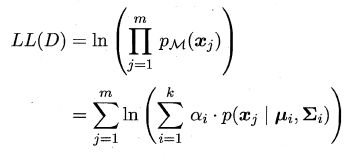
常采用EM 算法进行迭代优化求解。
若参数能最大化似然函数,则由

有如下
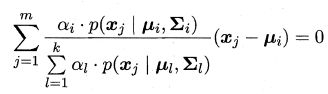
解析:
南瓜书——https://datawhalechina.github.io/pumpkin-book/#/


又因为
![]()
故有

即各混合成分的均值可通过样本加权平均来估计,样本权重是每个样本属于该成分的后验概率。
类似的,由于
![]()
可得

解析:
南瓜书——https://datawhalechina.github.io/pumpkin-book/#/


对于混合系数,除了要最大化似然函数, 还需满足系数本身非负且加和为1,考虑 L L ( D ) LL(D) LL(D) 的拉格朗日形式
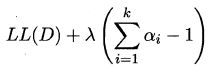
由上式对 α i \alpha_i αi 的导数为0,有
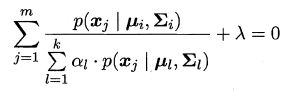
两边同乘以 α i \alpha_i αi,对所有样本求和可知 λ = − m λ = -m λ=−m,有

解析:
南瓜书——https://datawhalechina.github.io/pumpkin-book/#/

即每个高斯成分的混合系数由样本属于该成分的平均后验概率确定。
由上述推导即可获得高斯混合模型的 EM 算法。
高斯混合聚类算法描述如下图所示:

算法第 1 行对高斯混合分布的模型参数进行初始化,然后在第 2-12 行基于 EM 算法对模型参数进行选代更新。若 EM 算法的停止条件满足(例如己达到最大法代轮数,或者似然函数 LL(D) 增长很少甚至不再增长) ,则在第 14-17 行根据高斯混合分布确定簇划分,在第 18 行返回最终结果。

密度聚类
密度聚类 亦称 基于密度的聚类(density-based clustering),此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。
DBSCAN 是一种著君的密度粟类算法?它基于一组"邻域" (neighborhood)参数
![]()
来刻画样本分布的紧密程度。给定数据集 D D D,定义下面这几个概念:





上述概念的直观显示如下:

简单来说,就是字面意思,核心对象的核心,密度直达的直达,密度可达的可达,密度相连的相连,就好比集合之间的碰撞一下。
基于这些概念, DBSCAN 将"簇"定义为:由密度可达关系导出的最大的密度相连样本集合。形式化地说,给定邻域参数 , 簇 C C C 是满足以下性质的非空样本子集:
![]()
![]()
那么,如何从数据集 D D D 中找出满足以上性质的聚类簇呢?
实际上,若 x x x 为核心对象,由 x x x 密度可达的所有样本组成的集合记为 X X X
![]()
![]()
则不难证明 X X X 即为满足连接性与最大性的簇。
于是, DBSCAN 算法先任选数据集中的一个核心对象为种子(seed),再由此出发确定相应的聚类簇,算法描述如下所示:

在第 1-7 行中,算法先根据给定的邻域参数找出所有核心对象;然后在第 10-24 行中,以任一核心对象为出发点,找出由其密度可达的样本生成聚类簇,直到所有核心对象均被访问过为止。


层次聚类
层次聚类(hierarchical clustering) 试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集的划分可采用 “自底向上” 的聚合策略,也可采用 “自顶向下” 的分拆策略。
AGNES 是一种采用自底向上聚合策略的层次聚类算法。它先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个粟类簇进行合并,该过程不断重复,直至达到预设的聚类簇个数。这里的关键是如何计算聚类簇之间的距离。实际上,每个簇是一个样本集合,因此,只需采用关于集合的某种距离即可。例如,给定聚类簇 C i C_i Ci 与 C j C_j Cj,可通过下面的式子来计算距离:
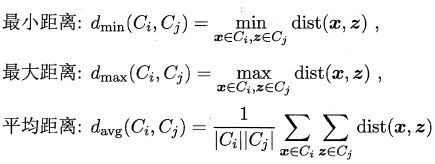
显然,最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,而平均距离则由两个簇的所有样本共同决定。当聚类簇距离由 d m i n d_{min} dmin、 d m a x d_{max} dmax 或 d a v g d_{avg} davg 计算时, AGNES 算法被相应地称为 “单链接” (single-linkage)、“全链接” (complete-linkage) 或 “均链接” (average-linkage) 算法。
AGNES 算法描述如下图所示:

在第 1-9 行,算法先对仅含一个样本的初始聚类簇和相应的距离矩阵进行初始化;然后在第 11-23 行, AGNES 不断合
并距离最近的聚类簇,井对合并得到的聚类簇的距离矩阵进行更新;上述过程不断重复,直至达到预设的聚类簇数。
补充
聚类也许是机器学习中"新算法"出现最多、最快的领域一个重要原因是聚类不存在客观标准;给定数据集7 总能从某个角度找到以往算法未覆盖的某种标准从而设计出新算法。相对于机器学习其他分支来说, 聚类的知识还不够系统化。因此著名教科书 [Mitchell,1997] 中甚至没有关于聚类的章节,但聚类技术本身在现实任务中非常重要!!!
聚类性能度量除上面的内容外,常见的还有:
- F 值
- 互信息(mutual information)
- 平均廓宽(average silhouette width)等等
距离计算是很多学习任务的核心技术。间可夫斯基距离提供了距离计算的一般形式,除闵可夫斯基距离之外,内积距离、余弦距离等也很常用。