Python爬虫——利用新浪微盘下载周杰伦的歌曲(共190首)
本篇分享将实现在新浪微盘上下载周杰伦的歌曲,一共190首,下载的网页网址为http://vdisk.weibo.com/s/arjVBmagFKiLy,页面如下:
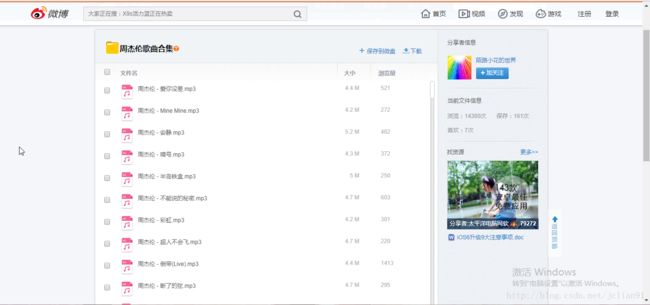
先定一个小目标:下载本页面中的所有190首歌曲!怎么样,有没有一点心动的感觉呢?哈哈,当然讲解爬虫前,需要一些准备工作:
- 安装Anaconda以及Selenium模块;
- 安装Chrome浏览器驱动
- 一些基础的Python编程知识;
- 一颗好奇的心.
首先在Anaconda官网上下载适合自己电脑的Anaconda版本。下载完后打开Anaconda Prompt,输入pip install selenium安装selenium模块。
![]()
耐心等待安装,安装完后再输入conda list selenium,如出现以下信息,则表示安装成功。

接下来安装Chrome浏览器驱动,可以在http://npm.taobao.org/mirrors/chromedriver/2.31/ 上下载,Windows系统选择chromedriver_win32.zip 文件。这是一个压缩包,解压后存到一个目录中,然后把该目录添加到环境变量。
在Spyder上运行Python程序源代码(或者在码云网站上下载Python源代码Chrome_song_download_with_Class.py),源代码如下:
import os
import re
import bs4
import time
import datetime
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.action_chains import ActionChains
class download_songs(object):
def __init__(self,url,save_file_name):
self.url = url
self.save_file_name = save_file_name
def get_song_names(self):
html = urllib.request.urlopen(self.url)
content = html.read()
html.close()
print("已获得该页面!")
soup = BeautifulSoup(content, "lxml")
print("页面解析完毕!进入歌曲下载...")
song_lst = soup.find_all('a', class_="short_name")
print("一共找到%d首歌曲!\n"% len(song_lst))
song_names = [song.string for song in song_lst]
return song_names
def get_songs(self):
#设置Chrome浏览器,并启动
chrome_options = webdriver.ChromeOptions()
# 不加载图片(提升加载速度);设置默认保存文件径路
prefs = {"profile.managed_default_content_settings.images":2,\
"download.default_directory": '%s' %self.save_file_name}
chrome_options.add_experimental_option("prefs",prefs)
browser = webdriver.Chrome(chrome_options=chrome_options) #启动浏览器
print("浏览器已启动")
song_names = self.get_song_names()
browser.maximize_window() #窗口最大化
browser.set_page_load_timeout(30) # 最大等待时间为30s
#当加载时间超过30秒后,自动停止加载该页面
try:
browser.get(self.url)
except TimeoutException:
browser.execute_script('window.stop()')
#遍历所有的tags,下载歌曲
for i in range(len(song_names)):
#当开始的12首歌下载完后,需要下拉网页内嵌的滚动条
if i >= 12:
#找到网页内嵌的滚动条
Drag = browser.find_element_by_class_name("jspDrag")
#获取滚动槽的高度
groove = browser.find_element_by_class_name("jspTrack")
height_of_groove = int(re.sub("\D","",str(groove.get_attribute("style"))))
#利用鼠标模拟拖动来下拉该滚动条
move_of_y = i * height_of_groove/len(song_names) #每次下拉的滚动条的高度
ActionChains(browser).drag_and_drop_by_offset(Drag, 0, move_of_y).perform()
elem_lst = browser.find_elements_by_class_name("short_name") #所有歌的tags
elem= elem_lst[i]
elem.click() #点击该tag,切换到该歌曲的下载页面
time.sleep(5)
button = browser.find_element_by_id("download_big_btn") #按下下载按钮
print("已找到第%d首歌: %s"%(i+1, song_names[i]))
button.click()
print("%s 正在下载中..."%song_names[i])
file_exit_flg = len(os.listdir(r"%s"%self.save_file_name))
time.sleep(8)
#歌曲是否存在处理,如果存在,输出“下载成功”,否则等待15秒,再次判断后决定是否刷新页面
if len(os.listdir(r"%s"%self.save_file_name)) == file_exit_flg +1:
print("%s 下载成功!\n"%song_names[i])
else:
exit_flag = 0 #退出标志,尝试下载5次,5次下载仍未成功后输出“下载失败!”
while True:
time.sleep(8)
if len(os.listdir(r"%s"%self.save_file_name)) == file_exit_flg +1:
print("%s 下载成功!\n"%song_names[i])
break
print("%s 下载未成功,再次尝试下载!"%song_names[i])
browser.refresh() #等待15秒后,文件还未下载,则刷新网页
time.sleep(5)
print("已刷新网页!")
#刷新网页后执行刚才的操作
button = browser.find_element_by_id("download_big_btn")
button.click()
print("%s 正在下载中..."%song_names[i])
file_exit_flg = len(os.listdir(r"%s"%self.save_file_name))
time.sleep(8)
exit_flag += 1
if exit_flag == 2:
print("%s 下载失败!\n"%song_names[i])
break
browser.back() # 网页后退
time.sleep(8)
browser.close() #操作结束,关闭Chrome浏览器
print("\n本页面操作已经结束!请前往下载位置(%s)查看下载文件. Y(^O^)Y "% self.save_file_name)
def main():
d1 = datetime.datetime.now()
#下载歌曲的网页网址
url = 'http://vdisk.weibo.com/s/arjVBmagFKiLy'
#保存文件的目录
save_file_name = "F:\music\music_of_周杰伦"
for_test = download_songs(url,save_file_name)
try:
for_test.get_songs()
except TimeoutException:
sum_of_files = len(os.listdir(save_file_name))
print("下载超时啦!!!此次操作共下载了%d首歌(可能有重复或未下载完的),到此就结束了哦 ^o^" % sum_of_files)
d2 = datetime.datetime.now()
print("开始时间:",d1)
print("结束时间:",d2)
print("一共用时:",d2-d1)
main() 笔者利用空余时间,在自己的电脑上运行后的结果如下:

190首歌曲下载花了102.5分钟,平均每首歌32.2s,运行结果还是相当可以的,how exiting!!!
该程序适合下载新浪微盘上分享的歌曲,类似于本例,这样的网址还是很多的,可以在码云网站上下载新浪微盘网址文档.txt.欢迎大家进行测试,可以单个测试,也可以写成字典dict测试。
由于笔者时间仓促和技术水平有限,代码中可能会存在一些错误和不足之处,希望广大网友能批评指导!!!欢迎大家下载代码,欢迎大家一起交流~~
注意:本人现已开通两个微信公众号: 因为Python(微信号为:python_math)以及轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~