torch学习
对于自动求导的理解:https://blog.csdn.net/qjk19940101/article/details/79557204
对nn.Linear的理解: https://blog.csdn.net/dss_dssssd/article/details/82977170
torch.arange
torch.arange(start, end, step=1, out=None) → Tensor
返回一个1维张量,长度为 floor((end−start)/step)。包含从start到end,以step为步长的一组序列值(默认步长为1)。
参数:
- start (float) – 序列的起始点
- end (float) – 序列的终止点
- step (float) – 相邻点的间隔大小
- out (Tensor, optional) – 结果张量
例子:
>>> torch.arange(1, 4)
1
2
3
[torch.FloatTensor of size 3]
>>> torch.arange(1, 2.5, 0.5)
1.0000
1.5000
2.0000
[torch.FloatTensor of size 3]
torch.ones
torch.ones(*sizes, out=None) → Tensor
返回一个全为1 的张量,形状由可变参数sizes定义。
参数:
- sizes (int…) – 整数序列,定义了输出形状
- out (Tensor, optional) – 结果张量 例子:
>>> torch.ones(2, 3)
1 1 1
1 1 1
[torch.FloatTensor of size 2x3]
>>> torch.ones(5)
1
1
1
1
1
[torch.FloatTensor of size 5]
torch.normal()
torch.normal(means, std, out=None)
返回一个张量,包含从给定参数means,std的离散正态分布中抽取随机数。 均值means是一个张量,包含每个输出元素相关的正态分布的均值。 std是一个张量,包含每个输出元素相关的正态分布的标准差。 均值和标准差的形状不须匹配,但每个张量的元素个数须相同。
参数:
- means (Tensor) – 均值
- std (Tensor) – 标准差
- out (Tensor) – 可选的输出张量
torch.normal(means=torch.arange(1, 11), std=torch.arange(1, 0, -0.1))
1.5104 #从N(1,1)中抽取随机数
1.6955 #从N(2,0.9)中抽取随机数
2.4895 #从N(3,0.8)抽取随机数
4.9185
4.9895
6.9155
7.3683
8.1836
8.7164
9.8916 #从N(9,0.1中抽取随机数)
[torch.FloatTensor of size 10]
Linear layers
class torch.nn.Linear(in_features, out_features, bias=True)
对输入数据做线性变换:y=Ax+b
参数:
- in_features - 每个输入样本的大小
- out_features - 每个输出样本的大小
- bias - 若设置为False,这层不会学习偏置。默认值:True
形状:
- 输入 (N,in_features)
- 输出: (N,out_features)
变量:
- weight -形状为(out_features x in_features)的模块中可学习的权值
- bias -形状为(out_features)的模块中可学习的偏置
例子:
>>> m = nn.Linear(20, 30)
>>> input = autograd.Variable(torch.randn(128, 20))
>>> output = m(input)
>>> print(output.size())
torch.nn.GRU(*args, **kwargs)
对于输入序列中的每个元素,每个层都按以下函数计算:
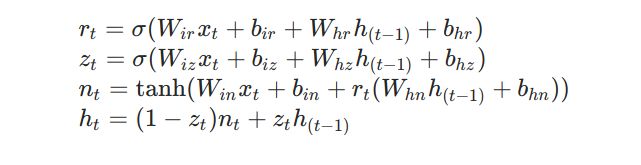
z t z_t zt是更新门, r t r_t rt控制 h t h_t ht的下一个候选值 n t n_t nt与 h t − 1 h_{t-1} ht−1有多大的相关性, n t n_t nt是候选值, h t h_t ht是t时刻的隐藏层状态
参数说明:
- input_size – 期望的输入 x x x的特征值的维度
- hidden_size – 隐状态的维度
- num_layers – RNN的层数。
- bias – 如果为False,那么RNN层将不会使用bias,
默认为True。 - batch_first – 默认网络输入是按照 (seq , batch, feature) 输入的,也就是序列长度放在最前面,然后是批量,最后是特征维度。如果为True的话,那么输入和输出的tensor的形状是(batch, seq, feature)。
默认为False - dropout – 如果非零的话,将会在RNN的输出上加个dropout层,最后一层除外。其丢失概率等于参数
dropout,该参数的默认值为0。
注:dropout层可以防止训练过拟合
丢失概率的意思是,若丢失概率为p,则每一个输出节点以概率 p 置0(不工作) - bidirectional – 如果为True,将会变成一个双向RNN,默认为False。
Inputs: input, h_0
- input (seq_len, batch, input_size): 包含输入序列特征的Tensor,也可以是
packed variable。 - h_0 (num_layers * num_directions, batch, hidden_size):保存着batch中每个元素的初始化隐状态的Tensor。如果未提供,则默认为零。如果RNN是双向的,则num_directions应为2,否则应为1。
Outputs: output, h_n
- output (seq_len, batch, hidden_size * num_directions): 对于每个t,包含来自GRU的最后一层的输出特征h_t的tensor。如果输入是
torch.nn.utils.rnn.PackedSequence,那么输出也是torch.nn.utils.rnn.PackedSequence。 - h_n (num_layers * num_directions, batch, hidden_size): Tensor,保存着RNN最后一个时间步的隐状态。
变量:
weight_ih_l[k] – 第k层可学习的input-hidden权重( W i r ∣ W i i ∣ W i n W_{ir}|W_{ii}|W_{in} Wir∣Wii∣Win),形状为(input_size x 3*hidden_size)
weight_hh_l[k] – 第k层可学习的hidden-hidden权重( W h r ∣ W h i ∣ W h n W_{hr}|W_{hi}|W_{hn} Whr∣Whi∣Whn),形状为(hidden_size x 3*hidden_size)。
bias_ih_l[k] – 第k层可学习的input-hidden偏置( b i r ∣ b i i ∣ b i n b_{ir}|b_{ii}|b_{in} bir∣bii∣bin),形状为( 3*hidden_size)
bias_hh_l[k] – 第k层可学习的hidden-hidden偏置( b h r ∣ b h i ∣ b h n b_{hr}|b_{hi}|b_{hn} bhr∣bhi∣bhn),形状为( 3*hidden_size)。
例子:
>>> rnn = nn.GRU(10, 20, 2)
>>> input = torch.randn(5, 3, 10)
>>> h0 = torch.randn(2, 3, 20)
>>> output, hn = rnn(input, h0)
torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=False)
这里的pack,理解成压紧比较好。 将一个 填充过的变长序列 压紧。(填充时候,会有冗余,所以压紧一下)
输入的形状可以是(T×B×* )。T是最长序列长度,B是batch size,*代表任意维度(可以是0)。如果batch_first=True的话,那么相应的 input size 就是 (B×T×*)。
Variable中保存的序列,应该按序列长度的长短排序,长的在前,短的在后。即input[:,0]代表的是最长的序列,input[:, B-1]保存的是最短的序列。
NOTE: 只要是维度大于等于2的input都可以作为这个函数的参数。你可以用它来打包labels,然后用RNN的输出和打包后的labels来计算loss。通过PackedSequence对象的.data属性可以获取 Variable。
参数说明:
-
input (
Variable) – 变长序列 被填充后的 batch -
lengths (
list[int]) –Variable中 每个序列的长度。 -
batch_first (bool, optional) – 如果是
True,input的形状应该是B*T*size。
返回值:
一个PackedSequence 对象。
torch.nn.utils.rnn.pad_packed_sequence(sequence, batch_first=False)
填充packed_sequence。
上面提到的函数的功能是将一个填充后的变长序列压紧。 这个操作和pack_padded_sequence()是相反的。把压紧的序列再填充回来。
返回的Varaible的值的size是 T×B×*, T 是最长序列的长度,B 是 batch_size,如果 batch_first=True,那么返回值是B×T×*。
Batch中的元素将会以它们长度的逆序排列。即填充前长的序列在前
参数说明:
sequence (PackedSequence) – 将要被填充的 batch
batch_first (bool, optional) – 如果为True,返回的数据的格式为 B×T×*。
返回值: 一个tuple,包含被填充后的序列,和batch中序列的长度列表。
注:不管 batch_first 是否是True,都会输出这个长度列表, 即输出填充前每个批次的长度。这里的长度指的是行数。
示例代码:
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.nn import utils as nn_utils
batch_size = 2
max_length = 3
hidden_size = 2
n_layers =1
tensor_in = torch.FloatTensor([[1, 2, 3], [1, 0, 0]]).resize_(2,3,1)
tensor_in = Variable( tensor_in ) #[batch, seq, feature], [2, 3, 1]
seq_lengths = [3,1] # list of integers holding information about the batch size at each sequence step
# pack it
pack = nn_utils.rnn.pack_padded_sequence(tensor_in, seq_lengths, batch_first=True)
# initialize
rnn = nn.RNN(1, hidden_size, n_layers, batch_first=True)
h0 = Variable(torch.randn(n_layers, batch_size, hidden_size))
#forward
out, _ = rnn(pack, h0)
# unpack
unpacked = nn_utils.rnn.pad_packed_sequence(out)
print(unpacked)
select(dim, index) → Tensor or number
在给定索引处沿选定维度切片,此函数返回给定维度的索引位置的张量。
关于维度这个概念,请参看这个
参数:
- dim (int)-切片的维度
- index (int)-用来选取的索引
注意: select()等效于切片。例如,tensor.select(0, index)等效于tensor[index],tensor.select(2, index)等效于tensor[:, :, index].
class torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2, scale_grad_by_freq=False, sparse=False)
一个保存了固定字典和大小的简单查找表。
这个模块常用来保存词嵌入和用下标检索它们。模块的输入是一个下标的列表,输出是对应的词嵌入。
参数:
- num_embeddings (
int) - 嵌入字典的大小
注意:这里字典的大小的意思是,输入向量的值要小于字典大小,即范围在0~num_embeddings-1之间 - embedding_dim (
int) - 每个嵌入向量的 size - padding_idx (
int, optional) - 如果提供的话,输出遇到此值时其嵌入向量为零向量 - max_norm (
float, optional) - 如果提供的话,会重新归一化词嵌入,使它们的范数小于提供的值 - norm_type (
float, optional) - 对于max_norm选项计算p范数时的p - scale_grad_by_freq (
boolean, optional) - 如果提供的话,会根据字典中单词频率缩放梯度
变量:
- weight (Tensor) -形状为(num_embeddings, embedding_dim)的模块中可学习的权值
形状:
- 输入: LongTensor (N, W), N = mini-batch, W = 每个mini-batch中提取的下标数
- 输出: (N, W, embedding_dim)