Hive 内置函数及自定义函数
1.内置函数
使用如下命令查看当前hive版本支持的所有内置函数
show functions;部分截图:
可以使用如下命令查看某个函数的使用方法及作用,比如查看 upper函数
desc function upper;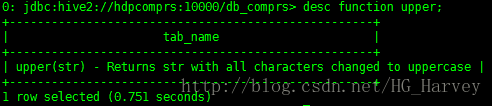
如果想要查看更为详细的信息加上extended参数
desc function extended upper;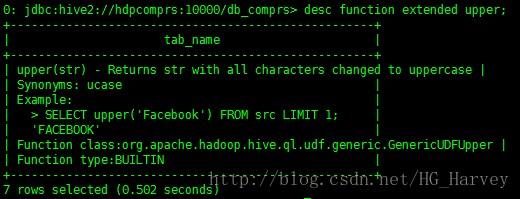
内置函数使用
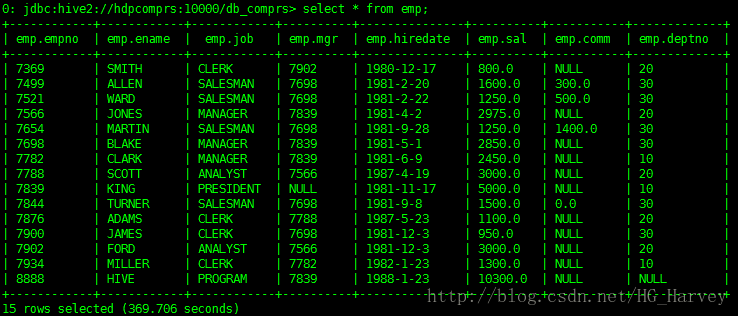
员工表emp,数据如下
- lower():转换为小写
查询emp表中员工姓名,员工姓名小写显示
select empno,ename,lower(ename) from emp;
- 字符串连接:concat()
查询emp表,将员工姓名追加到员工编号后
select empno,ename,concat(empno,ename) from emp;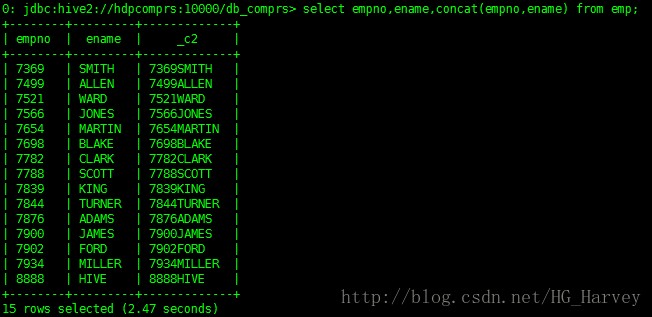
hive中的内置有很多,在这笔者就不再一一介绍,如果在使用过程中遇到问题可以使用命令来查看该函数的使用方法及作用,或查看官方使用文档:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
2.自定义函数
虽然hive中为我们提供了很多的内置函数,但是在实际工作中,有些情况下hive提供的内置函数无法满足我们的需求,就需要我们自己来手动编写,所以就有了自定义函数 UDF。
UDF分为三种,分别如下
(1).UDF(User-Defined-Function),一进一出(输入一行,输出一行),比如:upper()、lowser()等。
(2).UDAF(User-Defined Aggregation Funcation),多进一出(输入多行,输出一行),比如:avg()、sum()等。
(3).UDTF(User-Defined Table-Generating Functions),一进多出(输入一行,输出多行),比如:collect_set()、collect_list()等。
官方文档:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
使用自定义函数需要引入hive-exec的依赖
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>2.3.0version>
dependency>1.自定义UDF函数
UDF编程模型:
(1).继承 org.apache.hadoop.hive.ql.exec.UDF
(2).实现 evaluate() 方法
实现需求:自定义UDF函数,给指定的字符串前加上字符串hello:
比如:输入zhangsan,输出hello:zhangsan
代码:
package com.bigdata.hadoop.hive;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
/**
* 自定义UDF函数
* 输入:Tom
* 输出:hello:Tom
*/
@Description(
name = "say_hello,ucase",
value = "_FUNC_(str) - Returns str start with hello:",
extended = "Example:\n > SELECT _FUNC_(\'Facebook\') FROM src LIMIT 1;\n \'hello:Facebook\'"
)
public class GenericUDFHello extends UDF {
public String evaluate (final Text s){
if (s == null) {
return null;
}
return "hello:" + s.toString();
}
public static void main(String[] args) {
System.out.println(new GenericUDFHello().evaluate(new Text("Tom")));
}
}自定义函数有4种使用方式,下面笔者分别来介绍
- 方式一(临时函数,只能在当前客户端使用)
将我们刚刚编写完成的代码,打成jar
将jar包上传到hive
add jar /home/hadoop/libs/hive-1.0-SNAPSHOT.jar;创建函数
create temporary function say_hello as 'com.bigdata.hadoop.hive.GenericUDFHello';查看创建的函数say_hello
show functions;
查看函数say_hello的详细信息
desc function extended say_hello;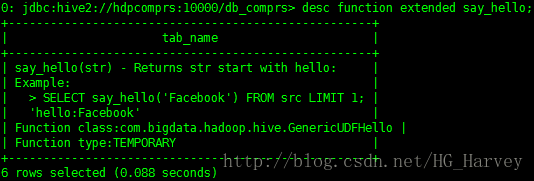
使用函数
select ename,say_hello(ename) from emp;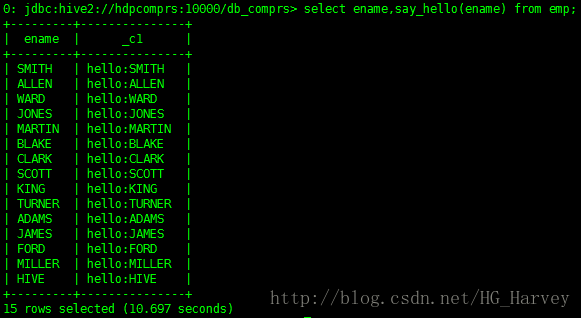
- 方式二(临时函数,只能在当前客户端使用)
在$HIVE_HOME下新建目录auxlib,将jar拷贝到该目录下,重启hadoop
$ cd $HIVE_HOME
$ mkdir auxlib
$ cd auxlib/
$ cp /home/hadoop/libs/hive-1.0-SNAPSHOT.jar .创建函数say_hello2
create temporary function say_hello2 as 'com.bigdata.hadoop.hive.GenericUDFHello';查看创建的函数,同上
使用函数,效果同上
select ename,say_hello2(ename) from emp;- 方式三(永久函数,创建后可以在任意客户端使用,建议使用)
上传jar到hdfs
$ hadoop fs -put hive-1.0-SNAPSHOT.jar /libs创建函数 say_hello3
create function say_hello3 as 'com.bigdata.hadoop.hive.GenericUDFHello' using jar 'hdfs://hdpcomprs:9000/libs/hive-1.0-SNAPSHOT.jar';注意:创建完function之后,通过show functions并没有看到我们自定义的函数say_hello3,但是可以使用
使用函数,效果同上
select ename,say_hello3(ename) from emp;- 方式四(永久函数,将自定义函数集成到hive源码中)
使用这种方式需要修改hive的源代码,集成到hive源码后,hive启动后就可以使用,不用再向hive中注册函数,相当于一个hive的内置函数。如果公司有自己的大数据框架版本,建议使用这种方式。
从官网下载hive源码,笔者使用的版本为2.3.0,http://apache.fayea.com/hive/
下载后解压
$ tar -zxvf apache-hive-2.3.0-src.tar.gz将自定义UDF函数继承到Hive源码中,需要如下三个步骤
(1).上传文件
把GenericUDFHello.java类上传到如下目录,并修改包名
$ cd apache-hive-2.3.0-src/ql/src/java/org/apache/hadoop/hive/ql/udf
$ rz
$ vim GenericUDFHello.java
package org.apache.hadoop.hive.ql.udf;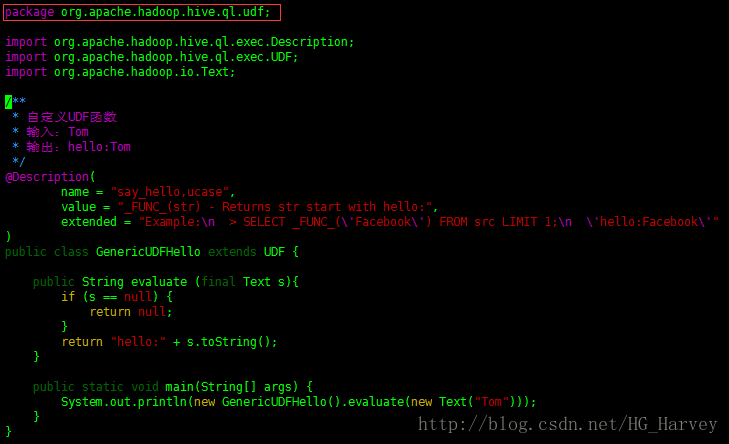
(2).配置FunctionRegistry类
hive 中有一个非常重要的类FunctionRegistry,我们需要将自己自定义的函数在这个类中配置,引入我们自定义函数类GenericUDFHello
$ cd apache-hive-2.3.0-src/ql/src/java/org/apache/hadoop/hive/ql/exec
$ vim FunctionRegistry.java
import org.apache.hadoop.hive.ql.udf.GenericUDFHello;注册自定义函数类GenericUDFHello,输入static { 搜索,在静态代码块中注册我们编写的自定义函数,这里面都是hive的所有内置函数,添加如下代码
system.registerUDF("hello", GenericUDFHello.class, false);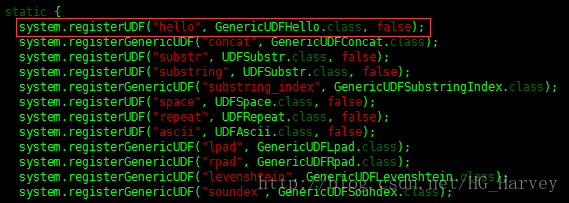
(3).编译 Hive 源码
$ cd apache-hive-2.3.0-src
$ mvn clean package -Phadoop-2,dist -DskipTests
-Phadoop-2表示使用的hadoop版本为2,如果为1,则写-Phadoop-1编译过程教程,请耐心等待,编译完成后,hive会生成一个压缩包,解压配置后就可以使用,hive压缩包存放的路径是apache-hive-2.3.0-src/packaging/target
使用函数hello(效果同上)
select empno,ename,hello(ename) from emp;如果你在编译Hive的源码时,遇到错误,可以参考博客:
http://blog.csdn.net/HG_Harvey/article/details/77806542
2.自定义UDAF函数
UDAF编程模型
(1).继承 org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
(2).实现 evaluate() 方法
(3).编写静态内部类(函数的计算逻辑),继承GenericUDAFEvaluator,必须重写如下方法
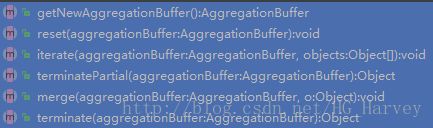
UDAF同样有四种使用方式(参照自定义函数UDF中的介绍)
实现需求:计算表中某列字母的个数
代码:
package com.bigdata.hadoop.hive;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
/**
* 自定义UDAF函数
* 计算表中某列字母的个数
*/
@Description(
name = "numofletters",
value = "_FUNC_(x) - Returns the total number of characters of all the strings in that column"
)
public class GenericUDAFTotalNumOfLetters extends AbstractGenericUDAFResolver {
// 返回聚合函数在经过map combiner reduce 的阶段时使用的计算器
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
return new TotalNumOfLettersEvaluator();
}
// 静态内部类,聚合函数的计算逻辑
public static class TotalNumOfLettersEvaluator extends GenericUDAFEvaluator{
//两个输入类型一个输出类型
ObjectInspector out;
PrimitiveObjectInspector text,num;
// map combiner reduce 的阶段都会执行的方法
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m, parameters);// 注释掉则整个程序将无法执行
// 表示正在执行 map 阶段
if(m == Mode.PARTIAL1 || m==Mode.COMPLETE){
//保存计算map输入的数据类型,即sql类型
text= (PrimitiveObjectInspector) parameters[0];
}else { //表示正在执行 combiner 或者 reduce
//保存计算的 combiner 或者 reduce 阶段的输入数据类型
num = (PrimitiveObjectInspector) parameters[0];
}
out= ObjectInspectorFactory.getReflectionObjectInspector(Integer.class,
ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
return out;
}
// 会根据mode决定调用merge还是iterate
@Override
public void aggregate(AggregationBuffer agg, Object[] parameters) throws HiveException {
super.aggregate(agg, parameters);
}
// 保存当前字符总数的静态内部类
static class LetterSumAgg implements AggregationBuffer{
int sum;
public void add(int num){
sum+=num;
}
}
//计算器在阶段处理中用来获取一个新的中间存储对象
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
LetterSumAgg letterSumAgg = new LetterSumAgg();
return letterSumAgg;
}
// 重置阶段中存储的数据,清除
public void reset(AggregationBuffer aggregationBuffer) throws HiveException {
LetterSumAgg letterSumAgg = new LetterSumAgg();
}
// map计算阶段迭代统计字符个数
public void iterate(AggregationBuffer aggregationBuffer, Object[] parameters) throws HiveException {
if (parameters[0] != null) {
LetterSumAgg letterSumAgg = (LetterSumAgg) aggregationBuffer;
Object p1 = text.getPrimitiveJavaObject(parameters[0]);
letterSumAgg.add(String.valueOf(p1).length());
}
}
// 返回一个map或combiner阶段计算器统计的结果,即map或combiner的输出
public Object terminatePartial(AggregationBuffer aggregationBuffer) throws HiveException {
return ((LetterSumAgg)aggregationBuffer).sum;
}
// 计算器在被combiner或者reduce阶段执行时调用,合并之前阶段的部分统计结果
public void merge(AggregationBuffer aggregationBuffer, Object partial) throws HiveException {
if (partial != null) {
LetterSumAgg letterSumAgg = (LetterSumAgg) aggregationBuffer;
Integer partialSum = (Integer) num.getPrimitiveJavaObject(partial);
letterSumAgg.add(partialSum);
}
}
// 计算器在被reduce阶段执行时调用,合并之前阶段的部分统计结果,最终返回确定的结果输出
public Object terminate(AggregationBuffer aggregationBuffer) throws HiveException {
return ((LetterSumAgg) aggregationBuffer).sum;
}
}
}上传jar到hive
add jar /home/hadoop/libs/hive-1.0-SNAPSHOT.jar;创建临时函数
create function numofletters as 'com.bigdata.hadoop.hive.GenericUDAFTotalNumOfLetters';查看创建的临时函数
show functions;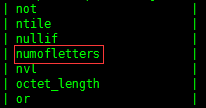
查看函数的详细信息
desc function numofletters;
使用函数
tb_test 表中数据如下
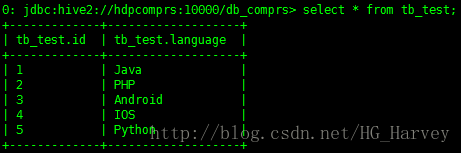
计算emp表中ename列字母个数(会执行mapreduce作业)
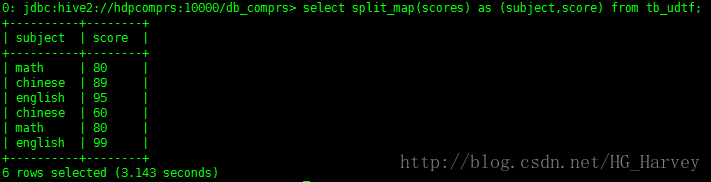
select numofletters(language) from tb_test;
3.自定义UDTF函数
(1).继承 org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
(2).实现三个方法 initialize()、process()、close()
UDTF也有四种使用方式(参照自定义函数UDF中的介绍)
实现需求:切分map
输入:key1:value1;key2:value2;
输出:key1 value1 key2 value2
代码:
package com.bigdata.hadoop.hive;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
/**
* 自定义UDTF函数
* 切分map
* 输入:math:80;chinese:89;english:95;
* 输出:math,80 chinese,89 english,95
*/
@Description(
name = "split_map",
value = "_FUNC_(x) - input key1:value1;key2:value2; output key1,value1 key2,value2"
)
public class GenericUDTFSplitMap extends GenericUDTF {
// 初始化校验参数是否正确
@Override
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
if (args.length != 1) {
throw new UDFArgumentLengthException("ExplodeMap takes only one argument");
}
if (args[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("ExplodeMap takes string as a parameter");
}
ArrayList fieldNames = new ArrayList();
ArrayList fieldOIs = new ArrayList();
fieldNames.add("col1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("col2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);
}
// 函数逻辑处理,并将结果返回(forward)
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
// 按分号分隔
String[] strings = input.split(";");
for(int i=0; i
try {
// 按冒号分隔
String[] result = strings[i].split(":");
forward(result);
} catch (Exception e) {
continue;
}
}
}
// 对需要清理的方法进行清理
@Override
public void close() throws HiveException {
}
} 上传jar到hive中
add jar /home/hadoop/libs/hive-1.0-SNAPSHOT.jar;创建函数
create function split_map as 'com.bigdata.hadoop.hive.GenericUDTFSplitMap';使用函数
tb_udtf表中数据如下
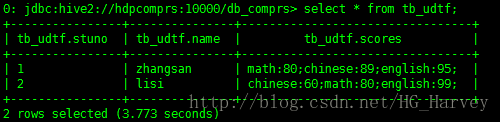
select split_map(scores) as (subject,score) from tb_udtf;