大数据平台Hadoop 和 Spark的安装-单节点
一、软件准备
(一)ubuntu-15.10-desktop-amd64.iso 下载地址:
http://old-releases.ubuntu.com/releases/15.10/ubuntu-15.10-desktop-amd64.iso
(二)Hadoop 2.6.5 下载地址:
http://apache.stu.edu.tw/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
(三)Spark 1.6.2 下载地址:
http://spark.apache.org/downloads.html
https://archive.apache.org/dist/spark/spark-1.6.2/spark-1.6.2-bin-hadoop2.6.tgz
(四)scala-2.10.5 下载地址:
https://downloads.lightbend.com/scala/2.10.5/scala-2.10.5.tgz
二、系统架构与安装流程
(一)安装架构:
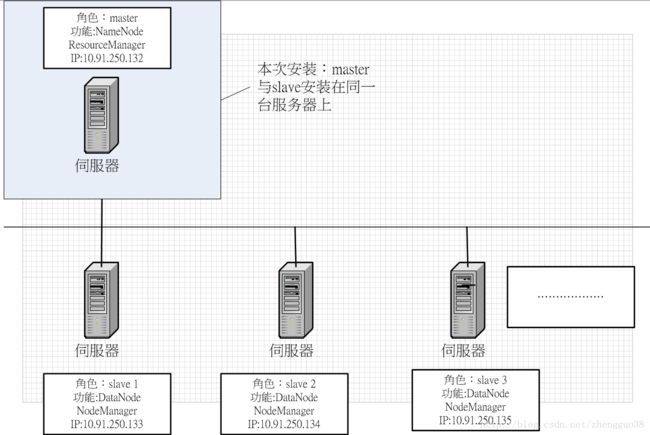
(二)安装流程:
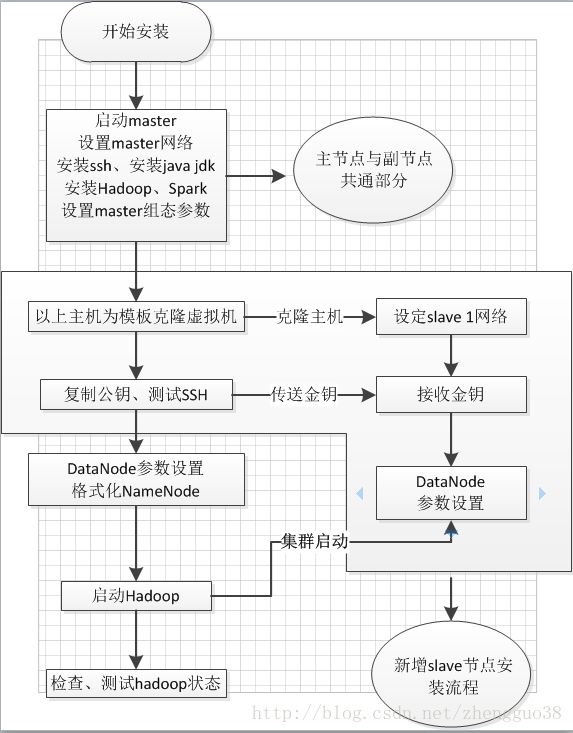
(三)本次系统安装组件:
Hadoop(包含MapReduce、HDFS、Yarn三大基本组件)、Spark、Scala
三、系统安装与设定(ubuntu)
(一)硬件配置:
测试环境配置需求:
CPU: 4V CPU 内存:4G 硬盘:100G

因为测试环境,这次安装为单机安装,主节点与副节点在同一台主机上,正式环境建议使用群集,给予更多的资源,也可以防止单点故障,加速度运算等优点。
(二)设置系统安装参数
1.选择中文(简体)、点击安装Ubuntu

2.勾选图形与第三方软件,点击继续

3.选择清除整个磁盘

4.点击继续
5.时区选择上海

6.键盘布局选择汉语,也可以选择英文,这个不影响可以后期再装

7.计算机名:master用户名:mis 密码: mis 选中自动登录

8.点击现在重启

(三)Master系统设定
1.换root用户
mis@master:~$ sudo su -
输入密码:mis
2.修改hostname为: master
root@master:~# vim /etc/hostname
3.修改hosts文件
root@master:~# vi /etc/hosts
127.0.0.1 localhost
127.0.1.1 Hadoop
10.91.250.132 master
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
4.配置网卡
root@master:~# vi /etc/network/interfaces
# interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
auto enp0s3
iface enp0s3 inet static
address 10.91.250.132
netmask 255.255.255.0
gateway 10.91.250.254
dns-nameservers 10.91.250.245
root@master:~# /etc/init.d/networking restart
重起网络服务使用网络生效,如失败则重起服务器使用网络生效
5.开启SSH( 备注:安装ssh互联网支持,所以服务器需能上外网)
(1)更改系统默认源
①备份:
root@master:~# cp /etc/apt/sources.list /etc/apt/sources.list.bak
②修改:
root@master:~# vi /etc/apt/sources.list
③源如下:
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.ustc.edu.cn/ubuntu/ xenial main restricted universe multiverse
# deb-src https://mirrors.ustc.edu.cn/ubuntu/ xenial main main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
# deb-src https://mirrors.ustc.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse deb https://mirrors.ustc.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
# deb-src https://mirrors.ustc.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
# deb-src https://mirrors.ustc.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb https://mirrors.ustc.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
# deb-src https://mirrors.ustc.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
④更新列表:
root@master:~# apt-get update
(2)安装ssh
root@master:~# apt-get install openssh-server
①产生公私钥,复制到授权档(两种方法,二选一)
1)方法一:
mis@master:~$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
mis@master:~$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
2)方法二:
mis@master:~$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
②验证ssh本机免密(第一次进入如有提示输入yes,exit后再执行以下指令)
mis@master:~$ ssh master
(3)安装vim
root@master:~# apt-get install vim
(4)安装JDK (需1.8.X及以上版本包含1.8.X)
root@master:~# apt-get -y install default-jdk
①确认java jdk版本
root@master:~# java -version
openjdk version "1.8.0_151"
OpenJDK Runtime Environment (build 1.8.0_151-8u151-b12-0ubuntu0.16.04.2-b12)
OpenJDK 64-Bit Server VM (build 25.151-b12, mixed mode)
②查询java安装路径:
root@master:~# java -version
openjdk version "1.8.0_151"
OpenJDK Runtime Environment (build 1.8.0_151-8u151-b12-0ubuntu0.16.04.2-b12)
OpenJDK 64-Bit Server VM (build 25.151-b12, mixed mode)
root@master:~# update-alternatives --display java
java - 自动模式
link best version is /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
链接目前指向 /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
link java is /usr/bin/java
slave java.1.gz is /usr/share/man/man1/java.1.gz
/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java - 优先级 1081
次要 java.1.gz:/usr/lib/jvm/java-8-openjdk-amd64/jre/man/man1/java.1.gz
路径:/usr/lib/jvm/java-8-openjdk-amd64 在后续配置中会多次使用到
(5)配置Hadoop、Spark、Scala
①传送安装包
传送压缩包到服务器,将解压的资料分别移动到:
root@master:/usr/local/hadoop# tar -zxvf hadoop-2.6.5.tar.gz
root@master:/usr/local/hadoop# tar -zxvf spark-1.6.2-bin-hadoop2.6.tgz
root@master:/usr/local/hadoop# tar -zxvf scala-2.10.5.tgz
/usr/local/hadoop
/usr/local/spark
/usr/local/scala
作为安装目录并更改安装目录为mis所拥有。
root@master:/usr/local# chown mis:mis -R /usr/local/hadoop/
root@master:/usr/local# chown mis:mis -R /usr/local/spark/
root@master:/usr/local# chown mis:mis -R /usr/local/scala/
②设置环境变量
注意:换成mis用户:要设置的是mis用户的环境变量
mis@master:~$ sudo vim ~/.bashrc
在文件最后追加以下变量:
#Java安装路径
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
#Hadoop相关路径
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
#Scala相关路径
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
#Spark相关路径
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
③执行指令,使设置生效
mis@master:~$ source ~/.bashrc
④设定Hadoop参数档
1)设定hadoop环境参数hadoop-env.sh,指定Java安装所在
mis@master:~$ sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
2)建立Hadoop的temp目录
mis@master:~$ mkdir -p /usr/local/hadoop/tmp
3)设定hadoop主机资料core-site.xml,在
mis@master:~$ sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
4)设定yarn资料yarn-site.xml,在
mis@master:~$ sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
5)产生MapReduce设定档
mis@master:~$sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
6)设定MapReduce设定档mapred-site.xml,在
mis@master:~$ sudo vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
7)name node和data node设定,建立相应目录
mis@master:~$ mkdir -p /usr/local/hadoop/data/hdfs/namenode
mis@master:~$ mkdir -p /usr/local/hadoop/data/hdfs/datanode
8)设定hdfs份数和name node目录和data node目录,在
mis@master:~$ sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
9)格式化name node
mis@master:~$ hdfs namenode -format
10)启动hdfs和yarn(两种方法)
a.方法一: 同时启动
mis@master:~$ start-all.sh

第一次运行会出现提示:输入yes,输入密码(重复三次)
b.方法二: 分两步启动
mis@master:~$ start-dfs.sh
mis@master:~$ start-yarn.sh
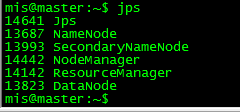
c.查看process
mis@master:~$ jps
(6)安装Scala 2.10.5
在以上:4.1与4.2中已经安装,主要是传送到指定目录,再设置环境变量,使其生效。
四、相关网址
http://10.91.250.131:50070

http://10.91.250.131:8088
