STDN——新奇的特征图尺度变换法 (目标检测)(one-stage)(深度学习)(CVPR 2018)
论文名称:《 Scale-Transferrable Object Detection 》
论文下载:http://openaccess.thecvf.com/content_cvpr_2018/html/Zhou_Scale-Transferrable_Object_Detection_CVPR_2018_paper.html
论文代码:暂无
一、算法概述:
STDN(尺度转移检测网络)是一个类似于 SSD 的一阶段物体检测器。此网络用于提升多尺度目标的检测效果。要点包括:
(1)使用DenseNet-169作为基础网络提取特征(与SSD不同);
(2)使用尺度转移模块(STM)来获得不同分辨率的特征图,mean pooling 层和Scale-transfer Layer构成,在几乎不增加参数量和计算量的情况下生成大尺度的feature map。
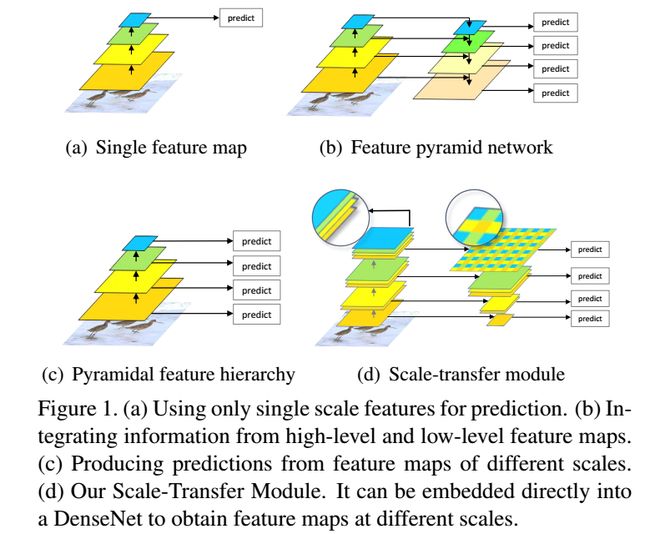
上图回顾了目标检测算法对feature map的利用情况:
(a)是只使用单一尺度的feature map进行检测,这种方法利用的特征层较少,检测效果一般,代表性的算法如Faster RCNN;
(b)是FPN的做法,将不同尺度的feature map自顶向下进行融合,并基于融合后的不同尺度的feature map分别进行检测,对小目标的检测效果提升明显,构建特征金字塔的方式可以充分利用多个层次的feature map信息,但是需要添加一些额外的网络层,增加了计算量和时间;
(c)是SSD算法的做法,对不同尺度的feature map分别检测,虽然浅层专用于小目标的目标检测,但是由于没有使用到高层的语义信息,所以对小目标的检测效果一般;
(d)是本文的做法,检测方式类似于SSD,但是通过基础网络DenseNet将高低层特征融合,因此可以达到类似FPN的效果。
二、算法亮点(STM = Mean Pooling + Scale-transfer Layer):
STM模块由池化层(Pooling)和尺度转换(scale-transfer)层组成,被嵌入到 DenseNet 网络的最后一个模块中,从而得到不同分辨率的被用来做物体检测的特征图。尺度转移层可以有效地减少输入特征图的通道数,同时扩大其分辨率,不增加额外的计算开销。Mean pooling 层用来获得低分辨率的特征图;Scale-transfer Layer通过压缩特征图的通道数来扩大特征图的分辨率,没有额外的计算开销。STM模块可以直接嵌入到 DenseNet 网络中,不需要在 DenseNet 网络之后添加额外的层就能获得多尺度的特征图。而且Scale-transfer Layer可以有效地压缩 DenseNet 网络特征图的通道数,从而减少之后卷积层的参数数量。作者在 pascal voc07 和 coco 数据集上取得了不错的检测性能,对构建开销较小的物体检测器具有一定的启发意义。
基础网络DenseNet-169最后一个block的尺寸为9*9,各层之间的通道数不同。为了获取不同尺度的特征map,作者将STM直接嵌入到DenseNet中,具体做法如下:
(1)Pooling用来获得小尺度的特征map;
(2)尺度转换层通过减少feature maps的通道个数获得大尺度的map,整个过程没有增加任何参数。
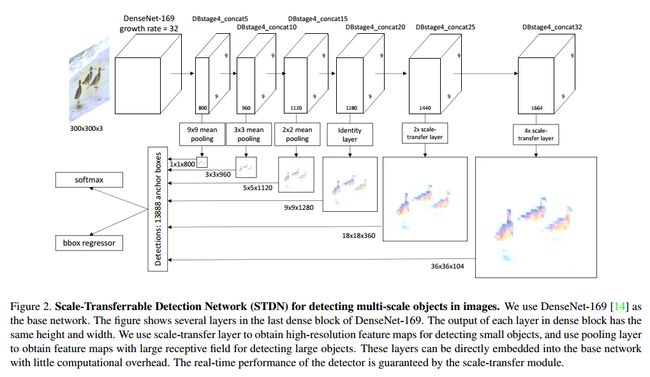
参考上图整体模型结构,对于(1)很好理解,即是一般池化过程获得较小分辨率的map;对于(2)则相当于增大的map尺寸而压缩了通道数。结合作者给出的一个示意图和网络模型的最后两层非常好理解。
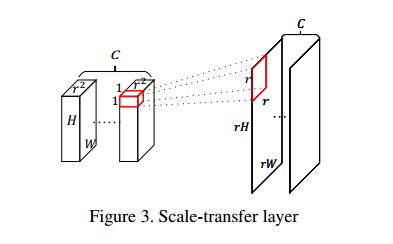
以网络的最后一个预测层为例,DenseNet-169的输出维度为9*9*1664,经过一个4X的scale-transfer后变为36*36*104。如作者所说,整个过程是像素值周期排列的过程,在此次变换中r=4,变换后的第一个通道上一个r*r像素块的像素值相当于是原来前r*r个通道上1*1的像素值的重新排列。在不增加任何参数的情况下完成了不同尺度特征的提取。
那么scale transfer layer 是怎么进行上采样的呢?从上图可以看出,对于H× W ×C · r2的feature map,根据channel,以r2 为一组,将其划分为C组,每一组都可以理解为是r2个H × W 的feature map,把同一组的H × W 的feature map上的同一位置的像素点组合到一起,也就是说把1*1*r2变成了r*r*1*1,那么一组feature map就变成了rh*rw,完成了上采样。算法和DUC很相似。
举个例子:输入维度是H*W*(C*r^2),输出维度是(r*H)*(r*W)*C,换句话说就是将C个三维的H*W*r^2变换成C个二维的(r*H)*(r*W)输出。假设输入是32*9*9*512,r=2,那么输出就是32*18*18*128,这里18是通过9*2得到的,128是通过512/(2*2)得到的。
此外,为什么要用最后一个densenet block呢?作者说明了网络的顶层具有高语义信息和低细节信息(也就是低分辨率吧)更有利于进行检测。
三、网络结构:
STDN也是采用SSD的架构,构造出6个不同resolution layer来进行detect。base ntework是densenet 169, 其网络结构移步这里。在每个densenet block里,每个layer的输出size是一样的,从图2中看出作者采用的是最后一个densenet block里的6层layer来生成6个不同resolution layer(对应于shicai densenet的concat 5_5,contact5_10,……)。对于low resolution lauer,直接采用mean pool来生成,对于high resloution layer ,采用作者提出的scale transfer layer 进行上采样,这样就能得到如图2所示的6个用于predict的不同resolution layer。
整体网络结构与SSD类似,提取DenseNet-169的最后一个Dense block中的6个concatenate层作为预测的特征层。与SSD直接利用VGG16后几层直接预测不同的是,STDNC则加入了独创的STM,在不增加任何参数和计算量的同时达到基于低分率特征map获得高分率特征map的目的,最终实现整体网络正确率和速度的提升。
四、实验结果:
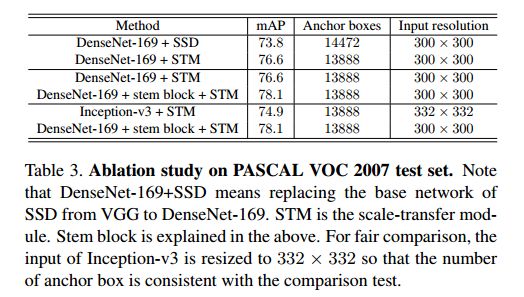
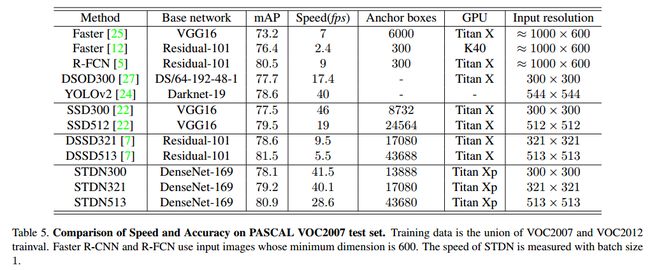
STDN在取得较高准确率的同时又兼顾了速度。例如STDN321和513两个模型相比于Faster-RCNN、YOLOv2、SSD、DSSD等,首先在正确率上已具有相同或者更高的水平,但是在速度上优势比较大。