Hadoop实验三——熟悉常用的HBase操作
- 编程实现以下指定功能,并用Hadoop提供的HBase Shell命令完成相同任务:
(1) 列出HBase所有的表的相关信息,例如表名、创建时间等;
Shell命令实现:
list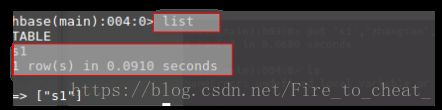
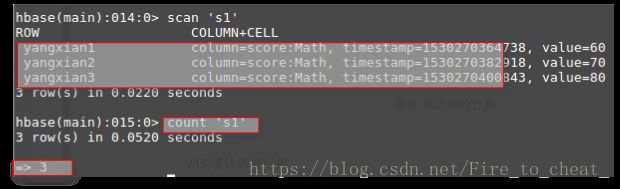
(2) 在终端打印出指定的表的所有记录数据;
scan 's1'
(3) 向已经创建好的表添加和删除指定的列族或列;
- 在s1表中添加数据
put 's1','yangxian','score:Math','60'
- 在s1表中,删除指定列
delete 's1','yangxian','score:Math'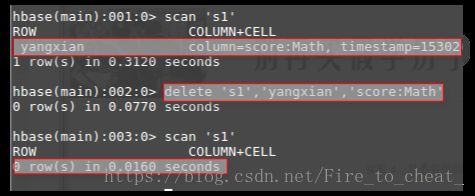
(4) 清空指定的表的所有记录数据;
truncate 's1'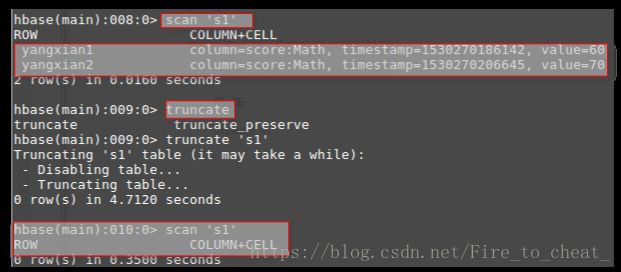
(5) 统计表的行数。
2. 现有以下关系型数据库中的表和数据,要求将其转换为适合于HBase存储的表并插入数据:
学生表(Student)
| 学号(S_No) | 姓名(S_Name) | 性别(S_Sex) | 年龄(S_Age) |
|---|---|---|---|
| 2015001 | Zhangsan | male | 23 |
| 2015003 | Mary | female | 22 |
| 2015003 | Lisi | male | 24 |
课程表(Course)
| 课程号(C_No) | 课程名(C_Name) | 学分(C_Credit) |
|---|---|---|
| 123001 | Math | 2.0 |
| 123002 | Computer Science | 5.0 |
| 123003 | English | 3.0 |
选课表(SC)
| 学号(SC_Sno) | 课程号(SC_Cno) | 成绩(SC_Score) |
|---|---|---|
| 2015001 | 123001 | 86 |
| 2015001 | 123003 | 69 |
| 2015002 | 123002 | 77 |
| 2015002 | 123003 | 99 |
| 2015003 | 123001 | 98 |
| 2015003 | 123002 | 95 |
- 学生Student表
创建表
create 'Studet','S_No','S_Name','S_Sex','S_Age'插入数据
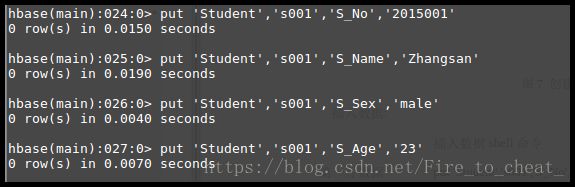
第一行数据:
put 'Student','s001','S_No','2015001'
put 'Student','s001','S_Name','Zhangsan'
put 'Student','s001','S_Sex','male'
put 'Student','s001','S_Age','23'
第二行数据:
put 'Student','s002','S_No','2015002'
put 'Student','s002','S_Name','Mary'
put 'Student','s002','S_Sex','female'
put 'Student','s002','S_Age','22'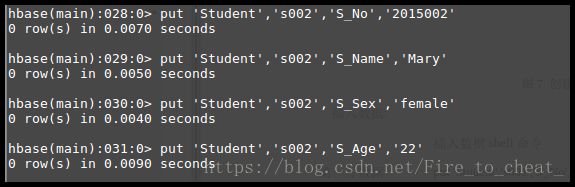
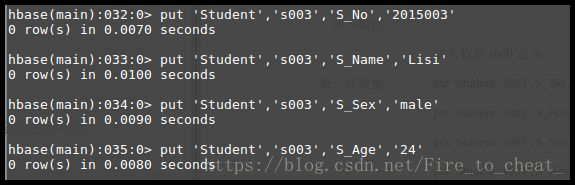
第三行数据:
put 'Student','s003','S_No','2015003'
put 'Student','s003','S_Name','Lisi'
put 'Student','s003','S_Sex','male'
put 'Student','s003','S_Age','24'
- 课程Course表
create 'Course','C_No','C_Name','C_Credit'插入数据:
put 'Course','c001','C_No','123001'
put 'Course','c001','C_Name','Math'
put 'Course','c001','C_Credit','2.0'
put 'Course','c002','C_No','123002'
put 'Course','c002','C_Name','Computer'
put 'Course','c002','C_Credit','5.0'
put 'Course','c003','C_No','123003'
put 'Course','c003','C_Name','English'
put 'Course','c003','C_Credit','3.0'
- 选课表
创建表:create 'SC','SC_Sno','SC_Cno','SC_Score'
插入数据:
put 'SC','sc001','SC_Sno','2015001'
put 'SC','sc001','SC_Cno','123001'
put 'SC','sc001','SC_Score','86'
put 'SC','sc002','SC_Sno','2015001'
put 'SC','sc002','SC_Cno','123003'
put 'SC','sc002','SC_Score','69'
put 'SC','sc003','SC_Sno','2015002'
put 'SC','sc003','SC_Cno','123002'
put 'SC','sc003','SC_Score','77'
put 'SC','sc004','SC_Sno','2015002'
put 'SC','sc004','SC_Cno','123003'
put 'SC','sc004','SC_Score','99'
put 'SC','sc005','SC_Sno','2015003'
put 'SC','sc005','SC_Cno','123001'
put 'SC','sc005','SC_Score','98'
put 'SC','sc006','SC_Sno','2015003'
put 'SC','sc006','SC_Cno','123002'
put 'SC','sc006','SC_Score','95'
同时,请编程完成以下指定功能:
(1)createTable(String tableName, String[] fields)
创建表,参数tableName为表的名称,字符串数组fields为存储记录各个域名称的数组。要求当HBase已经存在名为tableName的表的时候,先删除原有的表,然后再创建新的表。
建立person表,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
public class CreateTable {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void createTable(String tableName, String[] fields) throws IOException {
init();
TableName tablename = TableName.valueOf(tableName);
if (admin.tableExists(tablename)) {
System.out.println("table is exists!");
admin.disableTable(tablename);
admin.deleteTable(tablename);
}
HTableDescriptor hTableDescriptor = new HTableDescriptor(tablename);
for (String str : fields) {
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(str);
hTableDescriptor.addFamily(hColumnDescriptor);
}
admin.createTable(hTableDescriptor);
close();
}
public static void init() {
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir", "hdfs://localhost:9000/hbase");
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void close() {
try {
if (admin != null) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String[] fields = {"Score"};
try {
createTable("person", fields);
} catch (IOException e) {
e.printStackTrace();
}
}
}
eclipse运行结果中可以看出,创建前不存在person表,故创建person,我们可以去HBase中查看结果:
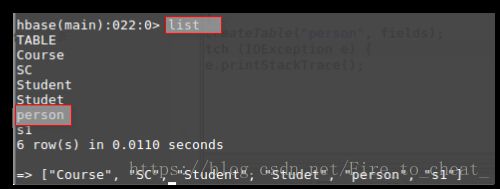
表明创建成功!
如果再次运行代码,可以看一下运行结果:
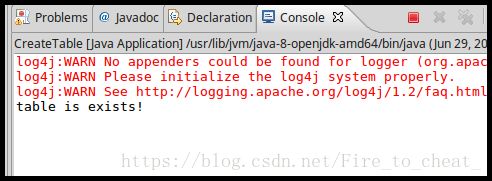
可以看出,刚才已经创建过表,所以现实结果提醒“Table is exits”
(2)addRecord(String tableName, String row, String[] fields, String[] values)
向表tableName、行row(用S_Name表示)和字符串数组files指定的单元格中添加对应的数据values。其中fields中每个元素如果对应的列族下还有相应的列限定符的话,用“columnFamily:column”表示。例如,同时向“Math”、“Computer Science”、“English”三列添加成绩时,字符串数组fields为{“Score:Math”,”Score;Computer Science”,”Score:English”},数组values存储这三门课的成绩。
增加记录,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.io.IOException;
public class AddRecord {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void addRecord(String tableName, String row, String[] fields, String[] values) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
for (int i = 0; i != fields.length; i++) {
Put put = new Put(row.getBytes());
String[] cols = fields[i].split(":");
put.addColumn(cols[0].getBytes(), cols[1].getBytes(), values[i].getBytes());
table.put(put);
}
table.close();
close();
}
public static void init() {
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir", "hdfs://localhost:9000/hbase");
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void close() {
try {
if (admin != null) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String[] fields = {"Score:Math", "Score:Computer Science", "Score:English"};
String[] values = {"99", "80", "100"};
try {
addRecord("person", "Score", fields, values);
} catch (IOException e) {
e.printStackTrace();
}
}
}
可以看到结果没有返回错误,数据插入成功!,我们可以去HBase验证一下:

可以看到我们刚才的程序运行数据插入成功。
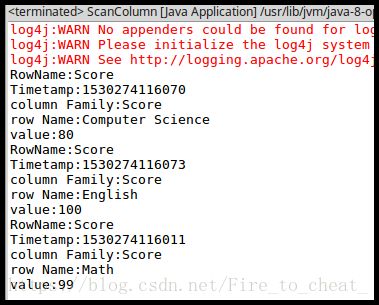
(3)scanColumn(String tableName, String column)
浏览表tableName某一列的数据,如果某一行记录中该列数据不存在,则返回null。要求当参数column为某一列族名称时,如果底下有若干个列限定符,则要列出每个列限定符代表的列的数据;当参数column为某一列具体名称(例如“Score:Math”)时,只需要列出该列的数据。
浏览某一列数据,我们可以浏览score一列的数据,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class ScanColumn {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void scanColumn(String tableName, String column) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(column));
ResultScanner scanner = table.getScanner(scan);
for (Result result = scanner.next(); result != null; result = scanner.next()) {
showCell(result);
}
table.close();
close();
}
public static void showCell(Result result) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println("RowName:" + new String(CellUtil.cloneRow(cell)) + " ");
System.out.println("Timetamp:" + cell.getTimestamp() + " ");
System.out.println("column Family:" + new String(CellUtil.cloneFamily(cell)) + " ");
System.out.println("row Name:" + new String(CellUtil.cloneQualifier(cell)) + " ");
System.out.println("value:" + new String(CellUtil.cloneValue(cell)) + " ");
}
}
public static void init() {
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir", "hdfs://localhost:9000/hbase");
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
// 关闭连接
public static void close() {
try {
if (admin != null) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
scanColumn("person", "Score");
} catch (IOException e) {
e.printStackTrace();
}
}
}
(4)modifyData(String tableName, String row, String column)
修改表tableName,行row(可以用学生姓名S_Name表示),列column指定的单元格的数据。
修改某一个数据,我们可以把数学分数修改成100,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.io.IOException;
public class ModifyData {
public static long ts;
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void modifyData(String tableName, String row, String column, String val) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(row.getBytes());
Scan scan = new Scan();
ResultScanner resultScanner = table.getScanner(scan);
for (Result r : resultScanner) {
for (Cell cell : r.getColumnCells(row.getBytes(), column.getBytes())) {
ts = cell.getTimestamp();
}
}
put.addColumn(row.getBytes(), column.getBytes(), ts, val.getBytes());
table.put(put);
table.close();
close();
}
public static void init() {
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir", "hdfs://localhost:9000/hbase");
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void close() {
try {
if (admin != null) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
modifyData("person", "Score", "Math", "100");
} catch (IOException e) {
e.printStackTrace();
}
}
}

程序运行结果没有异常,我们可以从HBase验证是否修改成功:
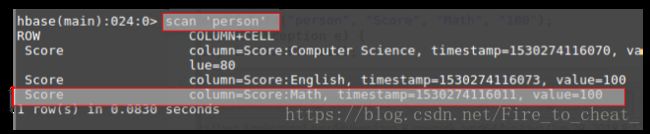
可以看出,数据修改成功!
(5)deleteRow(String tableName, String row)
删除表tableName中row指定的行的记录。
删除person表中的score行的记录,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class DeleteRow {
public static long ts;
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void deleteRow(String tableName, String row) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete=new Delete(row.getBytes());
table.delete(delete);
table.close();
close();
}
public static void init() {
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir", "hdfs://localhost:9000/hbase");
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void close() {
try {
if (admin != null) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
deleteRow("person", "Score");
} catch (IOException e) {
e.printStackTrace();
}
}
}
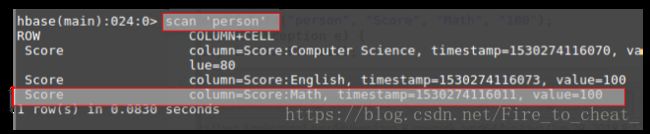
可以看到程序运行成功,没有异常,我们可以从HBase验证是否成功。
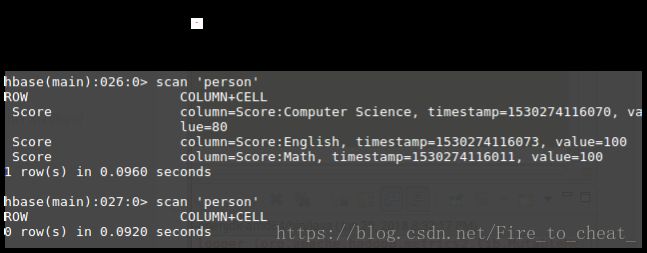
对比运行前和运行后的结果,可以看出删除一行数据成功!
- 利用HBase和MapReduce完成如下任务:
假设HBase有2张表,表的逻辑视图及部分数据如下所示:
表 逻辑视图及部分数据
| 书名(bookName) | 价格(price) |
|---|---|
| Database System Concept | 30$ |
| Thinking in Java | 60$ |
| Data Mining | 25$ |
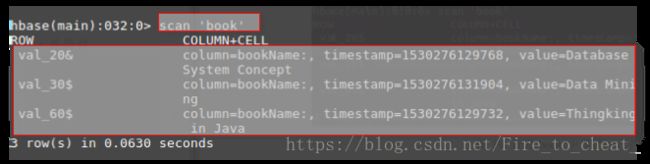
要求:从HBase读出上述两张表的数据,利用MapReduce完成对“price”的排序,并将结果存储到HBase中。HBase中的每一行的行键用“bookName”表示。
操作过程如下:
create 'book','bookName'
put 'book','val_60$','bookName','Thingking in Java'
put 'book','val_20&','bookName','Database System Concept'
put 'book','val_30$','bookName','Data Mining'scan查询所有数据,就会按照rowkey自动排序