TensorFlow框架做实时人脸识别小项目(二)
在第一部分中,分析了整个小项目的体系,重点讨论了用于人脸检测对齐的mtcnn网络的实现原理,并利用笔记本电脑自带的摄像头进行了测试。今天在这里要讨论的重点是人脸识别中的核心部分——facenet网络。
facenet是Google开源的人脸识别框架,它的作用是把输入的人脸图像映射为多维特征向量,相当于对不同的人脸进行了不同的编码,同一个人脸的图像生成的编码几乎一致,不同的人脸图像生成的编码差异非常大,并以此达到识别的目的。设计一个能够达到这样效果的映射的网络是一个很难的问题,我们下面就一步一步来看facenet是怎样解决这个问题的。
首先,facenet的结构是这样的:
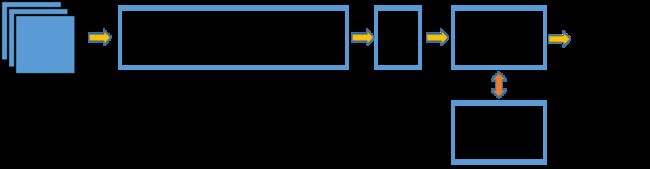
facenet网络的输入有多种不同的大小,中间部分是一个深度卷积神经网络,与其他普通CNN没有多大区别。facenet不一样的地方在于后面部分,它对深度卷积神经网络的输出做了一个L2正则化,然后再对输出进行了embedding,直接将embedding的映射结果作为特征向量输出。facenet并没有像其他一般的CNN用softmax作为损失函数,而是设计了一种新的损失——triplet loss。
在理想的情况下,特征向量之间的距离可以直接反映人脸的相似度,即:
- 对于同一个人的两张人脸图像,对应的向量之间的欧几里得距离比较小
- 对于不同人的两张图像,对应的向量之间的欧几里得距离比较大
假设人脸图像为x1和x2,对应的特征为f(x1)和f(x2)。当x1和x2对应的是同一个人脸时,其距离II f(x1)-f(x2) II应该很小,而当x1和x2对应的是不同的人脸时,其距离II f(x1)-f(x2) II应该很大。
然而事实并非如此。在一般CNN网络中,最后的输出经过softmax分类器,使用的是softmax损失。这个损失是不同类别间的损失。对于人脸来说,每一个人脸就是一个人。看起来似乎很合理,但是用softmax表示损失,以此区别出不同的人是不可行的。softmax本质上没有对每一类的向量表示之间的距离做出要求。用softmax分类的结果,可能同一个类中的向量,它的类间距比不同类中的向量间距还要大。对于这种情况,就要考虑设计新的损失函数解决问题。
下面重点看triplet loss的定义及原理
三元组损失(triplet loss)的原理:既然目标是特征之间的距离应当具备某些性质,那么就围绕这个距离来设计损失。具体的,每次都在训练数据中取出三张人脸图像,第一张图像记为![]() ,第二张图像记为
,第二张图像记为![]() ,第三张图像记为
,第三张图像记为![]() 。在这样一个三元组中,
。在这样一个三元组中,![]() 和
和![]() 对应的是同一个人,
对应的是同一个人,![]() 是另外一个不同的人。因此,距离
是另外一个不同的人。因此,距离![]() 应该比较小,而距离
应该比较小,而距离![]() 应该较大。那么严格的就有以下式子:
应该较大。那么严格的就有以下式子:
![]()
即相同人脸距离平方至少要比不同人脸的距离平方小![]() 。
。
那么损失函数就设计为:![]()
三元组损失直接对距离进行优化,因此可以解决人脸的特征表示问题。
PS:另一种损失:中心损失(center loss)
中心损失的定义:中心损失不对距离进行优化,它保留了原有的分类模型,但又为每一个类指定了一个类别中心。同一个类的图像对应的特征应该尽量靠近自己的类别中心,不同的类别中心尽量远离。
输入的人脸图像为![]() ,该人脸的类别为
,该人脸的类别为![]() ,对每一个类别都规定一个类别中心
,对每一个类别都规定一个类别中心![]() 。希望每个人脸对应的特征
。希望每个人脸对应的特征![]() 都尽可能的接近其中心
都尽可能的接近其中心![]() ,因此中心损失定义为:
,因此中心损失定义为:
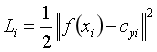
多张图像的中心损失就是将单张图像的损失相加:
此外,不能只使用中心损失来训练分类模型,还需要加入softmax损失,也就是说,最终的损失由两部分构成,即![]() ,其中的
,其中的![]() 是一个超参数。
是一个超参数。
facenet中的triplet loss定义:
def triplet_loss(anchor, positive, negative, alpha):
"""
参数说明:
anchor: the embeddings for the anchor images.
positive: the embeddings for the positive images.
negative: the embeddings for the negative images.
"""
with tf.variable_scope('triplet_loss'):
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, positive)), 1)
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, negative)), 1)
basic_loss = tf.add(tf.subtract(pos_dist,neg_dist), alpha)
loss = tf.reduce_mean(tf.maximum(basic_loss, 0.0), 0)facenet中的center loss定义:
def center_loss(features, label, alfa, nrof_classes):
nrof_features = features.get_shape()[1]
centers = tf.get_variable('centers', [nrof_classes, nrof_features], dtype=tf.float32,initializer=tf.constant_initializer(0), trainable=False)
label = tf.reshape(label, [-1])
centers_batch = tf.gather(centers, label)
diff = (1 - alfa) * (centers_batch - features)
centers = tf.scatter_sub(centers, label, diff)
loss = tf.reduce_mean(tf.square(features - centers_batch))
return loss, centers同样,facenet网络中的参数需要百万级的人脸数据进行训练,才能达到很好的embedding效果。
github上facenet项目的作者David Sandberg,已经通过几个不同的大型人脸数据集进行预训练,得到了效果很好的facenet网络模型如下:
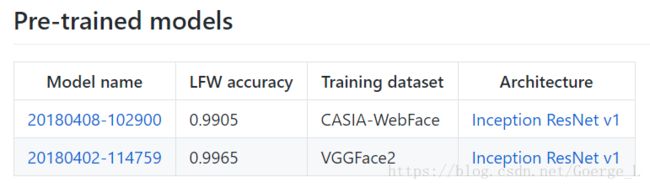
这个模型是放在谷歌云盘上的,国内的网络无法下载,这里有我下载过来的文件提供给有需要的小伙伴,在这里。
使用这个预训练的facenet网络,首先载入模型,然后向模型中喂入用mtcnn检测对齐好的人脸crop。实现的部分代码如下:
def embed_image(crop):
facenet.load_model('./20180408-102900/20180408-102900.pb')
tf.Graph().as_default()
sess = tf.Session()
# Get input and output tensors
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
# Run forward pass to calculate embeddings
#emb_array = np.zeros((160, embedding_size))
feed_dict = {images_placeholder: crop, phase_train_placeholder: False}
emb_array = sess.run(embeddings, feed_dict=feed_dict)
print('embedding:{}'.format(emb_array.shape))
return emb_array