SCA-CNN算法笔记
论文:SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
链接:https://arxiv.org/abs/1611.05594
Github代码:https://github.com/zjuchenlong/sca-cnn
这篇是CVPR2017的文章,主要介绍在网络的multi-layer上用channel wise attention和spatial attention结合的方式来做image caption(图像标注)。attention机制的本质是训练一个权重,然后这个权重可以用来对channel做选择或者叠加在feature map的每个像素点上,比如分类网络中的SE-Net就是采用的训练权重对feature map的channel做选择的方式。直观上的理解就是不管是图像分类还是图像标注,每次网络的关注点(attention)可能只是图像中的一小部分,这也就是文中作者说的人类的视觉系统其实可以看做是一种dynamic feature extraction mechanism(动态的特征提取机制),因此如果能在模型关注某个部分的时候都强调这个部分的话,对于模型效果的提升是有帮助的,这就是attention训练得到的weight的作用。attention机制在image caption上的应用应该可以追溯到ICML2015的这篇:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention文章,不过在那篇文章中主要对网络的最后一个卷积层采用spatial attention, 显然作者认为这种spatial attention并不完全符合attention机制,因为CNN features are naturally spatial, channel-wise and multi-layer。所以就有了在multi-layer feature map上结合channel wise attention和spatial attention两种attention做image caption的方式。
既然要在spatial attention的基础上引入multi-layer思想和channel wise attention,那么就要看看效果怎么样。Figure1是采用channel wise attention方法处理网络的某些层(比如VGG19网络中的conv5_3和conv5_4层)后的可视化效果。选取其中权重最大的3个channel的feature map并可视化,同时展示了每个channel的feature map对应的5张图像中感受野的响应最大的区域。
为什么要引入channel wise attention?channel wise attention的本质是什么呢?举个例子:当你要预测cake时,那么channel wise attention就会使得提取到cake特征的卷积核生成的feature map的权重加大。因此作者在文中将channel wise attention总结为semantic attention,semantic attention的内容可以参看CVPR2016的论文:Image captioning with semantic attention。
为什么要引入multi-layer呢?因为高层的feature map的生成是依赖低层的feature map的,比如你要预测cake,那么只有低层卷积核提取到更多cake边缘特征,高层才能更好地抽象出cake。另外如果只在最后一个卷积层做attention,其feature map的receptive field已经很大了(几乎覆盖整张图像),那么feature map之间的差异就比较小,不可避免地限制了attention的效果,所以对multi-layer的feature map做attention也是顺其自然的事。
另外顺便提下spatial attention的作用就是前面最早提到的,不管是图像分类还是图像标注,每次网络的关注点(attention)可能只是图像中的一小部分,spatial attention则可以实现为关键部分配更大的权重,让模型的注意力更集中于这部分内容。

仔细体会,可以看出channel wise attention是在回答“是什么”,而spatial attention是在回答“在哪儿”,二者是不一样的。
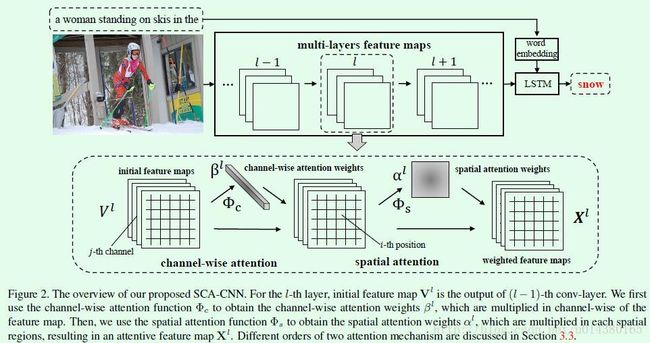
Figure2是SCA-CNN的整体图,还是采取的经典的encoder-decoder结构,主要包含CNN网络(encoder)和LSTM网络(decoder)两部分。CNN网络包含spatial attention和channel wise attention两种attention操作。spatial attention可以理解以feature map的每个像素点为单位,对feature map的每个像素点都配一个权重值,因此这个权重值应该是一个矩阵;channel wise attention则是以feature map为单位,对每个channel都配一个权重值,因此这个权重值应该是一个向量。这两种attention操作的输入输出分别如下面的公式3和4所示,下标s代表spatial attention函数,下标c表示channel wise attention函数,Vl是feature map,ht-1是LSTM生成的。

LSTM网络的计算过程如公式2所示。其中ht-1是已经预测得到的描述词,ht是将要预测的词,XL是CNN网络的输出(其中L是CNN网络的卷积层数目),pt是一个概率向量(pt的维度是|D|,D是预先定义的包含所有描述单词的字典)。

因此整个网络的流程(可以结合Figure2)可以分为CNN网络将输入图像encode成feature map和LSTM网络将feature mapdecode成词序列这两步:1、一张待描述的图像输入给CNN网络,在CNN网络的多个层的feature map上执行上述两种attention操作。具体而言是这样的:首先Vl是网络中第(l-1)层的输出feature map,该feature map经过channel wise attention 函数(前面的公式4)得到权重 βl。然后这个βl和Vl相乘就得到中间结果的feature map。接下来feature map经过spatial attention函数(前面的公式3)得到权重 αl。这个αl和前面生成的feature map相乘得到最终的Xl。2、CNN网络的输出以及已经预测得到的部分描述句子作为LSTM网络的输入,得到描述句子的下一个单词。
前面只介绍了channel wise attention和spatial attention函数的输入输出,并没有介绍这两个函数的实际计算公式,那么到底这两种attention是怎么计算的?
Channel wise Attention函数的具体计算过程如公式7所示,可以和前面的公式4一起结合看。解释下维度,v=[v1,v2,…,vc],v是c维的向量。Wc*v是k*c的矩阵,因此b也是k*c的矩阵,所以W`ib是1*c的向量,β也是1*c的向量。因此β的每个值表示channel数为c的feature map的每个channel的权重。

Spatial Attention函数的具体计算过程如公式5所示,可以和前面的公式3一起结合看。解释下维度,V=[v1,v2,…,vm],vi是C维的向量,m=WH(长宽的乘积),那么WsV的维度就是k*m,WsV+bs的维度也是k*m,然后再和一个向量(Whsht-1)相乘得到a,a的维度还是k*m。Wia的维度是1*m,是一个向量,所以α也是维度为1*m的向量。因此α的每个值表示feature map中每个点的权重(一共WH=m个点)。

根据两种attention的先后顺序不同可以组合出两种处理形式,第一种如公式8所示,先进行channel wise attention,再进行spatial attention,其中fc函数表示channel wise multiplication,简单讲就是用一个维度和输入feature map的channel数相同的向量和feature map的channel相乘。


实验结果:
由前面的介绍可知本文的创新点在于一方面引入channel wise attention,另一方面在于在multi-layer上进行attention操作,因此实验方面先分别验证这两个创新点的效果,最后再和其他优秀算法做对比。
实验主要在三个数据集Flickr8K、Flickr30K、MSCOCO上进行。CNN网络采用两种常用的网络:VGG-19和ResNet-152。
首先是channel wise attention的效果,可以看Table1。Table1是在不同数据集和不同主网络上的实验对比。在Method一列中,S表示只采用spatial attention、C表示只采用channel wise attention、S-C表示先进行spatial attention再进行channel wise attention、C-S表示先进行channel wise attention再进行spatial attention、SAT表示论文“Show, ttend and tell: Neural image caption generation with visual attention”中的模型。在S和C的具体操作中,是对最后一个卷积层的输出feature map进行相应的attention操作,然后用得到的weights对输出feature map进行加权得到新的feature map输出,新的feature map再过网络后面的层(VGG中是全连接层,ResNet中是global average pooling)。
从Table1中可以得到几个结论:1、方法S在VGG网络的表现要优于SAT,但是在ResNet网络上的表现要劣于SAT。主要原因在于在VGG网络中,加权后的feature map经过的是全连接层,全连接层不会丢失空间信息;而在ResNet网络中,加权后的feature map经过的是pooling层,会丢失空间位置信息。2、和方法S相比,方法C在ResNet上的表现要远远好于VGG网络,主要原因是前者的最后一个卷积层有更多的channel输出,这样有利于channel wise attention提升效果。3、C-S和S-C的结果比较相近,但是C-S的效果会更好一点。

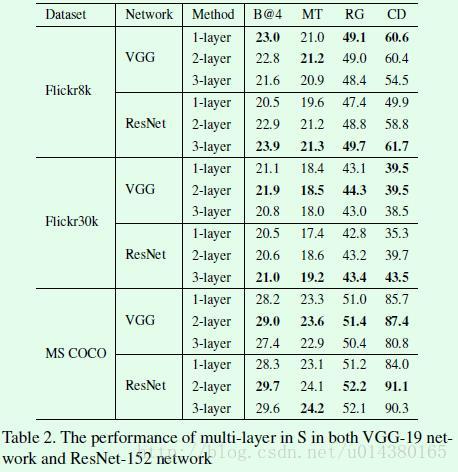
然后是multi-layer的效果,如下面的Table2和Table3所示。For VGG-19, 1-st layer, 2-nd layer, 3-rd layer represent conv5_4; conv5_3; conv5_2 conv-layer, respectively. As for ResNet-152, it represents res5c; res5c_branch2b; res5c_branch2a conv-layer. 从Table2和Table3可以看出总体上multi-layer的效果确实比单层的效果要好一些,但是同时层数过多的话也容易引起过拟合。

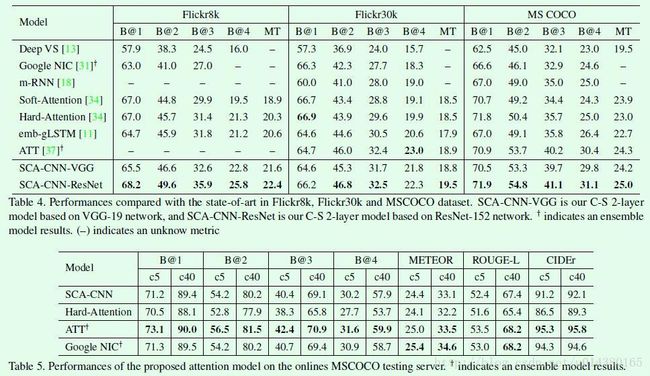
最后是SCA-CNN算法和其他image caption算法的实验对比,如Table4和Table5所示。其中Deep VS,m-RNN,Google NIC都是结合CNN和RNN的端到端网络;Soft-Attention和Hard-Attention是spatial attention模型;emb-gLSTM和ATT是semantic attention模型。在Table5中SCA-CNN的表现不如ATT和Google NIC,作者认为主要原因在于后二者都采用了模型融合的方式,一般而言融合的效果会优于单模型,只不过速度是劣势,可惜文中没有速度上的对比,不知道速度差异如何。
最后的最后奉上图像描述的效果图。
