引言观点
1. 编程语言日新月异,但是从没有人否定sql 在现代编程中的巨大作用和 持续的可利用性。SQL以对人类友好的阅读体验提供数据查询能力( 相比其他编程语言 ), 同时在各种数据库平台中,基础SQL元素是相同或大同小异的,
从我们最早接触的SQL,Mysql到公司大数据impala 支持SQL, Es也提供类似SQL的查询, 阿里提出SQLFlow AI框架, SQL的生命力极其顽强。
2. 在我近6年的开发生涯中,确实觉得SQL语言没有得到开发者足够的重视,尤其是流行的ORM概念使得了编写SQL机会越来越少,使用ORM映射框架是需要一些代码的, 另外ORM只能用于基础的关系型二维查询,对于复杂的查询无能为力,部分工作可通过巧妙的SQL查询,存储过程,触发器来完成。
3. SQL编程有许多独特之处: 面向集合的思维方式、 查询元素的逻辑处理顺序、三值逻辑(three value logic),理解不透的话在实际编写SQL时会产生很多错误的写法、性能低下的代码。
1987年SQL称为ISO标准,ANSI宣布该语言发音为“ess kyoo ell”, 但由于历史原因,很多专业人士还是将SQL发音成sequel,而且从英文习惯上,sequel发音更为流畅。 互联网如此之大,容得下不同的声音。
-
SQL逻辑查询处理
-
SQL 面向集合的思维方式
SQL逻辑查询处理
开发者、数据分析师每天都在写【SELECT 列a,聚合函数 FROM 表名 WHERE 过滤条件 GROUP BY 列a HAVING 筛选条件】这样的查询语句。
SQL与其他语言不同的最明显特征是代码的处理顺序,大多数编程语言中,代码是按照编写顺序来处理的,但在SQL中第一个要处理的子句是FROM子句,尽管SELECT语句第一个出现,但基本都在最后处理。
每一步都会生成一个虚拟表,该虚拟表会作为下一步的输入, 这些虚拟表对于调用者(客户端应用程序或者外部查询)都是不可用的,只有最后一步生成的虚拟表才会返回给调用者,这种形态可对比LINQ理解。
①FROM FROM阶段负责标识表或要查询的表,如果指定了表运算符(JOIN, APPLY,PIVOT,UNPIVOT ),还要进行表运算符的处理。
例如:表联接运算中涉及的阶段是 笛卡尔积、ON筛选器和 添加外部行,FROM阶段生成虚拟表VT1.
②WHERE 这个阶段根据在WHERE子句中出现的谓词对VT1中进行筛选,只有让谓词计算结果为TRUE的行,才会插入VT2中。
③GROUP BY 按照GROUP BY 子句中指定的列名列表,对VT2中的行进行分组,生成VT3, 最终每个分组只有一个结果行。
④HAVING 根据HAVING子句中出现的谓词,对VT3中行记录进行筛选,只有让谓词结果为TRUE的行记录,才会进入VT4, Having 筛选器是唯一可用于分组数据的筛选器。
⑤SELECT 处理SELECT子句中字段(某些字段可能进行一些操作,形成新的字段),形成虚拟表VT5
⑥ORDER BY 根据ORDER BY子句中指定的列名列表,对VT5 中行进行排序,输出最后结果。
-
第一步的FROM表运算, 一般情况下是TABLE、TempTable,CTE, 还有可能是表运算符(我们常用的是联接运算符), 所以不能单纯认为FROM后面是一个表结构。
-
表联接运算符 ON筛选器 与 WHERE有所不同,若采用OUTER JOIN, 应用ON筛选出来的结果不一定是此阶段最终结果,因为涉及【添加外部行】, 而WHERE过滤出的结果是此阶段的最终结果。
-
GROUP BY x,y 意味着将(x,y)作为一个整体来分组
-
有SELECT 和WHERE的时候,先执行WHERE,再执行SELECT,这样就很容易理解以下SQL的业务含义:
SELECT page_original_url,server_session_id,access_order-1 as access_order FROM PageViewMeasure WHERE access_order >= 2 --- 查询过滤出access_order>=2的基础数据集,然后将(原列值-1)重命名为原列名,重命名的用法业务上也许是为了形成新的SQL联接 SELECT keyword_id,Coalesce(full_keywords,keywords) as not_nullField,profile_id,session_server_time,count (*) over () as Count FROM pageview WHERE profile_id =5254 and keyword_id != '-' and day =20181008 and not_nullField !='-' ORDER BY session_server_time --- SQL报错:Could not resolve column/field reference: 'not_nullfield' 也容易理解了:先执行where, 执行where的时候not_nullField字段还没有形成
-
ROW_NUMBER() OVER(PARTITION BY UserId ORDER BY PageViewServerTime)排名函数中ORDER BY 与SQL语句最后的ORDER BY 同时存在,哪个ORDER BY起最终排序作用?
SELECT page_original_url as name,page_view_server_time, ROW_NUMBER() OVER(PARTITION BY page_original_url ORDER BY page_view_server_time ) as partition_rank ,wd3_page_duration FROM pageview WHERE profile_id=5198 AND day between 20190616 and 20190621 ORDER BY wd3_page_duration desc LIMIT 100
可以认为 ROW_NUMBER() OVER(PARTITION BY col1 ORDER BY col2) as rank 本质上还是产生一个列值,实际是对应以上的第⑤步,因此SQL最后的ORDER BY起最终排序作用,例证如下:

某些转载文章写有: 以上over函数里的分组及排序的执行晚于“where,group by,order by”的执行 ,这样的结论是错误的
-
若存在LIMIT子句,则LIMIT子句必须在ORDER BY 语法之后
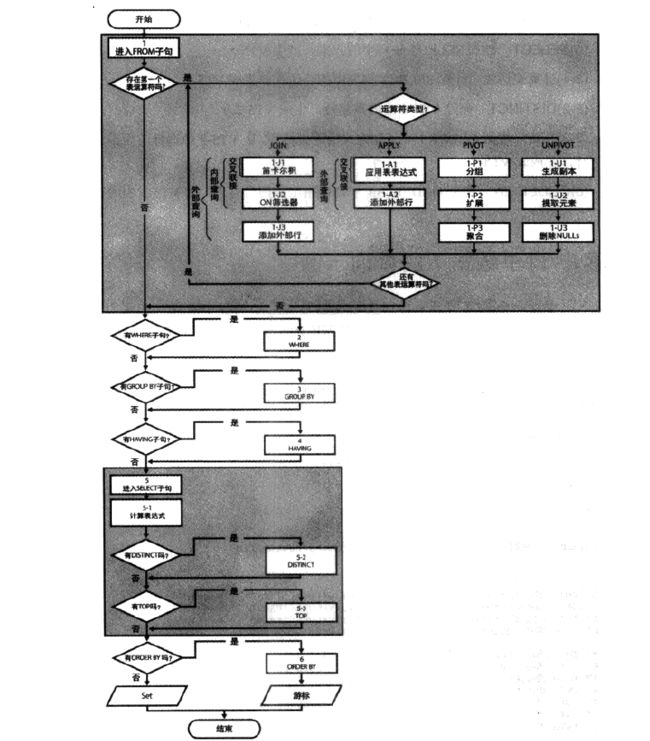
上图来自《SQL技术内幕T-SQL查询》逻辑查询处理一章
 这里抛出一个困惑点:
这里抛出一个困惑点:
在FROM子句中,若存在JOIN表运算符, 可能会按照 【计算笛卡尔积】 【应用ON筛选】【添加外部行】的顺序来完成 JOIN的过程, 但是试想一下: 如果两个表都为大表,先计算笛卡尔积,再筛选 岂不很费内存,
我也搜索了很多资料,某些资料认为先进行【ON筛选】再进行【JOIN】运算:
https://www.cnblogs.com/liuzhendong/archive/2011/10/27/2226805.html
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/ms189499(v=sql.100)
我更愿意相信《SQL技术内幕T-SQL查询》书中所言:
本章描述的某些逻辑处理步骤可能看起来非常低效,但要记住, 在实践中, 查询的实际物理处理可能与逻辑处理有很大不同。在SQL Server 中负责生成实际工作计划的组件是查询优化器,以何种顺序访问表、使用什么访问方法和索引,应用哪种联接算法等都是查询优化器来决定的,优化器会生成多个有效执行计划并选择一个开销最低的计划。
逻辑查询处理中各个阶段都有其特定的顺序,而优化器缺经常可以在它生成的物理执行计划中走捷径。
我们思考一个简单的SQL:
SELECT * FROM pageview LEFT JOIN share ON pageview.share_pv_id = share.page_view_id WHERE pageview.profile_id =5313 AND pageview.day between 20190615 and 20190624
若实际物理查询按照上面描述的 逻辑查询处理, 先进行 FROM 子句中的 LEFT JOIN 计算,再进行 WHERE过滤, 根本无法查出(在FROM子句可能内存就爆满了)
现在我们能够查询出来,能够印证 实际物理查询确实与逻辑查询处理有很大不同。
PS: 以上是个人从现象上推断书中理论,对于实际物理查询处理并没有理论支持,若网友们有相关资料,可留言给我。
码甲拙见,如有问题请下方留言大胆斧正;码字+Visio制图,均为原创,看官请不吝好评+关注, ~。。~
本文欢迎转载,请转载页面明显位置注明原作者及原文链接。