利用层次聚类算法进行基于基站定位数据的商圈分析
1. 背景与挖掘目标
1.1 背景
随着个人手机和网络的普及,手机已经基本成为所有人必须持有的工具。
根据手机信号再地理空间的覆盖情况结合时间序列的手机定位数据可以完整的还原人群的现实活动轨迹从而得到人口空间分布于活动联系的特征信息。
商圈是现代市场中的重要企业活动空间,商圈划分的目的之一是为了研究潜在的顾客分布,以制定适宜的商业对策。
本次数据,是由通信运营商提供的,特定接口解析得到的用户定位数据。
1.2 挖掘目标
对用户的历史定位数据,采用数据挖掘技术,对基站进行分群
对不同的商圈分群进行特征分析,比较不同商圈类别的价值,选择合适区域进行针对性的营销活动
2. 分析方法与过程
2.1 分析方法与步骤
通过数据是由通信运营商提供,可以推测手机用户在使用短信业务、通话业务和上网业务等信息时产生的定位数据。
由于数据中是由不同基站作为位置的辨别,可以将每个基站当做一个”商圈“,再通过归纳基站范围的人口特征,运用聚类算法,识别不同类别的基站范围,即可等同识别不同类别的商圈。
衡量区域人口特征,可以从人流量和人均停留时间的角度进行分析。
步骤设计:
从移动通信运营商提供的特定接口进行解析、处理和过滤后得到用户定位数据
以单个用户为例子,进行数据探索分析,研究人口特征,以便于后续数据规约和数据变化的处理方向。
利用步骤2形成的已完成数据预处理的建模数据,基于基站覆盖范围区域的人流特征进行商圈聚类
对分类结果中的各个商圈,进行特征分析,并且选择合适的商业计划。
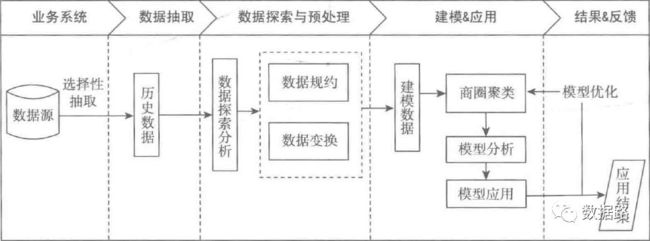
分析流程:
2.2 数据抽取
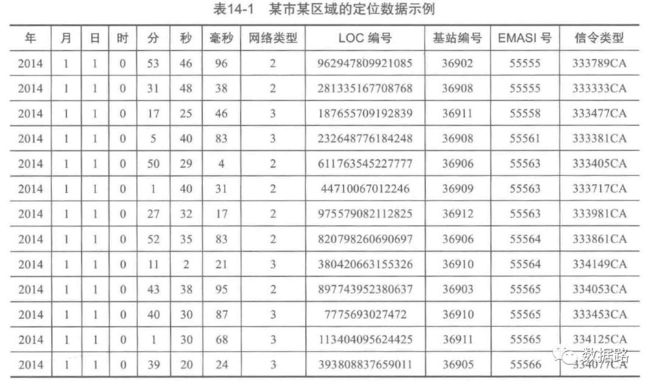
从移动通信运营商提供的特定接口上解析、处理和过滤后,获得位置数据。时间设定为,2014-1-1为开始时间,2014-6-30为结束时间作为分析的观测窗口,抽取窗口内某市某区域的定位数据形成建模数据。
2.3 数据探索分析
为了便于观察数据,先提取用户的ID即EMASI号为”55555“的用户再2014年1月1号的定位数据。
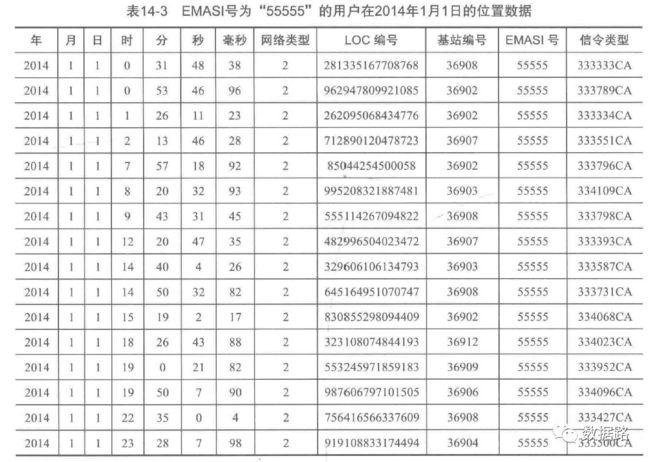
2. 观察数据,可以发现,两条数据可能是同一基站的不同时间。

2.4 数据预处理
2.4.1 数据规约
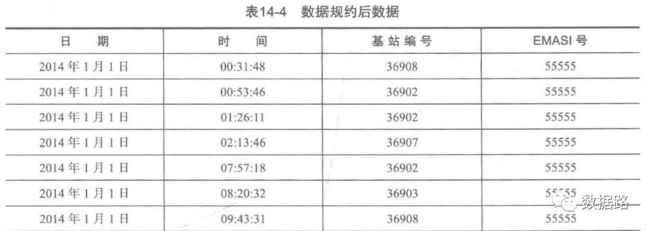
原始数据的属性较多,由我们的挖掘目标,网络类型、LOC编号和信令类型这三个属性没有作用,剔除。衡量用户停留时间,没有必要精确到毫秒,故一同删除。
在计算用户的停留时间,只计算两条记录的时间差,为了减少数据维度,把年月日合并为日期,时分秒合并为时间,得到数据。
2.4.2 数据变换
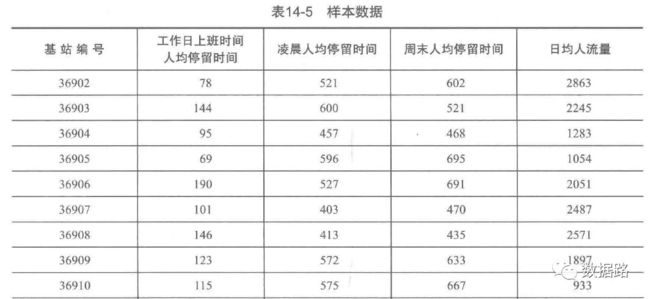
挖掘的目标是寻找高价值的商圈,需要根据用户的定位数据,提取出基站范围内区域的人流特征,如人均停留时间和人流等。
高价值商圈,在人流特征上有,人流量大和人均停留时间长的特点。
写字楼的上班族在白天所处基站范围固定,时间也较长,人流量也大。居住区,也有基站范围固定,时间长,人流量大的特点。所以,单纯的停留时间无法判断商圈类别。
现代社会工作,以一周为一个工作小周期,分为工作日和周末。一天中,分为上班时间和下班时间。
综上所述,设计人流特征的四个指标,工作日上班时间人均停留时间、凌晨人均停留时间、周末人均停留时间和日均人流量。
工作日上班时间人均停留时间,意思是所有用户在上班时间9:00~18:00处在该基站范围内的平均时间
凌晨人均停留时间,意思是所有用户在凌晨时间00:00~07:00处在该基站范围的平均时间
周末人均停留时间,如上类推。日均人流量,指的是平均每天曾经在该基站范围内的人数。
这四个指标的计算,直接从原始数据计算比较复杂,需要先处理成中间数据,再从中计算得出四个指标。对于基站1,有以下公式,再带入所有基站,得出结果。
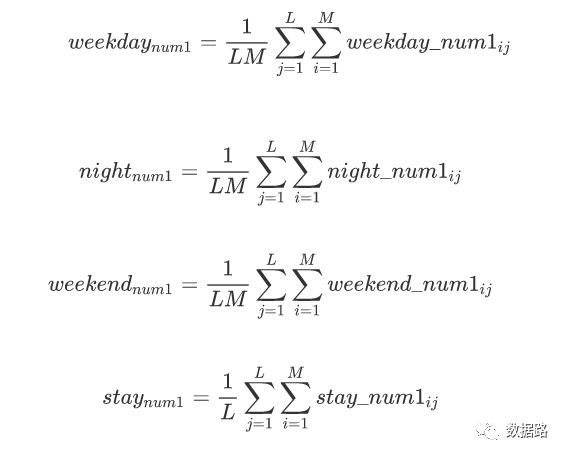
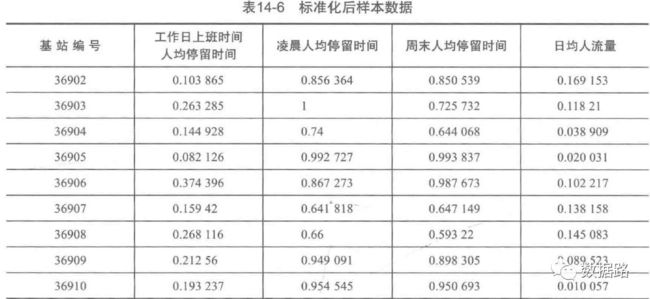
由于各个属性之间的差异较大。为了消除数量级数据带来的影响,在聚类之前,需要进行离差标准化处理,离差标准化处理的代码如下,得到建模的样本数据。
#-*- coding: utf-8 -*-
#数据标准化到[0,1]
import pandas as pd
#参数初始化
filename = '../data/business_circle.xls' #原始数据文件
standardizedfile = '../tmp/standardized.xls' #标准化后数据保存路径
data = pd.read_excel(filename, index_col = u'基站编号') #读取数据
data = (data - data.min())/(data.max() - data.min()) #离差标准化
data = data.reset_index()
data.to_excel(standardizedfile, index = False) #保存结果
print('OK')
标准化后数据:
2.5 模型构建
2.5.1 构建商圈聚类模型
数据进行预处理以后,已经形成了建模数据。这次聚类,采用层次聚类算法,对建模数据进行基于基站数据的商圈聚类,画出谱系聚类图,代码如下。
#-*- coding: utf-8 -*-
#谱系聚类图
import pandas as pd
#参数初始化
standardizedfile = '../data/standardized.xls' #标准化后的数据文件
data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import linkage,dendrogram
#这里使用scipy的层次聚类函数
Z = linkage(data, method = 'ward', metric = 'euclidean') #谱系聚类图
P = dendrogram(Z, 0) #画谱系聚类图
plt.show()
2. 根据代码,得到谱系聚类图,如图。

3. 从图中可以看出,可以把聚类类别数取3类,再使用层次聚类算法进行训练模型,代码如下。
#-*- coding: utf-8 -*-
#层次聚类算法
import pandas as pd
#参数初始化
standardizedfile = '../data/standardized.xls' #标准化后的数据文件
k = 3 #聚类数
data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据
from sklearn.cluster import AgglomerativeClustering #导入sklearn的层次聚类函数
model = AgglomerativeClustering(n_clusters = k, linkage = 'ward')
model.fit(data) #训练模型
#详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别
r.columns = list(data.columns) + [u'聚类类别'] #重命名表头
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
style = ['ro-', 'go-', 'bo-']
xlabels = [u'工作日人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量']
pic_output = '../tmp/type_' #聚类图文件名前缀
for i in range(k): #逐一作图,作出不同样式
plt.figure()
tmp = r[r[u'聚类类别'] == i].iloc[:,:4] #提取每一类
for j in range(len(tmp)):
plt.plot(range(1, 5), tmp.iloc[j], style[i])
plt.xticks(range(1, 5), xlabels, rotation = 20) #坐标标签
plt.title(u'商圈类别%s' %(i+1)) #我们计数习惯从1开始
plt.subplots_adjust(bottom=0.15) #调整底部
plt.savefig(u'%s%s.png' %(pic_output, i+1)) #保存图片
最后获得结果:


2.5.2 模型分析
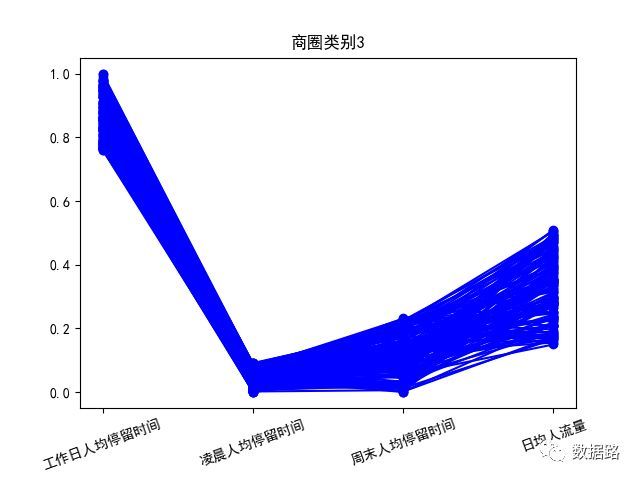
针对聚类结果,按不同类别画出了3个特征的折线图,如图。
商圈类别1,工作日人均停留时间、凌晨人均停留时间都很低,周末人均停留时间中等,日均人流量极高,这符合商业区的特点。
商圈类别2,工作日人均停留时间中等,凌晨和周末人均停留时间很长,日均人流量较低,这和居住区的特征符合
商圈类别3,这部分工作日人均停留时间很长,凌晨和周末停留较少,日均人流量中等,这和办公商圈非常符合。
3. 总结
3.1 实验思考与总结
在得到基础的建模数据后,通过数据标准化,消除了数量级数据带来的影响,本案例采用离差标准化。除此之外,还有其他标准化方法吗?各自的使用范围与作用由哪些?
本文通过聚类进行了分类,如何通过聚类结果反推得到实际现实中商圈地理位置呢?
两个算法模型中,采用的是scipy.cluster和sklearn.cluster这两个库。针对构建层次聚类模型,
4. form sklearn import AgglomerativeClustering 引用这个方法时,由method和metric两个参数,参数的选择由哪些?还能进行怎样的改变呢?对模型的影响又有哪些?
5. 聚类算法得出模型后,怎样能检测模型的效果呢?如何再进一步优化聚类结果?
希望各位看客们,在对待如上疑问有答案或者思路的话,欢迎多多讨论,希望能更加完善!
3.2 文章总结
本案例是《Python数据分析与挖掘实战》中的一个有关商圈商业案例的一个,贴合我们实际的生活,所以更加有兴趣解决它。
得到商圈类别以后,反推得到商圈地理位置后,就能根据商业的特点,进行相应的商业活动,比如办公区附近可以开办快餐店等,但是,与此同时又牵扯处另外一个问题,通过该商圈特征能得到用户的需要,那目前该商圈的供给情况是如何也非常重要!这需要寻找数据,建模,得到相应的情况。最后,在结合商圈服务供给和服务需求后,找到需求比供给多最多的那一个类别,在这个类别上进行商业活动开展会取得好效果。再进一步,商业活动,也能分为不同价格水平的服务供给,可以再通过该商圈的收入水平分布,而找到能使得总利润最大化的商业服务。
同时,在遇到公式的书写时,发现了Latex语法,查询以后发现还是论文的通用形式,练习了一下Latex的简单书写,以后的公式都尽量用这个办法呈现。
赞赏作者

本文作者
❈无小意,Python中文社区专栏作者,知乎:无小意丶,金融学在读学生,从零开始自学Python以及相关的数据技能,对于Python学习,只想说别犹豫。
blog:http://blog.csdn.net/weixin_39722361
❈