用pandas探索Movielens数据集
- 数据集:本文用的是Movielens ml-100k.zip
- 本文为译文,原文链接:
Let’s begin
1.数据集情况,
# u.user文件中为user_id,age,occupation,zip_code,格式如下:

# u.data文件中为user_id,movie_id,rating,unix_timestamp,格式如下:

# u.item文件中为movie_id,title, release_date, video_release_date,imdb_url,格式如下:

import pandas as pd
import numpy as np
import matplotlib.pylab as plt
%matplotlib inline
# 读入数据
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv('u.user', sep='|', names=u_cols,encoding='latin-1')
r_cols = ['user_id', 'movie_id', 'rating', 'unix_timestamp']
ratings = pd.read_csv('u.data', sep='\t', names=r_cols,encoding='latin-1')
m_cols = ['movie_id', 'title', 'release_date', 'video_release_date', 'imdb_url']
movies = pd.read_csv('u.item', sep='|', names=m_cols, usecols=range(5),encoding='latin-1') # 数据集整合
movie_ratings = pd.merge(movies, ratings)
lens = pd.merge(movie_ratings, users)联合后数据及情况如下:
1. 列出被评价过次数最多的20部电影:按照电影标题将数据集分为不同的groups,并且用size( )函数得到每部电影的个数(即每部电影被评论的次数),按照从大到小排序,取最大的前20部电影列出如下:
most_rated = lens.groupby('title').size().sort_values(ascending=False)[:20]
most_rated
此语句等价于SQL中的:
SELECT title, count(1)
FROM lens
GROUP BY title
ORDER BY 2 DESC
LIMIT 20;
【输出】
title
Star Wars (1977) 583
Contact (1997) 509
Fargo (1996) 508
Return of the Jedi (1983) 507
Liar Liar (1997) 485
English Patient, The (1996) 481
Scream (1996) 478
Toy Story (1995) 452
Air Force One (1997) 431
Independence Day (ID4) (1996) 429
Raiders of the Lost Ark (1981) 420
Godfather, The (1972) 413
Pulp Fiction (1994) 394
Twelve Monkeys (1995) 392
Silence of the Lambs, The (1991) 390
Jerry Maguire (1996) 384
Chasing Amy (1997) 379
Rock, The (1996) 378
Empire Strikes Back, The (1980) 367
Star Trek: First Contact (1996) 365
dtype: int642. 评分最高的十部电影
按照电影名称分组,用agg函数通过一个字典{‘rating’: [np.size, np.mean]}来按照key即rating这一列聚合,查看每一部电影被评论过的次数和被打的平均分。取出至少被评论过100次的电影按照平均评分从大到小排序,取最大的10部电影。
movie_stats = lens.groupby('title').agg({'rating': [np.size, np.mean]})
atleast_100 = movie_stats['rating']['size'] >= 100
movie_stats[atleast_100].sort_values([('rating', 'mean')], ascending=False)[:10]
上述语句等价于SQL中的:
SELECT title, COUNT(1) size, AVG(rating) mean
FROM lens
GROUP BY title
HAVING COUNT(1) >= 100
ORDER BY 3 DESC
LIMIT 10;
【输出】
rating
size mean
title
Close Shave, A (1995) 112 4.491071
Schindler's List (1993) 298 4.466443
Wrong Trousers, The (1993) 118 4.466102
Casablanca (1942) 243 4.456790
Shawshank Redemption, The (1994) 283 4.445230
Rear Window (1954) 209 4.387560
Usual Suspects, The (1995) 267 4.385768
Star Wars (1977) 583 4.358491
12 Angry Men (1957) 125 4.344000
Citizen Kane (1941) 198 4.2929293. 查看不同年龄见争议最大的电影:
(1)。查看用户的年龄分布:
users.age.plot.hist(bins=30)
plt.title("Distribution of users' ages")
plt.ylabel('count of users')
plt.xlabel('age');
(2)用pandas.cut函数将用户年龄分组:
labels = ['0-9', '10-19', '20-29', '30-39', '40-49', '50-59', '60-69', '70-79']
lens['age_group'] = pd.cut(lens.age, range(0, 81, 10), right=False, labels=labels)
lens[['age', 'age_group']].drop_duplicates()[:10]
(3)每个年龄段用户评分人数和打分偏好,看起来年轻人更挑剔一点点
lens.groupby('age_group').agg({'rating': [np.size, np.mean]})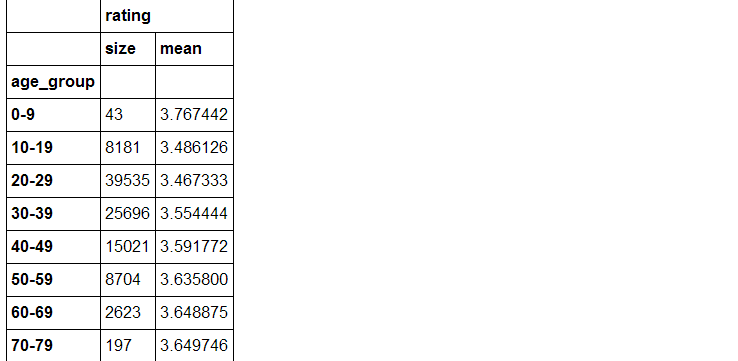
(4)查看被评价过最多次的50部电影在不同年龄段之间的打分差异。并且用unstack函数将数据转换为一个表格,每一行为电影名称,每一列为年龄组,值为该年龄组的用户对该电影的平均评分。
most_50 = lens.groupby('movie_id').size().sort_values(ascending=False)[:50]
lens.set_index('movie_id', inplace=True)
by_age = lens.loc[most_50.index].groupby(['title', 'age_group'])
by_age.rating.mean().head(15)
by_age.rating.mean().unstack(1).fillna(0)[10:20]
# 若将上面的一句改为如下,则将电影标题置为列将年龄组置为行:
by_age.rating.mean().unstack(0).fillna(0)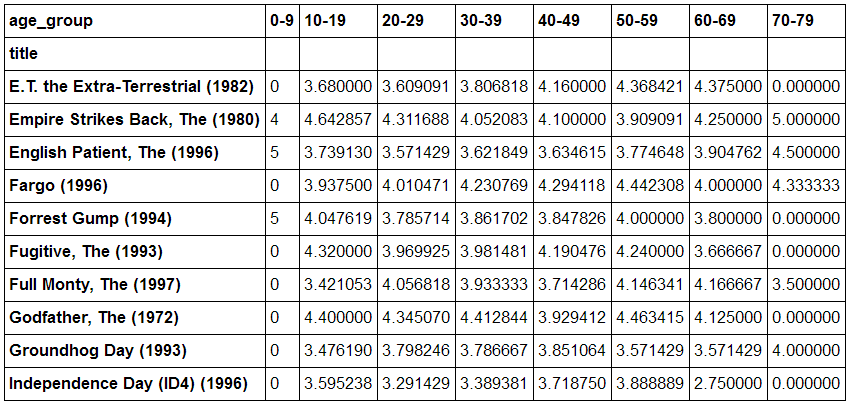
4.不同性别间争议最大的电影
(1)
lens.reset_index('movie_id', inplace=True)
pivoted = lens.pivot_table(index=['movie_id', 'title'],
columns=['sex'],
values='rating',
fill_value=0)
pivoted['diff'] = pivoted.M - pivoted.F
pivoted.head()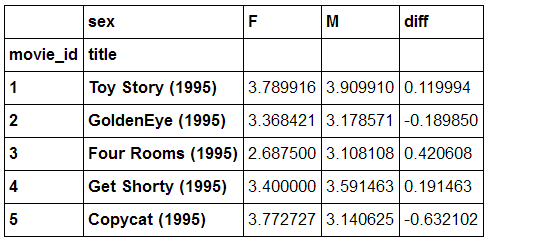
(2)
pivoted.reset_index('movie_id', inplace=True)
disagreements = pivoted[pivoted.movie_id.isin(most_50.index)]['diff']
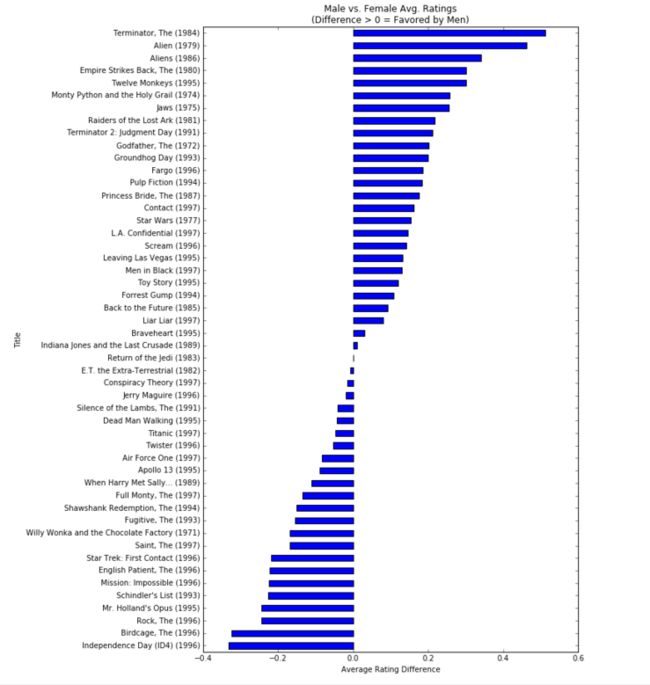
disagreements.sort_values().plot(kind='barh', figsize=[9, 15])
plt.title('Male vs. Female Avg. Ratings\n(Difference > 0 = Favored by Men)')
plt.ylabel('Title')
plt.xlabel('Average Rating Difference');