Hadoop的资源调度器-Yarn的资源调度器的探索(一)
要去阐述Yarn的任务调度的机制,其实就该先从Yarn的架构,以及基本组成结构开始说;
Yarn是Hadoop-2.x之后出现的,实在MRv1的基础上演化而来的,它克服了MRv1中的各种局限性,在正式介绍Yarn之前就需要我们先了解以下MRv1的局限性,可以概括为以下几个方面;
1;扩展性差;在MRv1中JobTracker同时兼备了资源管理和作业控制的两个功能,这成为系统的一个最大瓶颈,严重制约了Hadoop集群的扩展性
2;可靠性差;MRv1采用了master/slave的结构,其中master存在单点故障,一旦他出现问题,就将导致整个集群不可用
3;资源利用率差;采用基于槽位的资源分配模型,槽位是一种粗粒度的资源化分单元,通常一个任务并不会将自己所占有的槽位的所有资源用完,且其他任务也无法使用这些并未被使用的空闲空间。此外hadoop将槽位分为map槽位和reduce槽位,且不允许他们之间进行共享,常常会导致一种槽位资源紧张但是另外一种闲置。
4;无法支持多种计算框架;随着互联网高速发展,MR这种基于磁盘的离线计算框架已经不能满足应用要求,从而出现一些新的内存计算框架spark,流式计算框架storm,flink等,而MRv1不能支持多种计算框架并存
为了克服以上的几个缺点,MRv2就诞生了,正式由于MRv2将资源管理功能抽象成了一个独立的通用系统,直接导致下一代mapReduce的核心重单一的计算框架MapReduce转移为通用的资源管理系统YRAN(可插拔替换的资源管理系统-》例子,spark的standalone模式,和onYarn的模式的切换)
yarn的基本架构如下图所示;
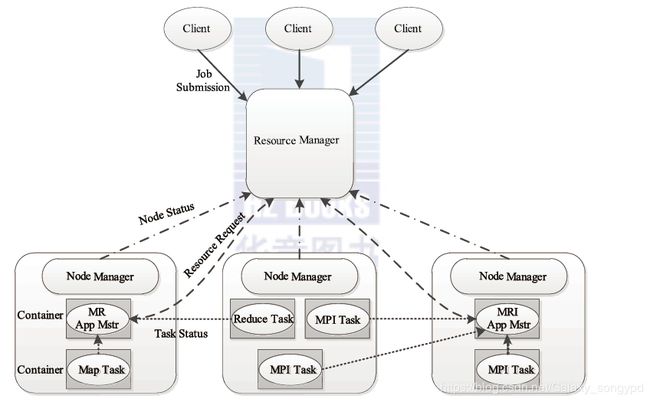
YARN的总体是仍然是Master/slave的结构,在整个资源管理框架中RM为Master,NM为slave。RM负责对各个NM上的资源进行统一管理和调度,当用户提交一个应用程序时,需要提供一个用以跟中和管理这个程序的AM,他负责向RM申请资源,并要求NM启动可以占用一定资源的任务,由于不同的AM被分布到不同的节点之上,因此他们互相之间是没有影响的。
以上基本就是对Yarn的发展和架构的一个回顾,现在进入正题,yarn的任务调度到底是怎么回事呢?
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组建构成;调度器(scheduler)和应用程序管理器(Applications Manager)ASM
而其中调度器负责的主要就是任务的调度,调度器是什么呢?以及作用有是什么呢?
调度器根据容量,队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统的资源分配到各个正在运行的应用程序。需要注意的时,该调度器是一个“纯调度器”,他将不再从事任何与应用程序相关的工作,比如不负责任务的监控或者跟踪应用的执行状态,也不负责重新启动因用用执行失败或硬件故障而产生的失败任务,这些均由应用程序对应的AM去完成,调度器仅根据各个应用程序的资源需求而进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container 简称Container)表示,Container是一个动态资源分配单元,他将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量,此外该调度器还是一个可插拔的组件,用户可根据自己的需求设计新的调度器,YARN提供了多种可以直接使用的调度器,比如FairScheduler和CapacityScheduler、FIFO等
FIFO;即先来先服务,在该调度机制下,所有的作业都被统一提交到一个队列中,hadoop按照提交顺序依次运行这些作业
但是,随着Hadoop的普及,单个Hadoop集群的用户量越来越大,不同用户提交的应用程序往往既有不同的服务质量要求,典型的有以下几种;
批处理作业;这种作业往往耗时较长,对时间完成一般没有严格要求,如数据挖掘,机器学习等方面的应用程序
交互式作业;这种作业期望能即时返回结果,如SQL查询(Hive)等;
生产性作业;这种作业要求有一定量的资源保证,如统计值计算等;
此时FIFO已经不能很又好的支撑各种不同类型的任务了,为了克服单队列FIFO调度器的不足,多种类型的多用户,多队列调度器诞生了,当前主要有两种多用户资源调度的设计思路,
第一种;在一个物理集群上虚拟多个Hadoop集群,这些集群各自拥有全套独立的Hadoop服务,典型的就是Hadoop on Demand(HOD)调度器;
第二种;扩展Hadoop的资源调度器,使之支持多个队列多个用户,这种调度器允许管理员按照应用需求对用户或应用程序进行分组,并为不同分组分配不同的资源量,同时通过添加各种约束,防止出现单个用户或者应用程序独占资源,进而能满足各种Qos的需求典型的代表就是CapacityScheduler和FairScheduler
我们这里主要讲述第二种,第一种我这里不多说因为在2.0的发行版中hadoop已经不再包含他了;
第二种方式式通过hadoop调度器将整个集群中 的资源划分给若干个队列,并让这些队列共享所有节点上的资源。
资源调度器作为YARN最核心的组件之一,且是插拔式的,他定义了一整套的接口规范以便用户可按照需要实现自己的调度器。YARN自带了FIFO Scheduler、Capacity Scheduler和Fair Scheduler三种常用的资源调度器,当然用户也可以按照接口规范自定义一个新的资源调度器,并通过简单的配置使他运行起来;
/**
* 开始初始化资源调度器
* @return
*/
protected ResourceScheduler createScheduler() {
/**
*下面的代码说明了目前YARN默认的资源调度器式 Capacity Scheduler
*
* 自定义需设置的参数;yarn.resourcemanager.scheduler.class
* 默认;org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
*/
String schedulerClassName = conf.get(YarnConfiguration.RM_SCHEDULER,
YarnConfiguration.DEFAULT_RM_SCHEDULER);
LOG.info("Using Scheduler: " + schedulerClassName);
try {
Class schedulerClazz = Class.forName(schedulerClassName);
if (ResourceScheduler.class.isAssignableFrom(schedulerClazz)) {
return (ResourceScheduler) ReflectionUtils.newInstance(schedulerClazz,
this.conf);
} else {所有资源调度器均应该实现接口
org.apache.hadoop.yarn.server.resourcemanager.scheduler.ResourceScheduler
该接口定义如下;
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.yarn.server.resourcemanager.scheduler;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience.LimitedPrivate;
import org.apache.hadoop.classification.InterfaceStability.Evolving;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.yarn.server.resourcemanager.RMContext;
import org.apache.hadoop.yarn.server.resourcemanager.recovery.Recoverable;
/**
* This interface is the one implemented by the schedulers. It mainly extends
* {@link YarnScheduler}.
*
*/
@LimitedPrivate("yarn")
@Evolving
public interface ResourceScheduler extends YarnScheduler, Recoverable {
/**
* Set RMContext for ResourceScheduler.
* This method should be called immediately after instantiating
* a scheduler once.
* @param rmContext created by ResourceManager
* 该方法应该在资源调度器被实例化之后立马调用
* 通常在Resource manager 初始化时调用
*/
void setRMContext(RMContext rmContext);
/**
* Re-initialize the ResourceScheduler.
* @param conf configuration
* @throws IOException
*
* 此方法发生在主备Resource mananger 切换的过程中
*/
void reinitialize(Configuration conf, RMContext rmContext) throws IOException;
}
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.yarn.server.resourcemanager.recovery;
import org.apache.hadoop.yarn.server.resourcemanager.recovery.RMStateStore.RMState;
public interface Recoverable {
/**
* Resource manager 重启后将调用该函数恢复调度器内部的信息
* @param state
* @throws Exception
*/
public void recover(RMState state) throws Exception;
}
/**
* This interface is used by the components to talk to the
* scheduler for allocating of resources, cleaning up resources.
*
*/
public interface YarnScheduler extends EventHandler {
/**
* 获取一个队列的基本信息,queueName是一个队列的名称,includeChildQueues是否包含子队列
* recursive表示是否递归返回其子队列的信息
* Get queue information
* @param queueName queue name
* @param includeChildQueues include child queues?
* @param recursive get children queues?
* @return queue information
* @throws IOException
*/
@Public
@Stable
public QueueInfo getQueueInfo(String queueName, boolean includeChildQueues,
boolean recursive) throws IOException;
/**
* 返回当前用户的队列ACL权限
* Get acls for queues for current user.
* @return acls for queues for current user
*/
@Public
@Stable
public List getQueueUserAclInfo();
/**
* 获取群集的整个资源容量
* Get the whole resource capacity of the cluster.
* @return the whole resource capacity of the cluster.
*/
@LimitedPrivate("yarn")
@Unstable
public Resource getClusterResource();
/**
* 返回调度器最少可分配的资源
* Get minimum allocatable {@link Resource}.
* @return minimum allocatable resource
*/
@Public
@Stable
public Resource getMinimumResourceCapability();
/**
* 返回调度器最多可分配的资源
* Get maximum allocatable {@link Resource}.
* @return maximum allocatable resource
*/
@Public
@Stable
public Resource getMaximumResourceCapability();
/**
* 返回当前集群中可用节点的个数
* Get the number of nodes available in the cluster.
* @return the number of available nodes.
*/
@Public
@Stable
public int getNumClusterNodes();
/**
* ApplicationMaster 和资源调度器之间最主要的API,ApplactionMaster通过该APi更新资源需求和待释放的Container列表
* The main api between the ApplicationMaster and the Scheduler.
* The ApplicationMaster is updating his future resource requirements
* and may release containers he doens't need.
*
* @param appAttemptId applacation Master的ia -》应用实例的
* @param ask 为新的请求资源的描述
* @param release 为待释放的Container列表
* @param blacklistAdditions 待加入黑名单的节点列表
* @param blacklistRemovals 待移除黑名单的节点列表
* @return the {@link Allocation} for the application
*/
@Public
@Stable
Allocation
allocate(ApplicationAttemptId appAttemptId,
List ask,
List release,
List blacklistAdditions,
List blacklistRemovals);
/**
*
* 获取节点资源使用情况报告
* Get node resource usage report.
* @param nodeId
* @return the {@link SchedulerNodeReport} for the node or null
* if nodeId does not point to a defined node.
*/
@LimitedPrivate("yarn")
@Stable
public SchedulerNodeReport getNodeReport(NodeId nodeId);
/**
* 获取运行实例ApplicationAttemptId的SchedulerAppReport对象
* Get the Scheduler app for a given app attempt Id.
* @param appAttemptId the id of the application attempt
* @return SchedulerApp for this given attempt.
*/
@LimitedPrivate("yarn")
@Stable
SchedulerAppReport getSchedulerAppInfo(ApplicationAttemptId appAttemptId);